基于机器阅读理解(MRC)的信息抽取方法

导读:本次分享的主题为基于机器学习阅读理解(MRC)的信息抽取方法。由香侬科技发表在ACL2019,论文提出用阅读理解的方法对信息抽取这个传统问题进行建模,取得了比较好的效果。
▌Part1 香侬科技简介
香侬科技的主要研究方向为自然语言处理和深度学习,秉承“让机器读懂纷繁的大千世界”为使命,致力于用人工智能技术消除信息不对称的壁垒,让所有人都能平等获取信息。目前主要业务包括信息抽取、智能文档解析、智能数据聚类分析、文本对比审核等。
▌Part2 自然语言处理(NLP)
1. 自然语言处理(NLP)是什么?
自然语言处理是研究能实现人与计算机之间,用自然语言进行有效通信的各种理论和方法。(通俗讲就是计算机要理解人说的话,计算机生成的话,人也能够理解)

2. 为什么自然语言处理很难?
自然语言处理的难点在于歧义性。如下面的例子:
同样的表达方式,有不同的含义:
“喜欢一个人”:like someone 或者 like to be alone。
虽然表达方式不同,但表达的含义相同:
“我刚差点摔着”、“我刚差点没摔着”
“苹果多少钱一斤”、“苹果一斤多少钱”、“一斤苹果多少钱”
3. 常见的NLP任务
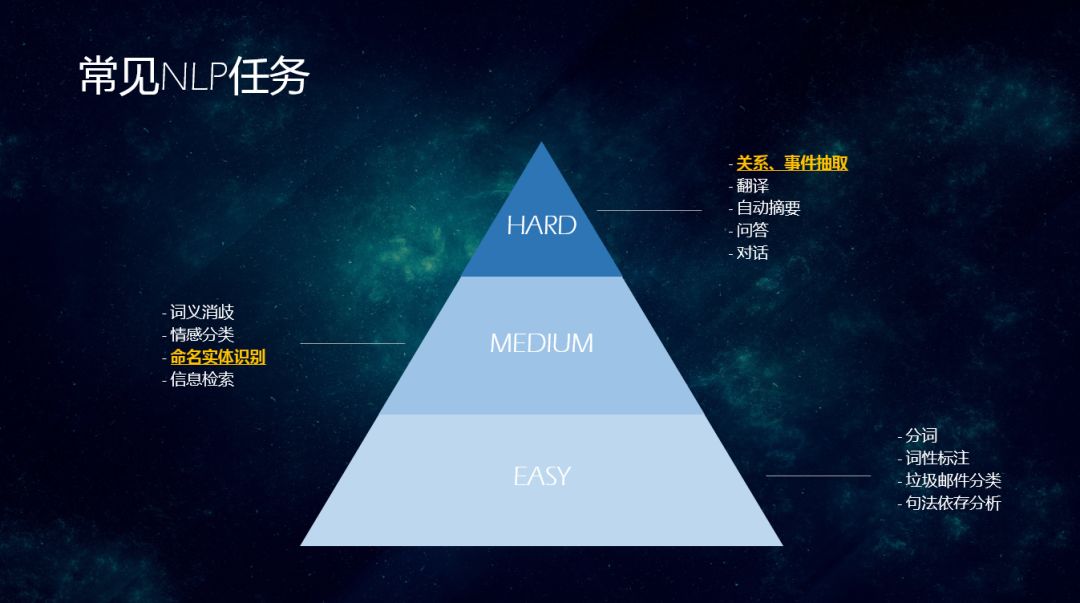
常见的NLP任务可以分为简单、中等、困难,分别包含的具体任务如下:
简单任务:分词、词性标注、垃圾邮件分类、句法依存分析
中等任务:词义消歧、情感分类、命名实体识别、信息检索
