如何获取kafka的broker保存的消费者信息?
2021-03-19 00:00
134 查看
如何获取kafka的broker保存的消费者信息?
浪院长 浪尖聊大数据
kafka的消费者对于kafka 082版本,有
高阶API (例子:https://cwiki.apache.org/confluence/display/KAFKA/Consumer+Group+Example)
和
低阶API (例子:https://cwiki.apache.org/confluence/display/KAFKA/0.8.0+SimpleConsumer+Example)
之分。
两者的细节,可以对比上面链接的例子。
高阶API消费者会有一个后台线程单独负责按照auto.commit.enable=true;
auto.commit.interval.ms={时间间隔}周期性提交offset到zk。
zk保存的offset信息如下:

kafka010的版本,例子链接:
http://kafka.apache.org/0102/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html
consumers在zookeeper上的信息已经没有:
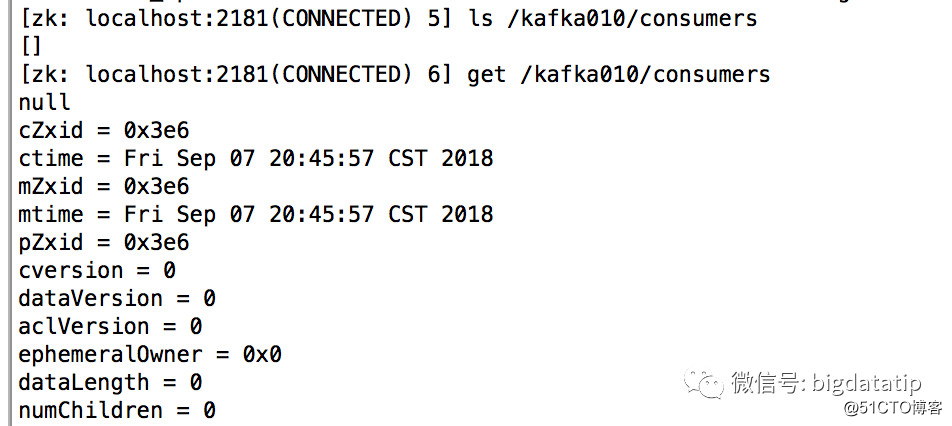
消费者的组和offset信息提交到broker的topic上了,topic名字__consumer_offsets。
kafka 010的__consumer_offsets topic的schema信息;
val OFFSET_COMMIT_VALUE_SCHEMA_V1 = new Schema(new Field("offset", INT64),
new Field("metadata", STRING, "Associated metadata.", ""),
new Field("commit_timestamp", INT64),
new Field("expire_timestamp", INT64))
topic具体数据如下:
(test1,test,0) [OffsetMetadata[26231,NO_METADATA],CommitTime 1537587480006,ExpirationTime 1537673880006]
获取消费者offset的信息主要是为了监控kafka消费者消费的lag 进而把控消费者的处理情况,本文主要是帮助大家获取kafka-0.10.+版本的消费者已经提交的offset信息,然后后面会再出文章去帮助大家获取broker上指定topic分区的最大offset。
主函数完整代码。
package bigdata.spark.kafka
import java.nio.ByteBuffer
import java.util.Properties
import java.util.concurrent.TimeUnit
import kafka.common.{KafkaException, OffsetAndMetadata}
import org.apache.kafka.clients.consumer.{Consumer, ConsumerRecords, KafkaConsumer}
import org.apache.kafka.common.TopicPartition
import bigdata.spark.kafka.GroupMetadataManager._
import com.github.benmanes.caffeine.cache.{Cache, Caffeine, RemovalCause, RemovalListener}
object monitor {
def createKafkaConsumer(): Consumer[Array[Byte], Array[Byte]] = {
val props: Properties = new Properties()
props.put("bootstrap.servers", "mt-mdh.local:9093")
props.put("group.id", "test2")
props.put("enable.auto.commit", "false")
props.put("auto.offset.reset", "earliest")
props.put("key.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer")
props.put("value.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer")
new KafkaConsumer[Array[Byte], Array[Byte]](props)
}
def readMessageKey(buffer: ByteBuffer): BaseKey = {
val version = buffer.getShort
val keySchema = schemaForKey(version)
val key = keySchema.read(buffer)
//
if (version <= CURRENT_OFFSET_KEY_SCHEMA_VERSION) {
// version 0 and 1 refer to offset
val group = key.get("group").asInstanceOf[String]
val topic = key.get("topic").asInstanceOf[String]
val partition = key.get("partition").asInstanceOf[Int]
OffsetKey(version, GroupTopicPartition(group, new TopicPartition(topic, partition)))
}else if (version == CURRENT_GROUP_KEY_SCHEMA_VERSION) {
// version 2 refers to offset
val group = key.get("group").asInstanceOf[String]
GroupMetadataKey(version, group)
} else {
throw new IllegalStateException("Unknown version " + version + " for group metadata message")
