窥探redis为何会变慢
当今分布式服务大行其道,微服务,微应用解耦的需求层层推进,这个时候,我们经常会用到redis这款中间件作为分布式系统的缓存来使用,以提高系统应用的响应速度,或者说降低服务器的负载难度。那么问题来了,redis速度快的flag是直接写官网的公屏上,那我们不妨来推演一下,redis变慢的原因,知其然而知其所以然。
大家之言
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库。官方提供的数据是可以达到100000+的QPS(每秒内查询次数),数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的。使用多路I/O复用模型,非阻塞IO。
问题1:redis真的只是单进程单线程吗?
问题2:redis数据结构真的简单吗?
不可能单线程
从表面上看采用单线程,这样避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗
CPU,甚至不用去考虑各种锁的问题,因此不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。然而当我们在启用
rdb的时候,当我们在启用
scan的时候,都是会启用一个子进程来完成任务,而原来的主进程任务还是在正常进行,对于系统来说可能会存在响应时间长一点的感知。只看表面的话,对于redis的认知是远远不够的。
redis的数据结构很简单?
嗯,redis的数据结构说简单的话,纯粹是菜鸟教程看多了
redis的结构有挺多的,主要是一下三种:
- 常见的数据结构:string、hash、set、sortset、list
- 特殊结构:HyperLogLog、Geo、Pub/Sub
- redis modult:BloomFilter,RedisSearch,Redis-ML
通过分类我们一来知道这玩意由浅入深的复杂,二来知道通过不通的结构可以处理不同的业务场景。对于业务场景的探讨后续可以展开讲讲,这次主要是想推演一下,在所有场景中挺常见的现象——变慢。
redis为何会变慢
随着时间的堆积,数据的累增,系统很直观的会感觉的变慢的现象,对于大型程序来说,主要是内存碎片啊、堆栈溢出啊等等这些关于垃圾回收机制导致的,另外的还是跟其他组件在配合中,网络开销导致的现象,这次我们主要是从redis自身进行分析。
基本性能
我们应该先知道设备的基本性能,有数据比较才有调优的依据,刚上线的设备性能应该是最优秀的,之后就需要考虑,上线的服务数据的分布问题。
基准性能
Redis 在一台负载正常的机器上,其最大的响应延迟和平均响应延迟分别是怎样的?
Redis 在不同的软硬件环境下,它的性能是各不相同的。
指令
为了获取这些性能的数据,我们可以使用以下指令来获取数据。
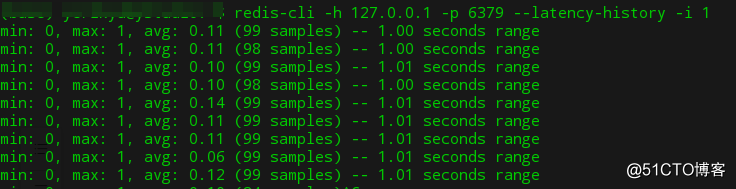
Redis 的最小、最大、平均访问延迟
redis-cli -h 127.0.0.1 -p 6379 --latency-history -i 1
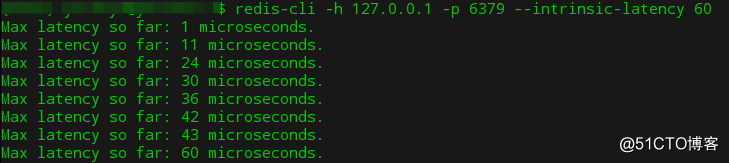
60 秒内的最大响应延迟
redis-cli -h 127.0.0.1 -p 6379 --intrinsic-latency 60
测试步骤
- 在相同配置的服务器上,测试一个正常 Redis 实例的基准性能
- 找到你认为可能变慢的 Redis 实例,测试这个实例的基准性能
- 如果你观察到,这个实例的运行延迟是正常 Redis 基准性能的 2 倍以上,即可认为这个 Redis 实例确实变慢了
发现问题
- 业务服务器到 Redis 服务器之间的网络存在问题,例如网络线路质量不佳,网络数据包在传输时存在延迟、丢包等情况
- Redis 本身存在问题,需要进一步排查是什么原因导致 Redis 变慢
分析问题
分析问题的三把斧,链路追踪,看日志,大胆猜测
链路追踪
这里的链路追踪可能有点离题,因为是从整个系统全组件中,进行链路质量追踪,在这个过程中可以发现某个环节出现时延过高的现象。常见的工具比如
OpenTracing
看日志
目的是想知道在什么时间点,执行了哪些命令比较耗时,这个也是有指令来执行的。
Redis 的慢日志slowlog
查看
Redis慢日志之前,你需要设置慢日志的阈值,让redis知道什么时候就是慢。例如,设置慢日志的阈值为 5 毫秒,并且保留最近 500 条慢日志记录
只记录一个命令真正操作内存数据的耗时
# 命令执行耗时超过 5 毫秒,记录慢日志 CONFIG SET slowlog-log-slower-than 5000 # 只保留最近 500 条慢日志 CONFIG SET slowlog-max-len 500
大胆猜测
