阿里面试:Mybatis中方法和SQL是怎么关联起来的呢?
本文:3126字 | 阅读时长:4分10秒
今天是Mybatis源码分析第四篇,也是最后一篇。
老规矩,先上案例代码:
public class MybatisApplication {
public static final String URL = "jdbc:mysql://localhost:3306/mblog";
public static final String USER = "root";
public static final String PASSWORD = "123456";
public static void main(String[] args) {
String resource = "mybatis-config.xml";
InputStream inputStream = null;
SqlSession sqlSession = null;
try {
inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//下面这行代码就是今天的重点
User user = userMapper.selectById(1));
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
sqlSession.close();
}
}
已经分享了三篇Mybatis源码分析文章,从 Mybatis的配置文件解析 到 获取SqlSession,再到 获取UserMapper接口的代理对象。
今天我们来分析,userMapper中的方法和UserMapper.xml中的SQL是怎么关联的,以及怎么执行SQL的。
我们的故事从这一行代码开始:
User user = userMapper.selectById(1));
这一行代码背后源码搞完,也就代表着我们Mybatis源码搞完(主干部分)。
下面我们继续开撸。

在上一篇中我们知道了userMapper是JDK动态代理对象,所以调用这个代理对象的任意方法都是执行触发管理类MapperProxy的invoke()方法。
由于篇幅较长,为了更好阅读,这里把文章分成两个部分:
- 第一部分:MapperProxy.invoke()到Executor.query。
- 第二部分:Executor.query到JDBC中的SQL执行。
第一部分流程图:
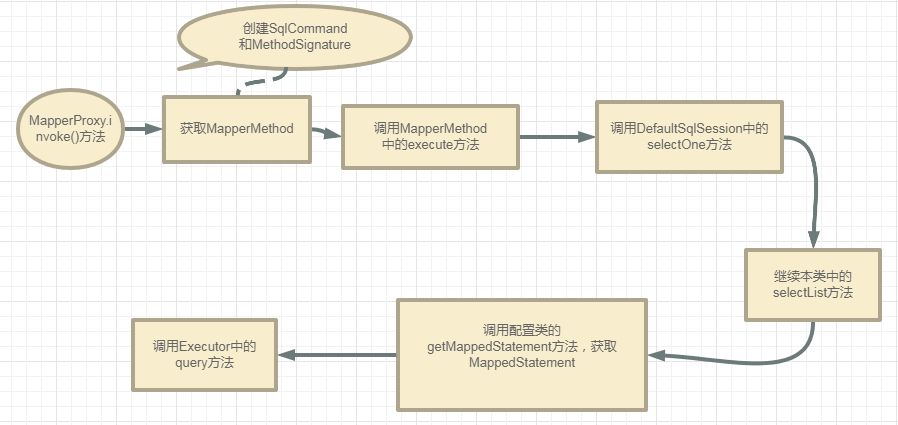
MapperProxy.invoke()
开篇已经说过了,调用userMapper的方法就是调用MapperProxy的invoke()方法,所以我们就从这invoke()方法开始。
如果对于Mybatis源码不是很熟悉的话,建议先看看前面的文章。
//MapperProxy类
@Override
public Object invoke(....) throws Throwable {
try {
//首先判断是否为Object本身的方法,是则不需要去执行SQL,
//比如:toString()、hashCode()、equals()等方法。
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (method.isDefault()) {
//判断是否JDK8及以后的接口默认实现方法。
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
//<3>
final MapperMethod mapperMethod = cachedMapperMethod(method);
//<4>
return mapperMethod.execute(sqlSession, args);
}
<3>处是从缓存获取MapperMethod,这里加入了缓存主要是为了提升MapperMethod的获取速度。缓存的使用在Mybatis中也是非常之多。
private final Map<Method, MapperMethod> methodCache;
private MapperMethod cachedMapperMethod(Method method) {
return methodCache.computeIfAbsent(method, k -> new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