困难任务:关系&事件抽取、翻译、自动摘要、问答、对话
今天主要介绍命名实体识别、关系&事件抽取这两类信息抽取任务。
4. 深度学习与NLP结合的范式:
范式1:
第一种深度学习与 NLP 的结合的范式(Bert出现之前),一般包含以下几步:
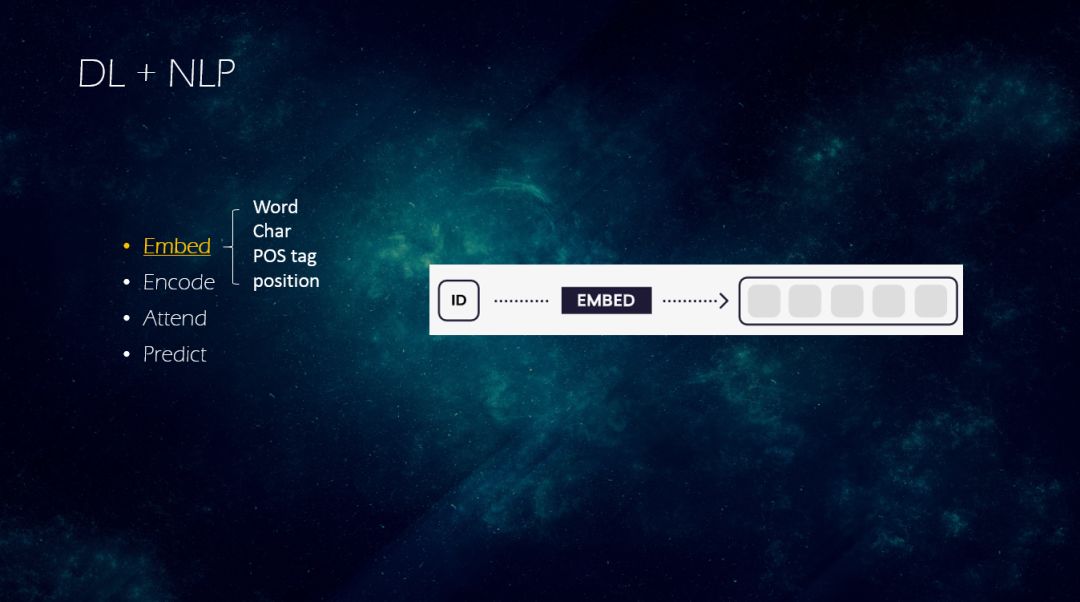
-> Embed:该阶段把离散id变成稠密向量,可能对以下几个维度特征进行embedding,包括word(单词)、char(字符)、pos tag(词性)、position(位 置)。
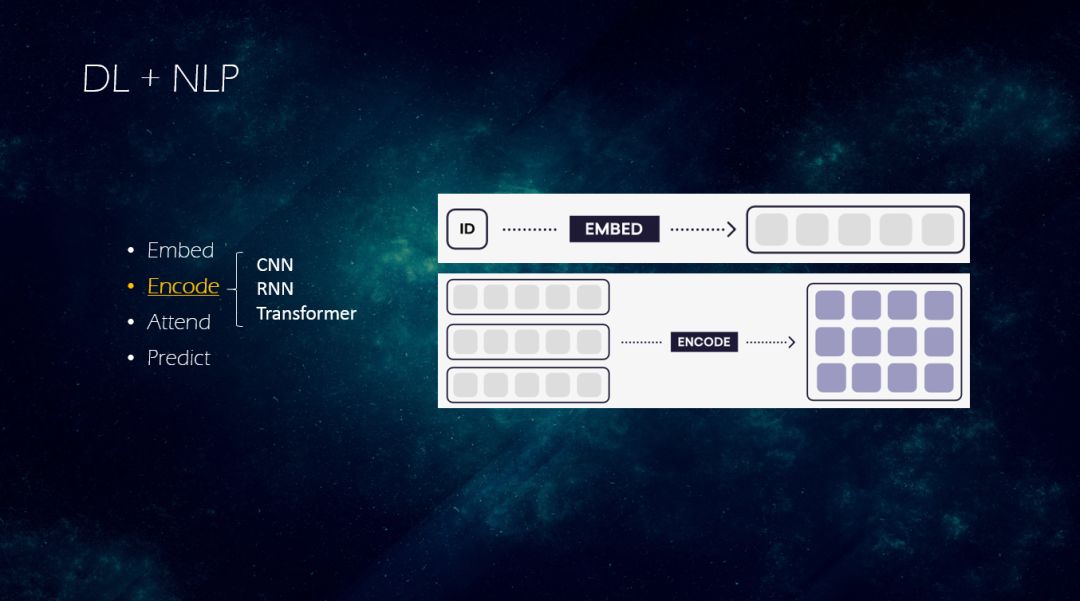
-> Encode:该阶段使得稠密向量获得上下文信息, 一般方案包括CNN/RNN/Transformer。
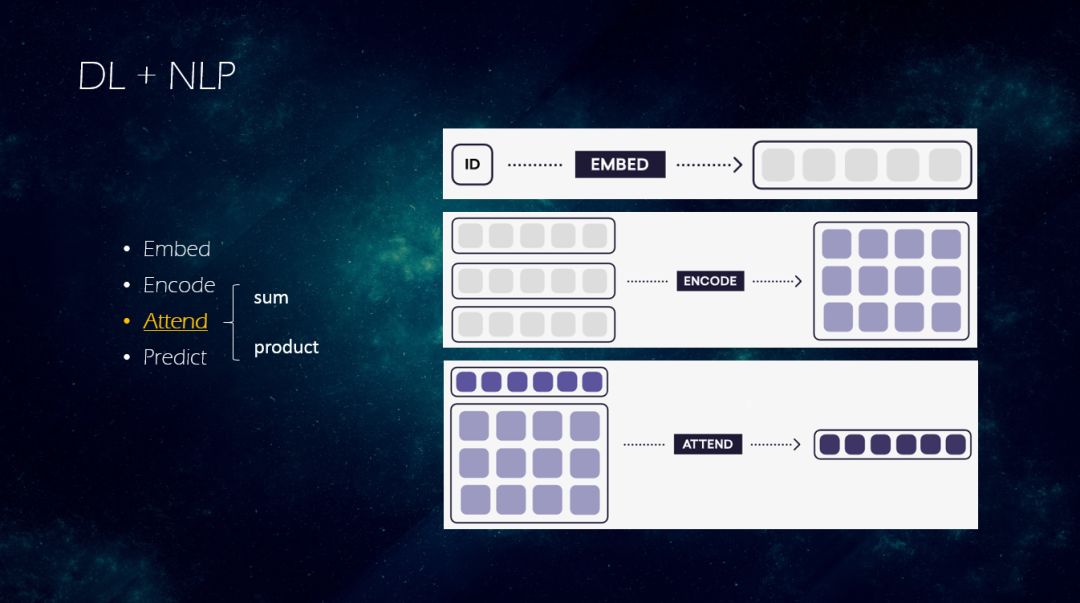
-> Attend:该阶段可以使更远的信息可以互相注意,一般分为加性(sum)、乘性(product)的注意力机制。
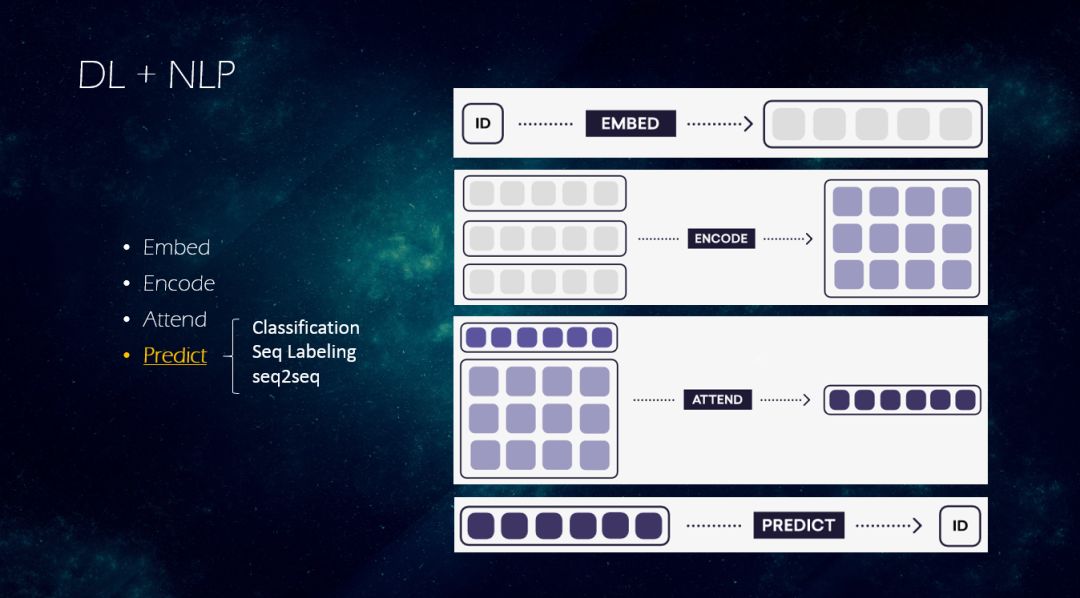
-> Predict:NLP 任务一般是预测离散的变量,Classification分类、SeqLabeling序列标注、翻译/摘要可以model成seq2seq的任务。
范式2:
最近有些Pre-train的模型出现,打破的了之前的方案,把embed到Attend,基本上都用的类似的方法,通过Pre-train得到一个带着上下文信息的向量。算法包括elmo、gpt、bert、gpt2、xlnet、ernie、roberta等,在大数据量上进行预训练。
