自己动手实现scikit库中的fit和transform方法
上一期文章是如何从文本中提取特征信息?,文本分析第一步要解决的是如何将文本非结构化信息转化为结构化信息,其中最关键的是特征抽取,我们使用scikit-learn库fit和tranform方法实现了文本数据的特征抽取。
但是对于fit和transform,大家可能还是有点迷糊。最近又将《Applied Text Analysis WIth Python》读了一遍(别惊讶,82页过一遍很快的。之前一直以为这本书82页,今天才发现这本书完整版是400多页。)我主要结合这本书代码和自己的理解,实现了fit和tranform算法,方便大家更好的理解文本分析特征抽取。
一、scikit库 代码实例
-
fit方法作用:给文本数据建立词典的过程
- transform方法作用:根据词典对所有的文本数据进行编码(转码)
1.1 我们先看看fit代码实例
corpus = ["Hey hey hey lets go get lunch today :)", "Did you go home?", "Hey!!! I need a favor"] from sklearn.feature_extraction.text import CountVectorizer vectorize = CountVectorizer() #fit学会语料中的所有词语,构建词典 vectorize.fit(corpus) #这里我们查看下“词典”,也就是特征集(11个特征词) print(vectorize.get_feature_names()) ['did', 'favor', 'get', 'go', 'hey', 'home', 'lets', 'lunch', 'need', 'today', 'you']
1.2 transform实例
根据建立好的词典vectorize对corpus进行编码。这里为了便于观看理解,我们使用pandas处理下数据输出。
import pandas as pd dtm = vectorize.transform(corpus) colums_name = vectorize.get_feature_names() series = dtm.toarray() print(pd.DataFrame(series, columns = colums_name ))
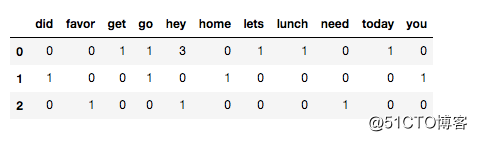
从上面的dataframe表中,行代表一个文档,列代表特征词。比如第1行,hey列的所对应的单元格值为3,说明corpus中第一个document(Hey hey hey lets go get lunch today :) 出现了三次hey。
二、fit 与 transform算法实现
思路:
-
首先要对输入的文本数据能够分词(这里我们假设是英文吧)
-
对英文字符能够识别是否为符号,防止出现如“good_enough”这种中间含有非英文字符。
-
剔除停止词,如“a”、“ the”等
-
词干化
-
经过步骤1-4清洗,输出干净的词语列表数据。
-
基于词语列表,这里需要有一个容器存储每一个新出现的单词,构建出特征词词典。
- 根据建立好的词典,对输入的数据进行编码。
2.1 分词
这里我们直接使用nltk.tokenize库中的word_tokenize分词函数。
from nltk.tokenize import word_tokenize
word_tokenize("Today is a beatiful day!")
['Today', 'is', 'a', 'beatiful', 'day', '!']
我们看到上面结果有“!”,所以接下来我们要判断分词结果是否为单词。
2.2 标点符号判断
《Applied text analysis with python》一书中判别分词结果是否为符号代码为
def is_punct(token):
return all(unicodedata.category(char).startswith('P') for char in token)
测试了下发现,category(符号),结果为“Po”。
import unicodedata
#这里以“!”做个测试
unicodedata.category('!')
Po
而all(data)函数是Python内置函数,当data内各个元素一致时返回True,否则返回False。
print(all([True, False])) print(all([True, True])) False True
2.3 停止词
nltk提供了丰富的文本分析工具,停止词表全部为小写单词,所以判断前要先将token小写化。
def is_stopword(token):
stopwords = nltk.corpus.stopwords.words('english')
return token.lower() in stopwords
2.4 词干化
对单复数、不同时态、不同语态等异形词归并为一个统一词。这里有stem和lemmatize两种实现方法,下面我们分别看看算法。
2.4.1 stem
import nltkdef stem(token):
stem = nltk.stem.SnowballStemmer('english')
return stem.stem(token)
2.4.2 lemmatize
from nltk.corpus import wordnet as wn
from nltk.stem.wordnet import WordNetLemmatizer
def lemmatize(token, pos_tag):
lemmatizer = WordNetLemmatizer()
tag = {
'N': wn.NOUN,
'V': wn.VERB,
'R': wn.ADV,
'J': wn.ADJ}.get(pos_tag[0])
if tag:
return lemmatizer.lemmatize(token.lower(), tag)
else:return None
print(stem('better'))
print(lemmatize('better', 'JJ'))
better
good
从中我们可以看出lemmatize更准确,对于小数据量的分析,为了力求精准我个人建议用lemmatize。
2.5 清洗数据
def clean(document):
return [lemmatize(token, tag) for (token, tag) in nltk.pos_tag(word_tokenize(document)) if not is_punct(token) and not is_stopword(token)]
print(clean('He was a soldier 20 years ago!'))
['soldier', None, 'year', 'ago']
结果中出现None,这是不能允许的。原因应该是lemmatize函数。所以我们要加一个判断
def clean(document):
return [lemmatize(token, tag) for (token, tag) in nltk.pos_tag(word_tokenize(document))if not is_punct(token) and not is_stopword(token) and lemmatize(token, tag)]
print(clean('He was a soldier 20 years ago!'))