Map的computeIfAbsent方法:根据key获取值,如果值为null,则把后面的Object的值付给key。
继续看MapperMethod这个类,定义了两个属性command和method,两个属性与之相对应的两个静态内部类。
public class MapperMethod {
private final SqlCommand command;
private final MethodSignature method;
public static class SqlCommand {
private final String name;
private final SqlCommandType type;
public SqlCommand(...) {
final String methodName = method.getName();
final Class<?> declaringClass = method.getDeclaringClass();
//获得 MappedStatement 对象
MappedStatement ms = resolveMappedStatement(...);
// <2> 找不到 MappedStatement
if (ms == null) {
// 如果有 @Flush 注解,则标记为 FLUSH 类型
if (method.getAnnotation(Flush.class) != null) {
name = null;
type = SqlCommandType.FLUSH;
} else {
// 抛出 BindingException 异常,如果找不到 MappedStatement
//(开发中容易见到的错误)说明该方法上,没有对应的 SQL 声明。
throw new BindingException("Invalid bound statement (not found): "+ mapperInterface.getName() + "." + methodName);
}
} else {
// 获得 name
//id=com.tian.mybatis.mapper.UserMapper.selectById
name = ms.getId();
// 获得 type=SELECT
type = ms.getSqlCommandType();
//如果type=UNKNOWN
// 抛出 BindingException 异常,如果是 UNKNOWN 类型
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("Unknown execution method for: " + name);
}
}
}
private MappedStatement resolveMappedStatement(...) {
// 获得编号
//com.tian.mybatis.mapper.UserMapper.selectById
String statementId = mapperInterface.getName() + "." + methodName;
//如果有,获得 MappedStatement 对象,并返回
if (configuration.hasStatement(statementId)) {
//mappedStatements.get(statementId);
//解析配置文件时候创建并保存Map<String, MappedStatement> mappedStatements中
return configuration.getMappedStatement(statementId);
// 如果没有,并且当前方法就是 declaringClass 声明的,则说明真的找不到
} else if (mapperInterface.equals(declaringClass)) {
return null;
}
// 遍历父接口,继续获得 MappedStatement 对象
for (Class<?> superInterface : mapperInterface.getInterfaces()) {
if (declaringClass.isAssignableFrom(superInterface)) {