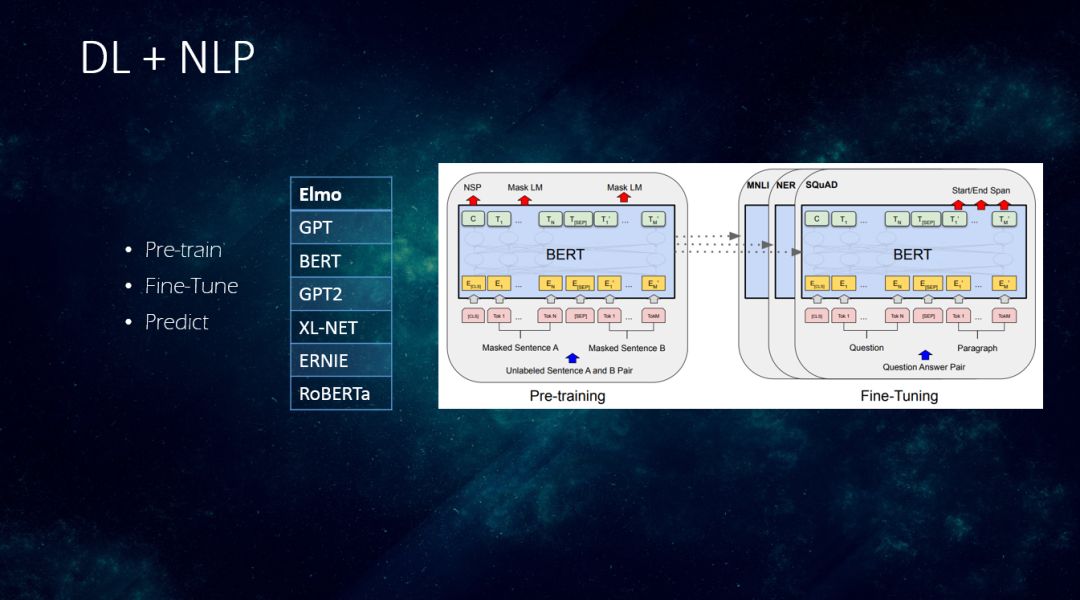
第二种深度学习与 NLP 的结合的范式,一般包含以下几步:
-> Pre-train:刚开始是用大规模的语料进行预训练。
-> Fine_tune:针对特定任务进行微调。
-> Predict:进行Predict。
▌Part3 信息抽取
1. 信息抽取简介
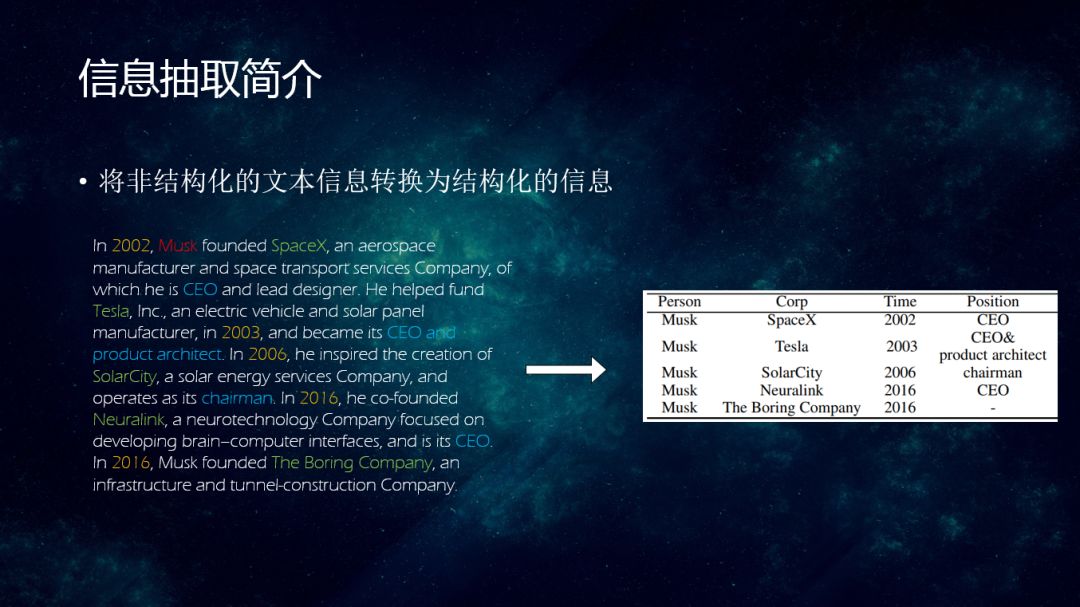
信息抽取是将非结构化的文本信息转换为结构化的信息,如上图所示,左边为非结构化文本,通过信息抽取得到右边结构化的信息。

信息抽取可以分为三类:
命名实体识别(NER):从文本中抽取人物、机构、文件名等实体。
关系抽取(RE):得到实体后,抽取实体间的关系,一般抽取得到一个(实体,实体,关系)的三元组。
事件抽取:抽取多个实体和事件关系,一般得到一个trigger和多个arguments的多元组。
今天主要介绍命名实体识别和关系抽取。
2. 实体关系抽取
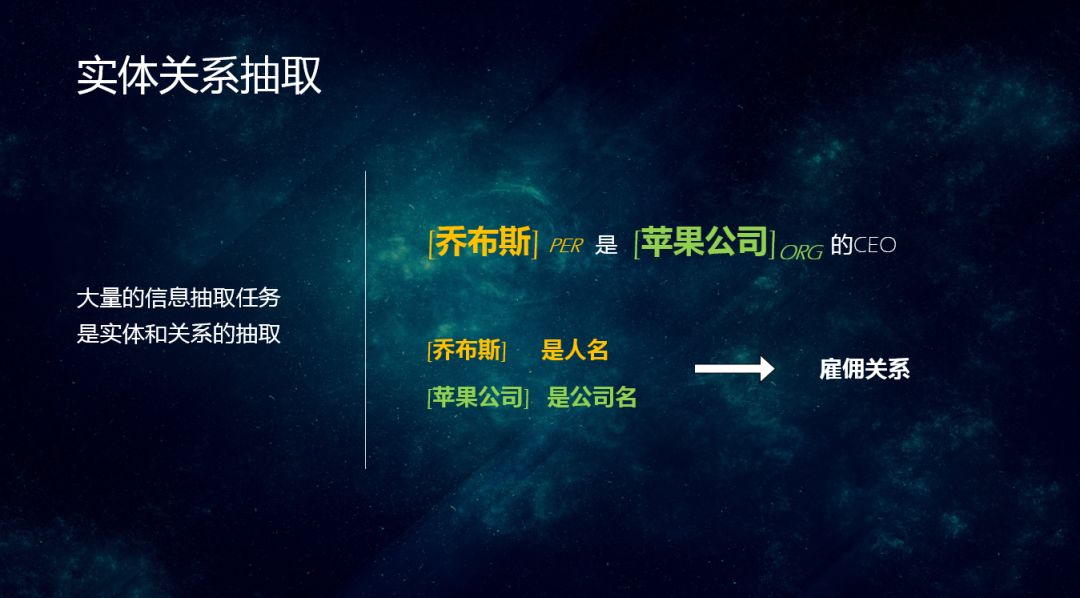
大量的信息抽取任务是实体和关系的抽取,举个例子,乔布斯是苹果公司的CEO。其中"乔布斯"和"苹果公司"是实体,分别是人名、公司名;两个实体之间是雇佣关系。
3. 实体关系抽取的传统做法

实体关系抽取的传统做法:
Pipeline的方法:
先进行命名实体识别,再进行关系识别。
joint方法:
通过共享参数的模型,把实体识别和关系识别联系到一起。
命名实体识别(NER):
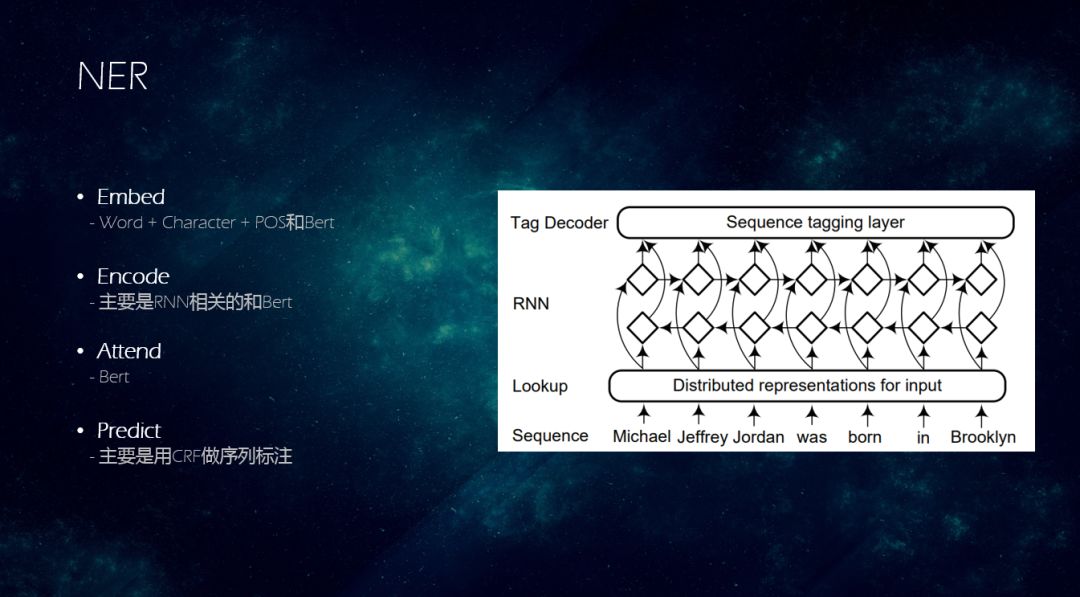
NER也可以分为4步:
-> Embed:把 Michael Jeffrey Jordan was born in Brooklyn,变成一个稠密向量。
-> Encode:在NER中主要是RNN 相关的;
-> Attend:把注意力集中在“一个人在布鲁克林出生”
-> Predict:主要用CRF做序列标注。
也可以用BERT,把Embed到Attend之间都用过BERT来初始化,然后进行fine_tune,然后在最上层加一个Predict的神经网络。
关系抽取(RE):
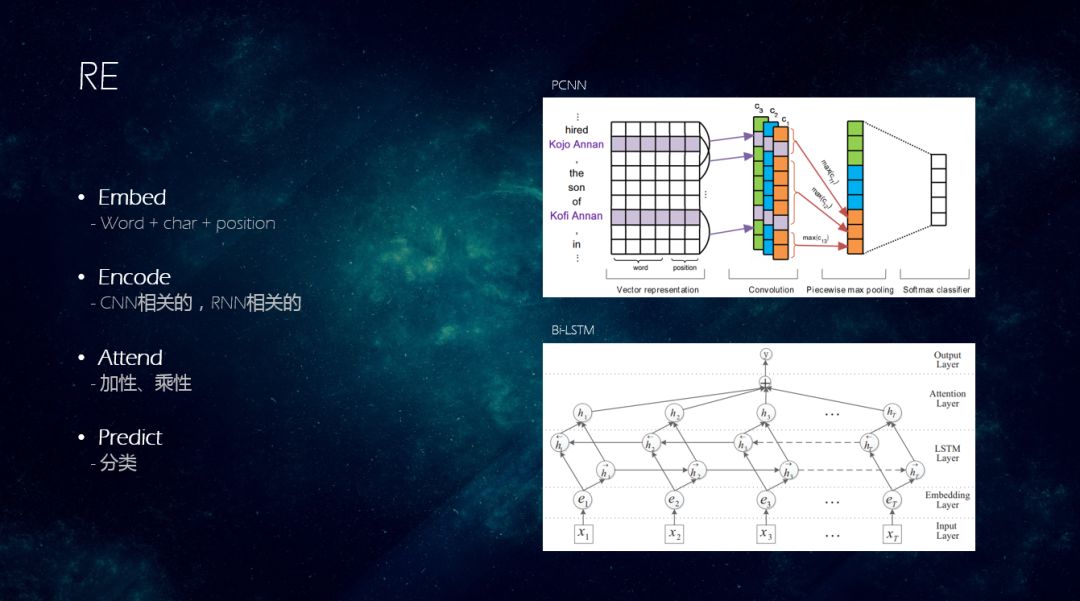
RE一般被model成Classification任务,同样分为以下4步:
-> Embed:还是将字或者词变成一个稠密的向量,这里还会多一个position,一般认为待变成稠密向量的词与实体之间的位置是一个相对位置,如下图中hired和第一个人它的位置可能是-1,然后逗号和它的位置是1,这样的一种Embedding。
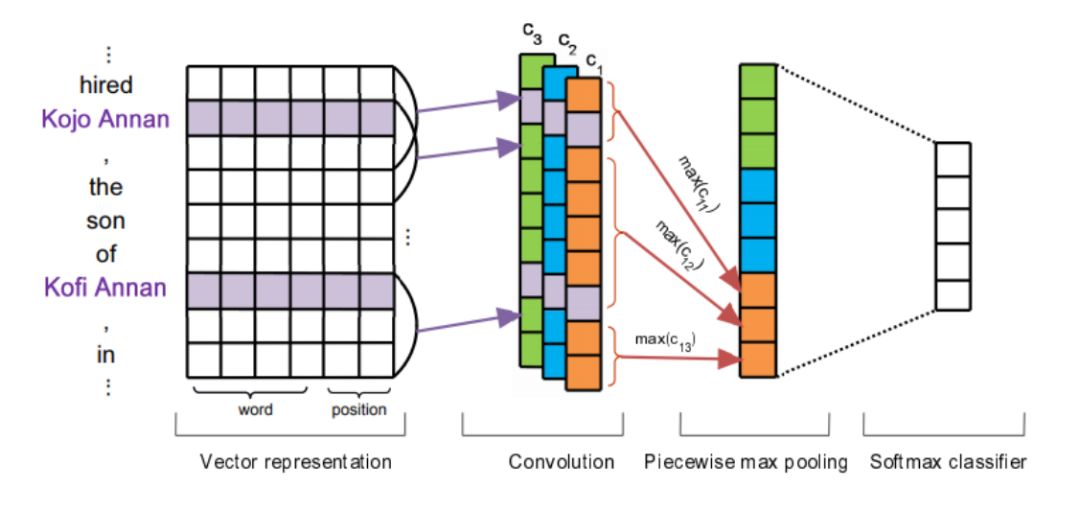
