Flink并行度
Flink并行度
深圳浪尖 浪尖聊大数据
并行执行
本节介绍如何在Flink中配置程序的并行执行。FLink程序由多个任务(转换/操作符、数据源和sinks)组成。任务被分成多个并行实例来执行,每个并行实例处理任务的输入数据的子集。任务的并行实例的数量称之为并行性。
如果要使用保存点,还应该考虑设置最大并行性(或最大并行性)。当从保存点还原时,可以改变特定运算符或整个程序的并行性,并且该设置指定并行性的上限。这是必需的,因为FLINK内部将状态划分为key-groups,并且我们不能拥有+INF的key-group数,因为这将对性能有害。
Flink中人物的并行度可以从多个不同层面设置:
1, 操作算子层面
2, 执行环境层面‘
3, 客户端层面
4, 系统层面
5,设置slots
操作算子层
操作算子,数据源,数据接收器等这些并行度都可以通过调用他们的setParallelism()方法设置。例如:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = [...]
val wordCounts = text
.flatMap{ _.split(" ") map { (_, 1) } }
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1).setParallelism(5)
wordCounts.print()
env.execute("Word Count Example")
执行环境层面
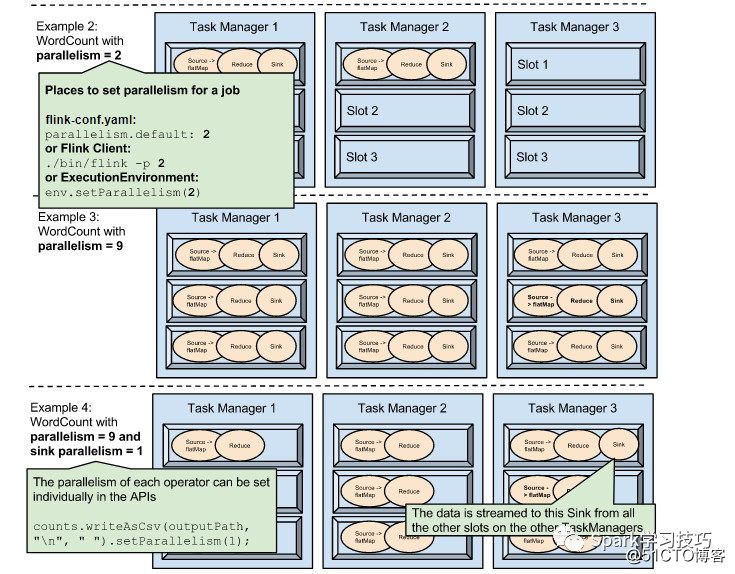
flink程序执行需要执行环境上下文。执行环境为其要执行的操作算子,数据源,数据sinks都是设置了默认的并行度。执行环境的并行度可以通过操作算子显示指定并行度来覆盖掉。
默认的执行环境并行度可以通过调用setParallelism()来设置。例如,操作算子,数据源,数据接收器,并行度都设置为3,那么在执行环境层面,设置方式如下:
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(3)
val text = [...]
val wordCounts = text
.flatMap{ _.split(" ") map { (_, 1) } }
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
wordCounts.print()
env.execute("Word Count Example")
客户端层
在提交job 到flink的时候,在客户端侧也可以设置flink的并行度。客户端即可以是java工程,也可以是scala工程。Flink的Command-line Interface (CLI)就是这样一种客户端。
在客户端侧flink可以通过-p参数来设置并行度。例如:
./bin/flink run -p 10 ../examples/WordCount-java.jar
在java/scala客户端,并行度设置方式如下:
try {
PackagedProgram program = new PackagedProgram(file, args)
InetSocketAddress jobManagerAddress = RemoteExecutor.getInetFromHostport("localhost:6123")
Configuration config = new Configuration()
Client client = new Client(jobManagerAddress, new Configuration(), program.getUserCodeClassLoader())
// set the parallelism to 10 here
client.run(program, 10, true)
} catch {
case e: Exception => e.printStackTrace
}
系统层面
系统层面的并行度设置,会针对所有的执行环境生效,可以通过parallelism.default,属性在conf/flink-conf.yaml文件中设置。
设置最大并行度
设置最大并行度,实际上调用的方法是setMaxParallelism(),其调用位置和setParallelism()一样。
默认的最大并行度是近似于operatorParallelism + (operatorParallelism / 2),下限是127,上线是32768.
值得注意的是将最大的并行的设置为超级大的数可能会对性能造成不利的影响,因为一些状态后端是必须要保存内部数据结构的,这个数据结构跟key-group数量相匹配(这是可重定状态的内部实现机制)。
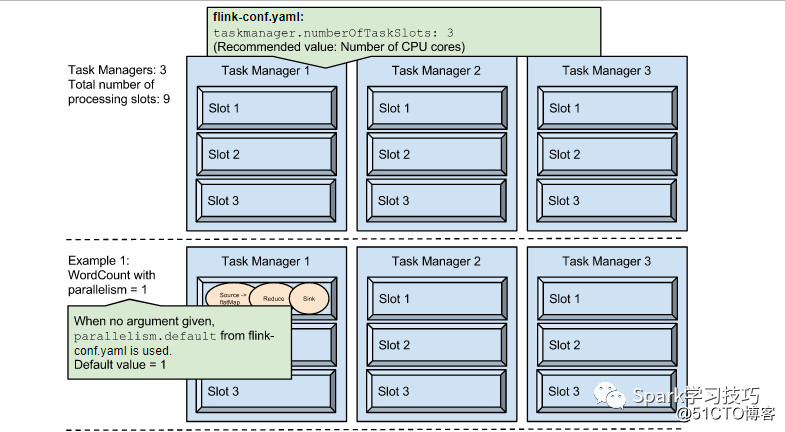
配置taskmanagerslot
flink通过将项目分成tasks,来实现并行的执行项目,划分的tasks会被发到slot去处理。
集群中Flink的taskmanager提供处理slot。Slots数量最合适的是跟taskmanager的cores数量成正比。当然,taskmanager.numberOfTaskSlots的推荐值就是cpu核心的数目。
当启动一个任务的时候,我们可以为其提供默认的slot数目,其实也即是flink工程的并行度,设置方式在上面已经有详细介绍。

- Flink 并行度 slot
- Flink源码系列—— 4000 获取StreamGraph的过程
- FLink程序:打包
- flink on yarn部署
- Flink 靠什么征服饿了么工程师?
- 作为一个编程新手,我再也不怕Flink迷了我的眼!
- 阿里、Uber都在用的Flink你了解多少?
- [Flink基础]--Apache Flink中的广播状态实用指南
- Flink开发IDEA环境搭建与测试
- Flink初体验 -- Word Count
- 对Flink官网资源的初步了解
- [Flink基础]-- 一致性的3个级别
- 追源索骥:透过源码看懂Flink核心框架的执行流程
- Apache Flink 分布式运行时环境
- 最详细Flink环境部署教程
- Flink基础 -- 2.Flink的安装和第一个Demo
- 从Storm到Flink:大数据处理的开源系统及编程模型
- 大数据计算引擎——Flink学习
- flink总结
- Stream SQL 的执行原理与 Flink 的实现