MappedStatement ms = resolveMappedStatement(...);
if (ms != null) {
return ms;
}
}
}
// 真的找不到,返回 null
return null;
}
//....
}
public static class MethodSignature {
private final boolean returnsMap;
private final Class<?> returnType;
private final Integer rowBoundsIndex;
//....
}
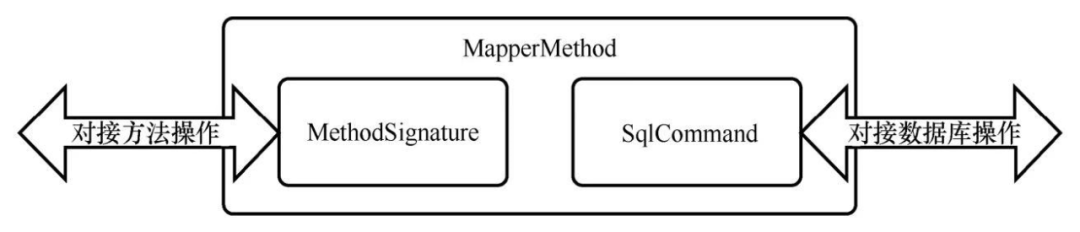
SqlCommand封装了statement ID,比如说:
com.tian.mybatis.mapper.UserMapper.selectById
和SQL类型。
public enum SqlCommandType {
UNKNOWN, INSERT, UPDATE, DELETE, SELECT, FLUSH;
}
另外,还有个属性MethodSignature方法签名,主要是封装的是返回值的类型和参数处理。这里我们debug看看这个MapperMethod对象返回的内容和我们案例中代码的关联。
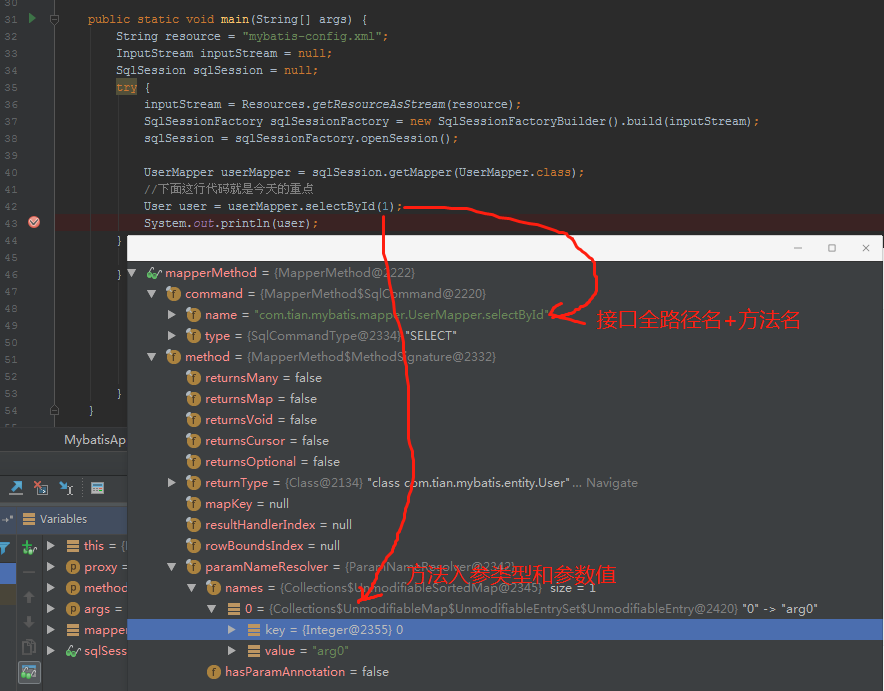
妥妥的,故事继续,我们接着看MapperMethod中execute方法。
MapperMethod.execute
上面代码中<4>处,先来看看这个方法的整体逻辑:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case SELECT:
//部分代码省略....
Object param = method.convertArgsToSqlCommandParam(args);
//本次是QUERY类型,所以这里是重点
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
return result;
}
这个方法中,根据我们上面获得的不同的type(INSERT、UPDATE、DELETE、SELECT)和返回类型:
(本文是查询,所以这里的type=SELECT)
调用convertArgsToSqlCommandParam()将方法参数转换为SQL的参数。

2.调用selectOne()方法。这里的sqlSession就是DefaultSqlSession,所以我们继续回到DefaultSqlSession中selectOne方法中。
SqlSession.selectOne方法
继续DefaultSqlSession中的selectOne()方法:
//DefaultSqlSession中
@Override
public <T> T selectOne(String statement, Object parameter) {
//这是一种好的设计方法
//不管是执行多条查询还是单条查询,都走selectList方法(重点)
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
//如果只有一条就返回第一条
return list.get(0);
} else if (list.size() > 1) {
//(开发中常见错误)方法定义的是返回一条数据,结果查出了多条数据,就会报这个异常
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
//数据库中没有数据就返回null
return null;
}
}
这里调用的是本类中selectList方法。
@Override
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//从configuration获取MappedStatement
//此时的statement=com.tian.mybatis.mapper.UserMapper.selectById
MappedStatement ms = configuration.getMappedStatement(statement);
//调用执行器中的query方法
return executor.query(...);
} catch (Exception e) {
//.....