-> Encode:对于关系识别来说,即包含CNN相关的,也包含RNN相关的,把上下文的信息考虑进来。如上图是一个PCNN,通过两个实体把句子分为三部分,每部分分别做CNN的max pooling(由于这三部分的用处不同,直接做max pooling可能会有一些信息的损失),再经过Softmax classifier进行分类。
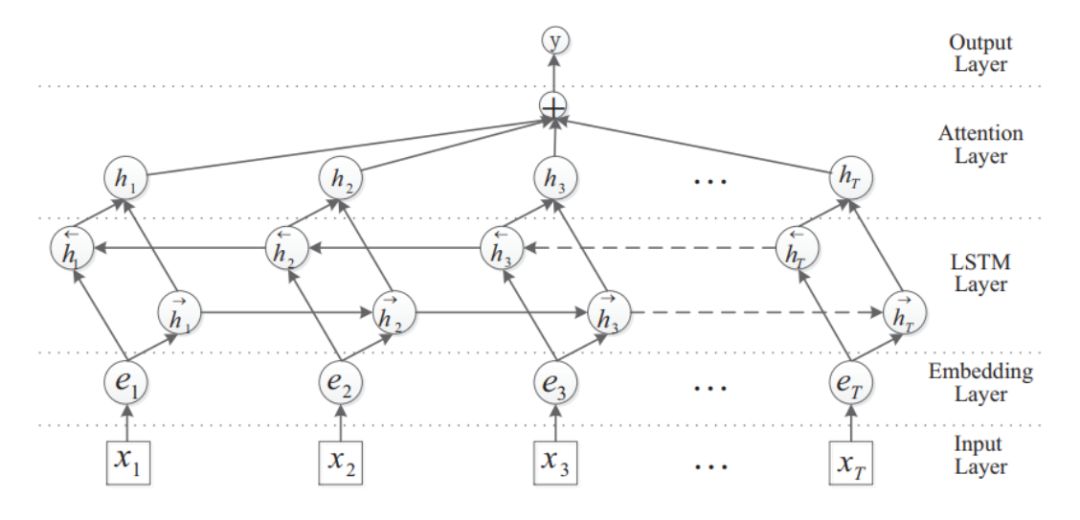
上图为BI-LSTM,同样用了RNN base的网络结构,可以学习到更长距离的依赖。
-> Attend:Attention可以Attend到两个实体是由于哪个词分辨出是顾佣的关系,比如“CEO”就可以认为“苹果公司”和“乔布斯”之间是雇佣关系,有比较大的一个权重。
-> Predict:对定长的向量进行Predict分类。
刚刚说的都是Pipeline的方法,Joint方法也是类似的,主要是把两部分的一些模型的参数在底层被共享起来。
4. 传统方法的问题
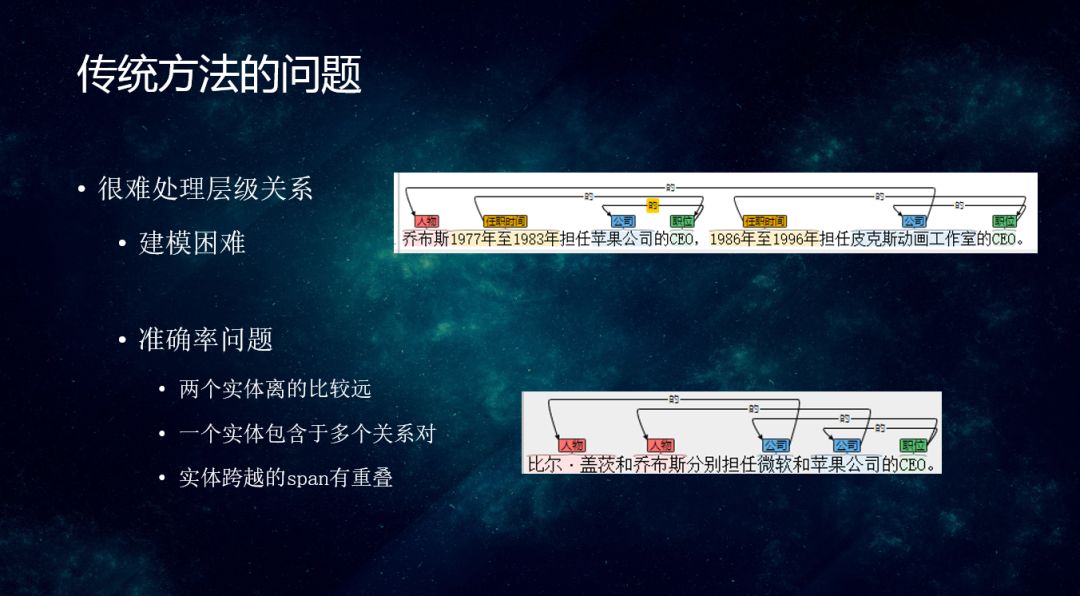
Pipeline和Joint两种方案都存在一些问题:
① 很难处理层级关系:建模困难。如右侧第1张图所示,“乔布斯在1977年至1983年担任了苹果公司的CEO,在1986年至1996年担任皮克斯动画工作室的CEO”。这里存在7个实体,相互间都有关系,非常复杂。
② 准确率问题:
两个实体离得比较远,尤其当一个实体与另外一个实体发生关系时,其实是它的缩写与另外一个实体比较近,而本体与另外一个实体比较远的时候,这样两个实体之间的关系往往很难预测得到。
