实战:利用GPU计算海量数据
基于GPU的通用计算已成为近几年人们关注的一个研究热点,谈起计算,我们一般都会先想到CPU,然而GPU同样具有运算能力,并且在特定的场景下由于CPU。从微架构上看,CPU擅长的是像操作系统、系统软件和通用应用程序这类拥有复杂指令调度、循环、分支、逻辑判断以及执行等的程序任务。它的并行优势是程序执行层面的,程序逻辑的复杂度也限定了程序执行的指令并行性,上百个并行程序执行的线程基本看不到。GPU擅长的是图形类的或者是非图形类的高度并行数值计算,GPU可以容纳上千个没有逻辑关系的数值计算线程,它的优势是无逻辑关系数据的并行计算。
在一次数学建模比赛上,我们使用Python计算一些历史数据,然而由于数据量太大,在计算数据上花费了许多时间。我们使用了Python,Pandas, Numpy等常用的科学计算模块计算基站与接收机之间的距离,计算流程图如下所示:

图1 CPU计算数据流程
计算数据的代码如下所示
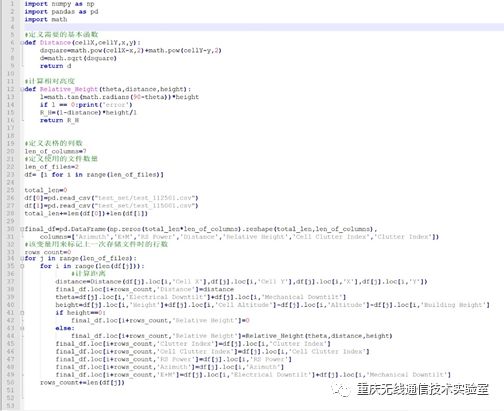
图2 CPU计算距离数据代码
采用以上方案计算了1300万个数据(大约1.3GB),总共花费了4个小时32分钟的时间,并且占用了很多CPU资源,导致不能在电脑上继续工作。后来,分析其原因,发现CPU处理数据的流程和流水线类似,逐条地运行每条指令。从根本上说,CPU微架构的设计是面向指令执行高效率而设计的,因而CPU是计算机中设计最复杂的芯片。和GPU相比,CPU核心的重复设计部分不多,这种复杂性不能仅以晶体管的多寡来衡量,这种复杂性来自于实现:如程序分支预测,推测执行,多重嵌套分支执行,并行执行时候的指令相关性和数据相关性,多核协同处理时候的数据一致性等等复杂逻辑。GPU其实是由硬件实现的一组图形函数的集合,这些函数主要用于绘制各种图形所需要的运算。这些和像素,光影处理,3D坐标变换等相关的运算由GPU硬件加速来实现。图形运算的特点是大量同类型数据的密集运算——如浮点型数据的运算,本次计算的海量数据其实是浮点型的,GPU的微架构就是面向适合于浮点、矩阵类型的数值计算而设计的。GPU运算流程可以简化成下图:
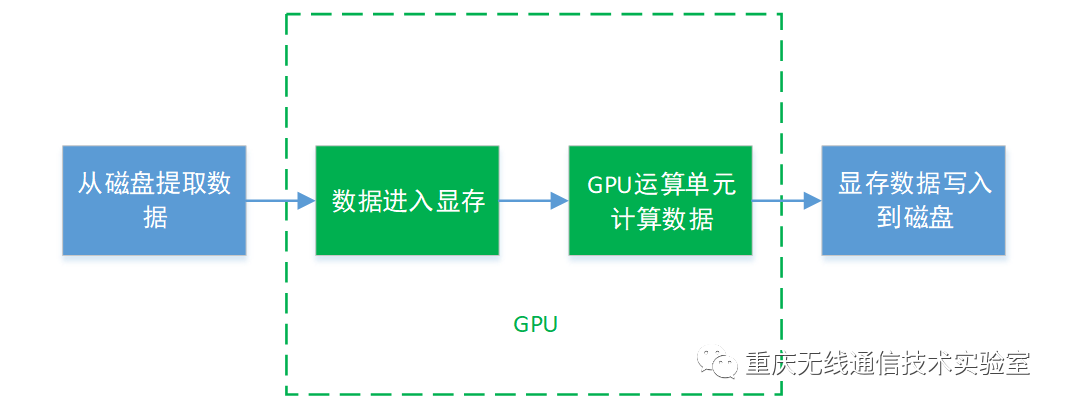
图3 GPU计算数据流程