['soldier', 'year', 'ago']
2.6 构建词典-fit
我们需要将待分析的文本数据中抽取出所有的特征词,并将其存入一个词典列表中。思路:凡是新出现,不存在于词典列表vocab中,就将其加入到vocab中。
def fit(X, y=None): vocab = [] for doc in X: for token in clean(doc): if token not in vocab: vocab.append(token) return vocab X = ["The elephant sneezed at the sight of potatoes.Its very interesting thing.\nBut at the sight of potatoes", "Bats can see via echolocation. See the bat sight sneeze!\nBut it is a bats", "Wondering, she opened the door to the studio.\nHaha!good"]
print(fit(X)) ['elephant', 'sneeze', 'sight', 'potatoes.its', 'interesting', 'thing', 'potato', 'bat', 'see', 'echolocation', 'wondering', 'open', 'door', 'studio', 'haha', 'good']
词典已经构建好了。
2.7 对待分析文本数据编码-transform
根据构建好的词典列表,我们开始对文本数据进行转码。思路不难,只要对文档分词结果与词典列表一一分析,该特征词出现几次就为几。
def transform(documents): vacab = fit(documents) for doc in documents: result = [] tokens = clean(doc) for va in vacab: result.append(tokens.count(va)) yield result documents = ["The elephant sneezed at the sight of potatoes.Its very interesting thing.\nBut at the sight of potatoes", "Bats can see via echolocation. See the bat sight sneeze!\nBut it is a bats", "Wondering, she opened the door to the studio.\nHaha!good"] print(list(transform(documents))) [[1, 1, 2, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 1, 1, 0, 0, 0, 0, 3, 2, 1, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]]
三、完整版
现在我们将上面的代码合并为TextExtractFeature类
import nltk
import unicodedata
from collections import defaultdict
from nltk.corpus import wordnet as wn
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.tokenize import word_tokenize
class TextExtractFeature(object):
def __init__(self, language='english'):
self.stopwords = set(nltk.corpus.stopwords.words(language))
self.lemmatizer = WordNetLemmatizer()
def is_punct(self, token):
return all(unicodedata.category(char).startswith('P') for char in token)
def is_stopword(self, token):
return token.lower() in self.stopwords
def lemmatize(self, token, pos_tag):
tag = {
'N': wn.NOUN,
'V': wn.VERB,
'R': wn.ADV,
'J': wn.ADJ}.get(pos_tag[0])
if tag:
return self.lemmatizer.lemmatize(token.lower(), tag)
else:return None
def clean(self, document):
return [self.lemmatize(token, tag).lower() for (token, tag) in nltk.pos_tag(word_tokenize(document)) if not self.is_punct(token) and not self.is_stopword(token) and self.lemmatize(token, tag)]
def fit(self, X, y=None):
self.y = y
self.vocab = []
self.feature_names = defaultdict(int)
for doc in X:
for token in self.clean(doc):
if token not in self.vocab:
self.feature_names[token] = len(self.vacab)
self.vocab.append(token)
def get_feature_names(self):
return self.feature_names
def transform(self, documents):
for idx,doc in enumerate(documents):
result = []
tokens = self.clean(doc)
for va in self.vocab:
result.append(tokens.count(va))
if self.y:
result.append(self.y[idx])
yield result
documents = [ "The elephant sneezed at the sight of potatoes.Its very interesting thing.\nBut at the sight of potatoes", "Bats can see via echolocation. See the bat sight sneeze!\nBut it is a bats", "Wondering, she opened the door to the studio.\nHaha!good", ] y = [1, 1, 1] tef = TextExtractFeature(language='english') #构建词典tef.fit(documents, y) #打印词典映射关系。即特征词 print(tef.get_feature_names()) for s in tef.transform(documents): print(s)
defaultdict(<class 'int'>, {'elephant': 0, 'sneeze': 1, 'sight': 2, 'potatoes.its': 3, 'interesting': 4, 'thing': 5, 'potato': 6, 'bats': 7, 'see': 8, 'echolocation': 9, 'bat': 10, 'wondering': 11,'open': 12, 'door': 13, 'studio': 14, 'haha': 15, 'good': 16})
[1, 1, 2, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
[0, 1, 1, 0, 0, 0, 0, 1, 2, 1, 2, 0, 0, 0, 0, 0, 0, 1]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]

- 自己动手写ORM框架(八):实现修改功能Update方法
- 自己动手写ORM框架(六):实现查询功能FindById方法
- Atitit 学习一项技术的方法总结 目录 1. 自己动手实现学习法 1 2. 七步学习法 —— 如何高效学习一项技能 1 3. 如何快速学习一项技能-十步学习法 - HugoLester - 博客
- 自己动手写ORM框架(六):实现查询功能FindById方法
- 自己动手实现谷歌网页指纹计算方法
- 自己动手写ORM框架(七):实现新增功能Save方法
- 自己动手实现mybatis动态sql的方法
- 自己动手写ORM框架(九):实现删除功能Remove方法
- 给自己的网站制作一个favicon.ico图标的实现方法
- 自己动手写控件----textbox之实现视图状态!
- .NET实现之(自己动手写高内聚插件系统)
- 自己动手实现基于MIDP的ResourceBundle类
- 自己动手实现自定义线程池
- 自己动手写Python实现Ubuntu自动切换壁纸
- 自己动手制作jquery插件之自动添加删除行的实现
- 让自己的程序界面实现XP风格的两种方法
- ajax实时任务提示功能的实现 -- vb2005xu自己动手系列(1)
- java properties 的六种读取方法 以及一种自己最方便的实现
- 【自己动手】实现简单的C++ smart pointer
- 自己动手重新实现LINQ to Objects: 6 - Repeat