一个实体包含多个关系对,比如这里的“苹果公司”,既和“CEO”产生关系,又和“乔布斯”产生关系, 包含多个关系,是关系的分类比较复杂。
实体跨越的span有重叠。如右侧第2张图所示,“比尔盖茨和乔布斯分别担任微软和苹果公司的CEO”,“比尔盖茨”是和“微软”产生关系,“乔布斯”是和“苹果公司”产生关系对于刚刚说的PCNN或者RNN来说都会产生混乱的情况,导致识别准确率下降。
▌Part4 机器阅读理解(MPC)
1. 机器阅读理解简介

机器阅读理解是给定上下文c,和问题q,得到答案a,a是原文中的一个或多个span<Question,Context> -> <Answer>。
如图所示,通过提问“郑强什么时候就职于越秀会计事务所?”,我们可以发现,是在1998年到2000年时就职于越秀会计事务所。这样就得到郑强、越秀会计事务所、时间等多个实体间关系。
2. MRC 做法
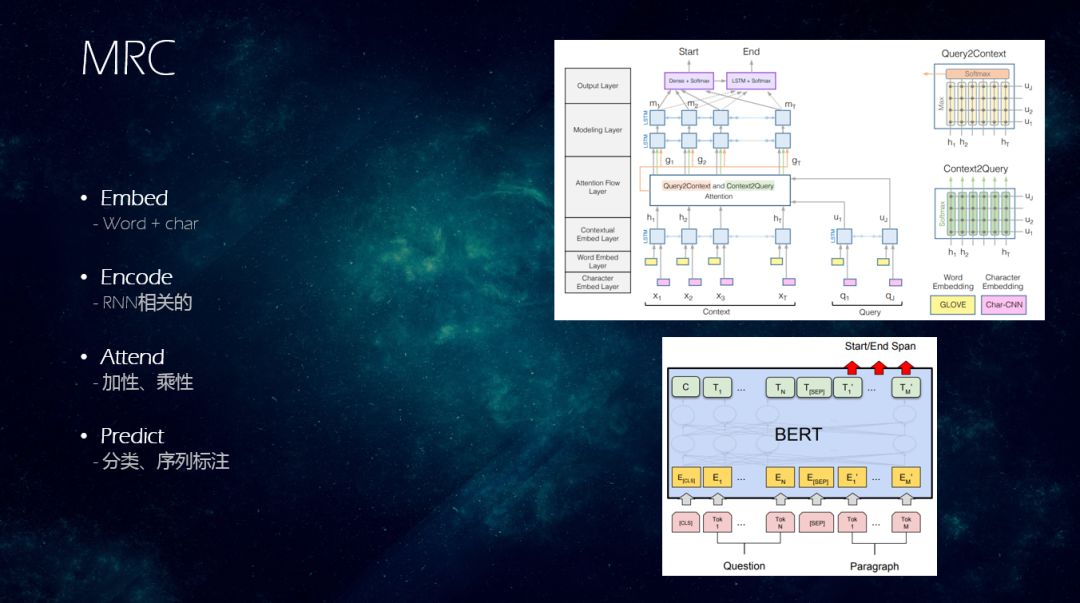
MRC的做法也是分为4步:
范式1,传统的方案:
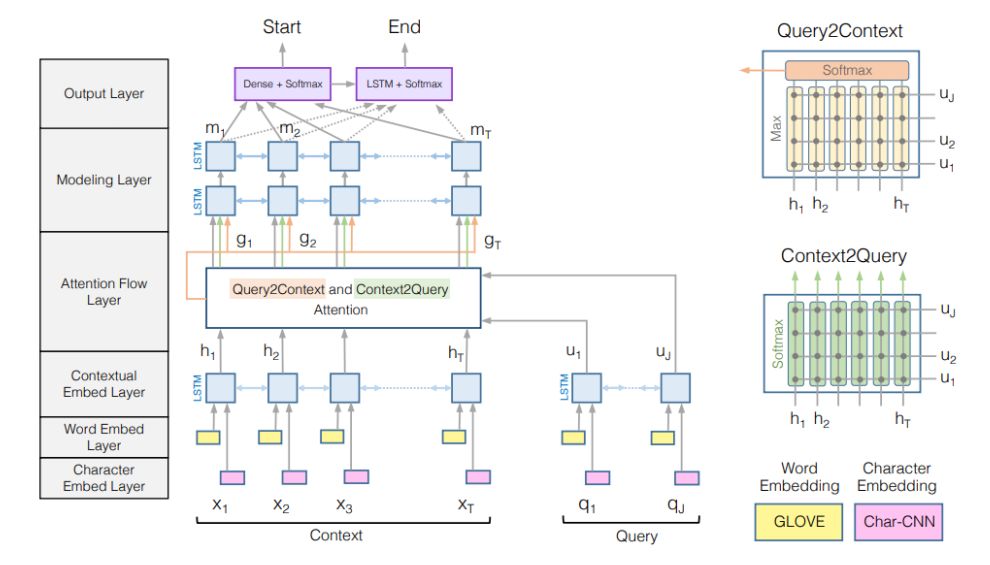
先Embed,把字和词变成稠密向量,通过Contextual进行Encode,这里通过的是LSTM或者GRU之类的方案,通过上下文一起考虑进来,然后进行Attend,question和文章互相注意,最后是Predict,进行分类和序列标注。
范式2:
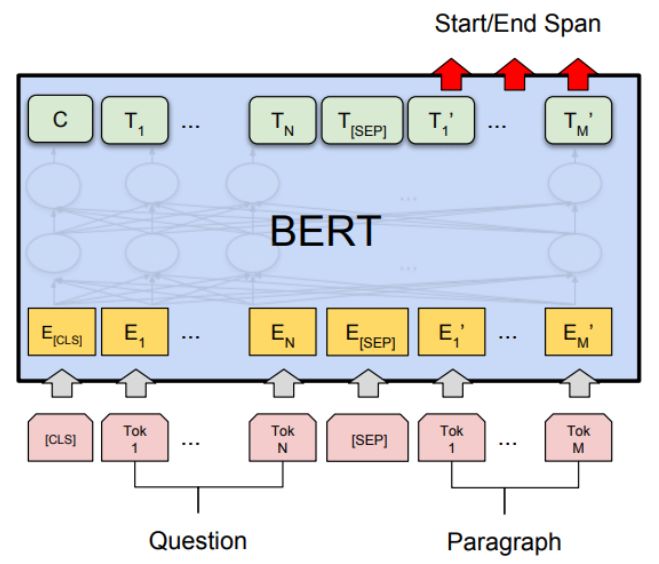