这些其实都是平常积累到的情况,也是相关指令本身的问题导致的慢现象。
经常使用 O(N) 以上复杂度的命令,例如 SORT、SUNION、ZUNIONSTORE 聚合类命令
Redis 在操作内存数据时,时间复杂度过高,要花费更多的 CPU 资源。
因此对于数据的聚合操作,放在客户端做,也就是带着强计算能力的终端,redis本质是前端数据到后端数据过渡用的中间件,计算本不是他的强项,过度使用
O(n)级别的指令,会导致redis消耗大量的cpu,因此尽量把相关的开销负载到强cpu 的终端上。
使用 O(N) 复杂度的命令,但 N 的值非常大
Redis 一次需要返回给客户端的数据过多,更多时间花费在数据协议的组装和网络传输过程中,为了避免这种现象,应该需要避免大数据的传输,大象流改老鼠流。执行
O(N)命令,保证
N尽量的小(推荐
N <= 300),每次获取尽量少的数据,让 Redis 可以及时处理返回
操作bigkey
如果一个
key写入的
value非常大,那么 Redis 在分配内存时就会比较耗时。同样的,当删除这个
key时,释放内存也会比较耗时,这种类型的
key我们一般称之为
bigkey
指令
redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.01
- 对线上实例进行 bigkey 扫描时,Redis 的 OPS 会突增,为了降低扫描过程中对 Redis 的影响,最好控制一下扫描的频率,指定 -i 参数即可,它表示扫描过程中每次扫描后休息的时间间隔,单位是秒
- 扫描结果中,对于容器类型(List、Hash、Set、ZSet)的 key,只能扫描出元素最多的 key。但一个 key 的元素多,不一定表示占用内存也多,你还需要根据业务情况,进一步评估内存占用情况
优化
- 业务应用尽量避免写入 bigkey
- 如果你使用的 Redis 是 4.0 以上版本,用 UNLINK 命令替代 DEL,此命令可以把释放 key 内存的操作,放到后台线程中去执行,从而降低对 Redis 的影响
- 如果你使用的 Redis 是 6.0 以上版本,可以开启 lazy-free 机制(lazyfree-lazy-user-del = yes),在执行 DEL 命令时,释放内存也会放到后台线程中执行
集中过期,redis雪崩的现象
变慢的时间点很有规律,例如某个整点,或者每间隔多久就会发生一波延迟
参考资料
- https://redis.io/topics/introduction
- https://www.runoob.com/redis/redis-data-types.html
- https://zhuanlan.zhihu.com/p/58358264
- https://medium.com/rahasak/kafka-with-etcd3-d04f438aa639
- https://www.jianshu.com/p/a036405f989c
- https://tianbin.org/learning/HyperLogLog/
- https://juejin.cn/post/6844903791590916109
- https://juejin.cn/post/684490386207200052

- 为何Redis要比Memcached好用
- Redis为何这么快--关键在于它的数据结构
- 6379-为何Redis选择它作为默认端口号?
- 为何Redis要比Memcached好用(转)
- Redis是新兴的通用存储系统-为何Redis要比Memcached好用
- 为何Redis要比Memcached好用
- Redis 为何这么快?聊聊它的数据结构
- Redis为何这么快?一篇文章带你深入了解Redis
- 为何Redis要比Memcached好用
- [中英对照]Why Redis beats Memcached for caching | 在cache化方面,为何Redis胜过Memcached?
- 为何Redis要比Memcached好用
- 单线程Redis性能为何如此之高?
- sqoop关系型数据迁移原理以及map端内存为何不会爆掉窥探
- 为何Redis要比Memcached好用
- 为何Redis要比Memcached好用
- 为何Redis要比Memcached好用
- Redis 为何这么快--数据存储角度
- sqoop关系型数据迁移原理以及map端内存为何不会爆掉窥探
- Redis为何这么快?
- Redis为何这么快--数据存储角度