与CPU计算类似,GPU同样是利用运算单元计算数据。目前市面上先进的CPU具有8个核心,而较好的GPU具有2000个以上的核心,对于数值计算而言,GPU所有核心能够同时参与运算。
由于Pandas不支持GPU运算,故我们采用PyTorch将数据送到GPU中进行运算,其代码如下:
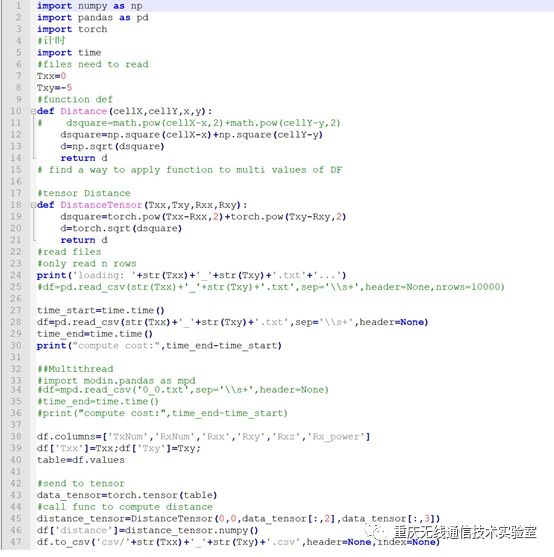
图4 GPU运算代码
两种方案运算结果如下:
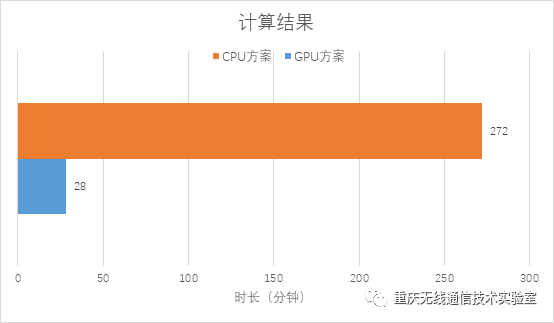
图5 运算时长对比
由上图可直观的看出,采用GPU方案计算数据所花费的时间仅仅为CPU方案的九分之一。可见,由于擅长浮点运算和并行运算,使用GPU可以极大加快计算程序的运行时间,使得GPU在深度学习中占据着主导地位。

- 利用GPGPU方法将大量数据通过纹理传输至GPU进行计算
- 利用WebGL2 实现Web前端的GPU计算
- (五)利用GPU计算整数相加 CUDA
- 利用GPU实现通用计算
- C++ AMP是微软提供的一套利用GPU并行计算的API。
- Spark调研笔记第7篇 - 应用实战: 如何利用Spark集群计算物品相似度
- cuda学习心得--2.真正入手利用GPU计算加法
- 利用GPU进行高性能数据并行计算《程序员》2008年第4期
- matlab利用并行计算和GPU加速SPGD迭代过程
- 【华为云技术分享】如何使用pyCharm与ModelArts公有云服务联动开发,快速且充分地利用云端GPU计算资源
- CUDA 医学成像是最早利用 GPU计算加快性能的应用之一
- 最新GPU并行计算与CUDA编程项目实战教程(完整)
- #####带时间衰减因子#####应用实战: 如何利用Spark集群计算物品相似度
- 利用数据库存储过程计算K线均值算法
- 云计算之KVM虚拟化实战
- A CUDA Support Vector Machine Implementation 利用GPU的CUDA改进支持向量机SVM
- 利用sklearn计算词频
- GPUImage实战问题解决
- 9,javase代码实战-条件语句——switch语句根据用户消费金额计算折扣(四)
- 数学之路-python计算实战(2)-初遇pypy