Bert出现之后,可以通过Bert方案,把前3步换成Bert,最后预测一个start和一个end,或者通过序列标注的方案来做。
如上图,Bert时,会在Question的Tok前加一个CLS,后面加一个SEP,然后把Paragraph的Tok放在后面。然后预测Paragraph中哪位置的Tok是start,哪个位置的Tok是end,来预测阅读理解问题。
3. 使用MRC做实体关系抽取

在ACL2019的论文中,我们提出了使用一种MRC的新的范式来做实体和关系抽取。
三元组:(头实体,关系,尾实体)例如(乔布斯,受雇于,苹果公司)
对于“乔布斯是苹果公司的CEO”可以提两个问题:
① 首先提的是头问题,Q:人名是什么?A:乔布斯
② 基于上一步的答案提出第二个问题,Q:乔布斯受雇于哪家公司?A:苹果

上图为,我们算法的详细流程图,首先得到head Entity头实体,对于头实体提问完之后,可以得到头实体的答案,把头实体的答案填入问题模板中,再获得后面的实体。

目标函数就是head-entity的Loss+tail-entity的Loss,然后进行一个加权。
问题模板如上图所示,对于郑强或者马斯克的例子,我们可以问四个问题:
第一个问题是谁在这段话里被提及了,也就是马斯克或者郑强。
第二个问题是郑强在哪个公司任职,得到很多公司。
第三个问题是郑强在这个公司的职务是什么,得到职务。
最后,把上面三步的答案拼在一起得到最后一个问题,E1在E2担当E3的任职时间是什么,得到E4。