} finally {
ErrorContext.instance().reset();
}
}
在这个方法里是根据statement从configuration对象中获取MappedStatement对象。
MappedStatement ms = configuration.getMappedStatement(statement);
在configuration中getMappedStatement方法:
//存放在一个map中的
//key是statement=com.tian.mybatis.mapper.UserMapper.selectById,value是MappedStatement
protected final Map<String, MappedStatement> mappedStatements = new StrictMap<MappedStatement>();
public MappedStatement getMappedStatement(String id) {
return this.getMappedStatement(id, true);
}
public MappedStatement getMappedStatement(String id, boolean validateIncompleteStatements) {
return mappedStatements.get(id);
}
而MappedStatement里面有xml中增删改查标签配置的所有属性,包括id、statementType、sqlSource、入参、返回值等。

到此,我们已经将UserMapper类中的方法和UserMapper.xml中的sql给彻底关联起来了。继续调用executor中query()方法:
executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
这里调用的是执行器Executor中的query()方法。
第二部分流程:
Executor.query()方法
这里的Executor对象是在调用openSession()方法时创建的。关于这一点我们在前面的文章已经说过,这里就不再赘述了。
下面来看看调用执行器的query()放的整个流程:
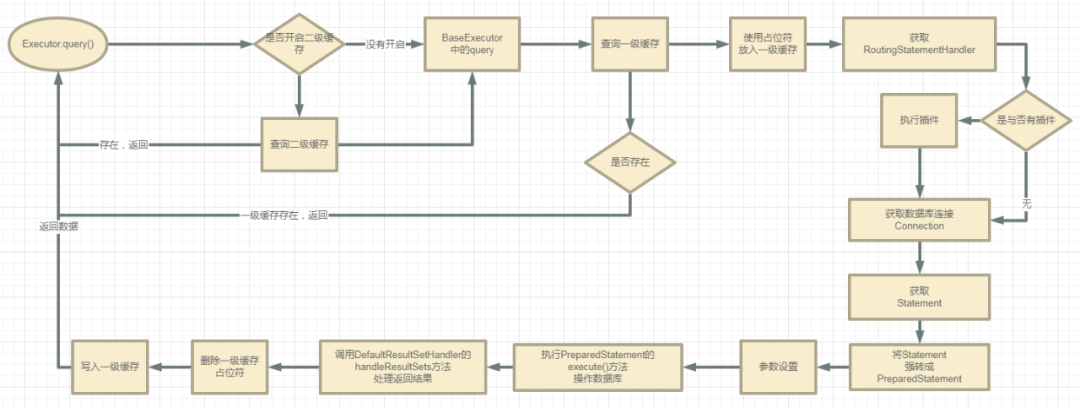
我们股市继续,看看具体源码是如何实现的。
CachingExecutor.query()
在CachingExecutor中
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
BoundSql中主要是SQL和参数:
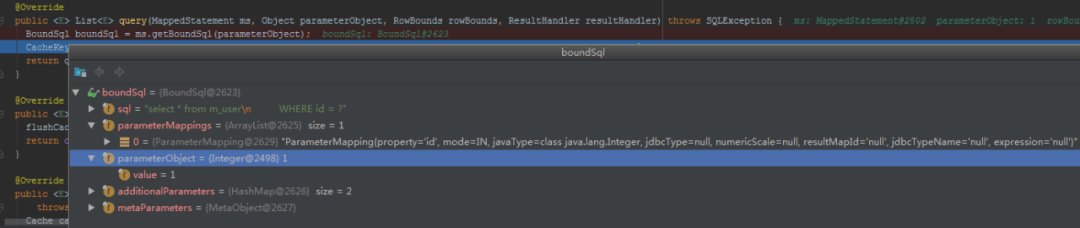
既然是缓存,我们肯定想到key-value数据结构。
下面来看看这个key生成规则:
这个二级缓存是怎么构成的呢?并且还要保证在查询的时候必须是唯一。
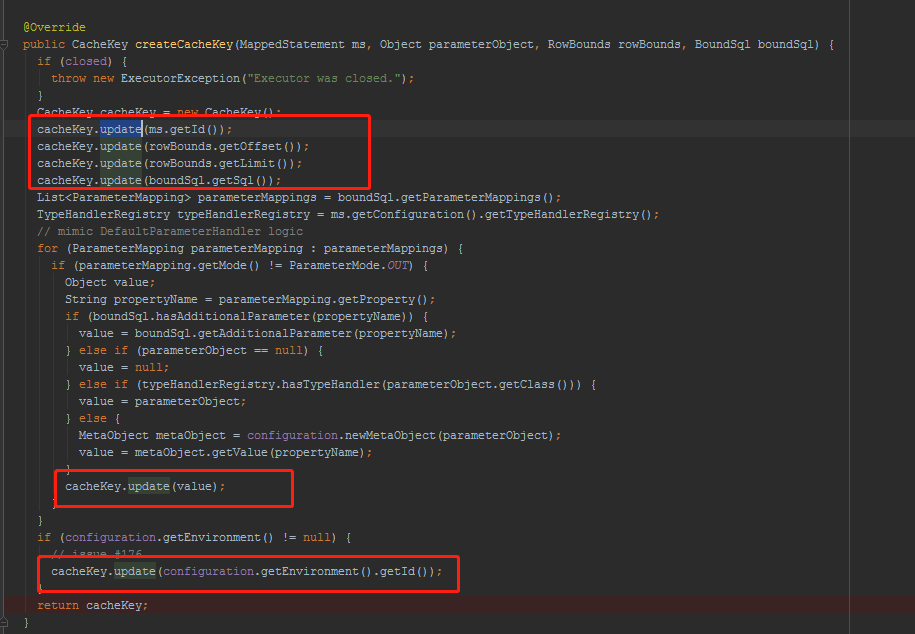
也就说,构成key主要有:
方法相同、翻页偏移量相同、SQL相同、参数相同、数据源环境相同才会被认为是同一个查询。
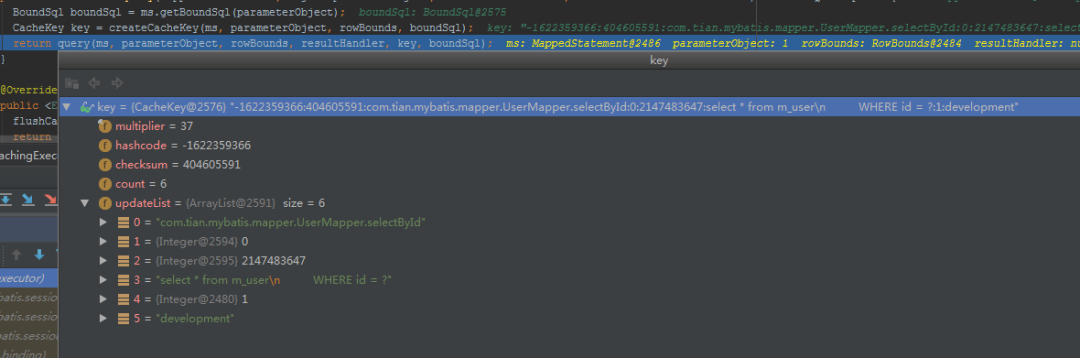
这里能说到这个层面就已经阔以了。
如果向更深入的搞,就得把hashCode这些扯进来了,请看上面这个张图里前面的几个属性就知道和hashCode有关系了。
处理二级缓存
首先是从ms中取出cache对象,判断cache对象是否为null,如果为null,则没有查询二级缓存和写入二级缓存的流程。
有二级缓存,校验是否使用此二级缓存,再从事务管理器中获取二级缓存,存在缓存直接返回。不存在查数据库,写入二级缓存再返回。
@Override
public <E> List<E> query(....)
throws SQLException {
Cache cache = ms.getCache();
//判断是否有二级缓存
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
那么这个Cache对象是什么创建的呢?