}
}
def readOffsetMessageValue(buffer: ByteBuffer): OffsetAndMetadata = {
if (buffer == null) { // tombstone
null
} else {
val version = buffer.getShort
val valueSchema = schemaForOffset(version)
val value = valueSchema.read(buffer)
if (version == 0) {
val offset = value.get("offset").asInstanceOf[Long]
val metadata = value.get("metadata").asInstanceOf[String]
val timestamp = value.get("timestamp").asInstanceOf[Long]
OffsetAndMetadata(offset, metadata, timestamp)
} else if (version == 1) {
val offset = value.get("offset").asInstanceOf[Long]
val metadata = value.get("metadata").asInstanceOf[String]
val commitTimestamp = value.get("commit_timestamp").asInstanceOf[Long]
val expireTimestamp = value.get("expire_timestamp").asInstanceOf[Long]
OffsetAndMetadata(offset, metadata, commitTimestamp, expireTimestamp)
} else {
throw new IllegalStateException("Unknown offset message version")
}
}
}
// 主要类是 kafkaStateActor
def main(args: Array[String]): Unit = {
val groupTopicPartitionOffsetMap:Cache[(String, String, Int), OffsetAndMetadata] = Caffeine
.newBuilder()
.maximumSize(1025)
.expireAfterAccess(10, TimeUnit.DAYS)
// .removalListener(new RemovalListener[(String, String, Int), OffsetAndMetadata] {
// override def onRemoval(key: (String, String, Int), value: OffsetAndMetadata, cause: RemovalCause): Unit = {
// println("remove !")
// }
// })
.build[(String, String, Int), OffsetAndMetadata]()
val consumer = createKafkaConsumer()
consumer.subscribe(java.util.Arrays.asList("__consumer_offsets"))
while (true){
val records: ConsumerRecords[Array[Byte], Array[Byte]] = consumer.poll(100)
val iterator = records.iterator()
while (iterator.hasNext) {
val record = iterator.next()
readMessageKey(ByteBuffer.wrap(record.key()))match {
case OffsetKey(version, key) =>
val orgnal = record.value()
if(orgnal!=null){
val value: OffsetAndMetadata = readOffsetMessageValue(ByteBuffer.wrap(record.value()))
val newKey = (key.group, key.topicPartition.topic, key.topicPartition.partition)
println(newKey)
println(value)
groupTopicPartitionOffsetMap.put(newKey, value)
}
case GroupMetadataKey(version, key) =>
Nil
}
}
}
}
}

相关文章推荐
- kafka源码解析之十七消费者流程(客户端如何获取topic的数据)
- 如何在Service层获取用户session中保存的用户信息的方法
- springboot kafka消费者获取不到信息
- 如何通过session获取并保存表单信息
- Servlet如何从浏览器的表单获取中文信息并保存到磁盘的xml文档中不出现乱码
- 如何在Service层获取用户session中保存的用户信息的方法(Filter+ThreadLocal)
- 如何查看kafka消费者信息?
- Spring boot 整合kafka实现消费者customer批量获取信息
- 如何用Revit API 在Revit的模型中获取轮廓族的截面信息
- kafka的javaapi生产者生产消息,消费者获取不到
- 如何解决设置Session保存在StateServer后引起WebService/WebMethod无法异步获取Session
- Qt: QTableView如何获取(行)选中、行切换信息
- 如何利用Java获取系统的信息(CPU、内存、各盘符使用情况)
- Get请求/Post请求与如何在Servlet中获取请求信息——day_07
- 如何获取CPU的相关信息 包括CPU编号、版本、产品名称、制造商
- Android如何获取手机各项信息
- CE MAPI实例讲解 --- 如何获取收件人信息(六)
- Window Service程序中如何获取登陆用户的信息
- 如何获取文件信息
- C#中如何获取数据库中表的信息和列的信息