4. 多轮问答进行实体-关系抽取
接下来就是刚刚举得例子,首先是第一个问题:
文中提到的人物有哪些?

- linux下逻辑卷的创建和管理
- 前沿: nature刊掀起DAG热, 不掌握就遭淘汰无疑!因果关系研究的图形工具!
- 诺奖夫妇的中国学生, “DID小公主”的成名之作, 茶叶价格与中国失踪女性之谜!
- 时间断点! 酗酒驾车, 合法饮酒年龄政策到底保护了谁? 合法饮酒年龄的断点回归
- 自杀逝世一周年后,AK教授生前最后一篇文章终于见刊了!
- p-hacking的精辟解释, 保证你一辈子都忘不了!
- 最全: 深度学习在经济金融管理领域的应用现状汇总与前沿瞻望, 中青年学者不能不关注!
- “RDD女王”获2020年小诺奖!她的RD数据, 程序, GIS和博士论文可下载!关于她学术研究过程
- Python爬虫之网站超清图片爬取(2021.3.29)
- 介绍B树索引
- 关于事件研究法的50篇精选paper专辑! 助力分析COVID-19的影响!
- Hadoop or TDengine,如何做物联网大数据平台的选型?
- 芝加哥诺奖Heckman开撕哈佛新星Chetty, 样本量胜过仔细的数据分析?
- 视频 | 搜索引擎中的 web 数据挖掘
- 男神毛咕噜最新Top5大作, 另外, 有序因变量依然使用OLS回归!
- 360展示广告召回系统的演进
- Python基础之异常定义
- 基于强化学习的自动搜索
- 基于强化学习的自动搜索
- strcmp的返回值 字符串比较