在解析UserMapper.xml时候,在XMLMapperBuilder类中的cacheElement()方法里。
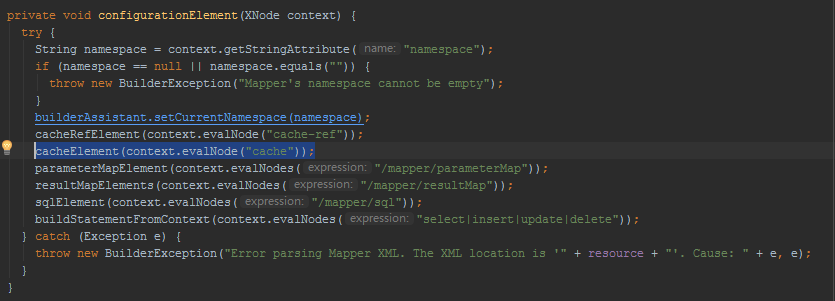
关于二级缓存相关这一块在前面文章已经说过,比如:
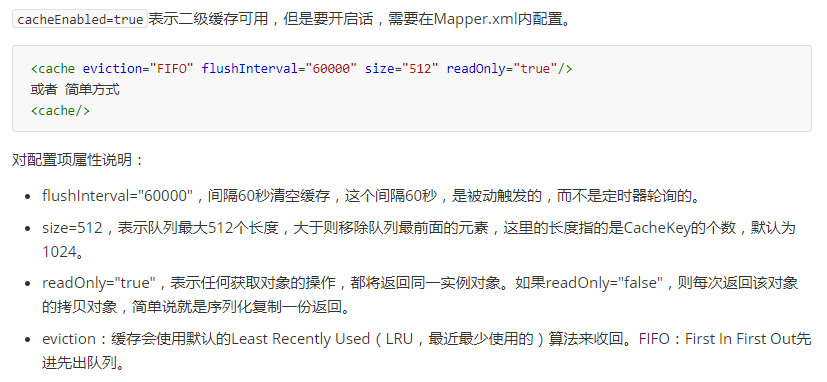
解析上面这些标签
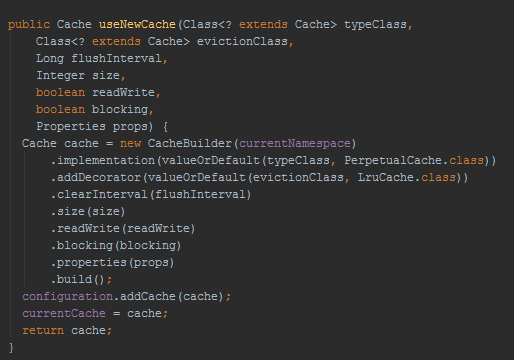
创建Cache对象:
二级缓存处理完了,就来到BaseExecutor的query方法中。

BaseExecutor,query()
第一步,清空缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
queryStack用于记录查询栈,防止地柜查询重复处理缓存。
flushCache=true的时候,会先清理本地缓存(一级缓存)。
如果没有缓存会从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
在看看这个方法的逻辑:
private <E> List<E> queryFromDatabase(...) throws SQLException {
List<E> list;
//使用占位符的方式,先抢占一级缓存。
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//删除上面抢占的占位符
localCache.removeObject(key);
}
//放入一级缓存中
localCache.putObject(key, list);
return list;
}
先在缓存使用占位符占位,然后查询,移除占位符,将数据放入一级缓存中。
执行Executor的doQuery()方法,默认使用SimpleExecutor。
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
下面就来到了SimpleExecutor中的doQuery方法。
SimpleExecutor.doQuery
@Override
public <E> List<E> doQuery(....) throws SQLException {
Statement stmt = null;
try {
//获取配置文件信息
Configuration configuration = ms.getConfiguration();
//获取handler
StatementHandler handler = configuration.newStatementHandler(....);
//获取Statement
stmt = prepareStatement(handler, ms.getStatementLog());
//执行RoutingStatementHandler的query方法
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
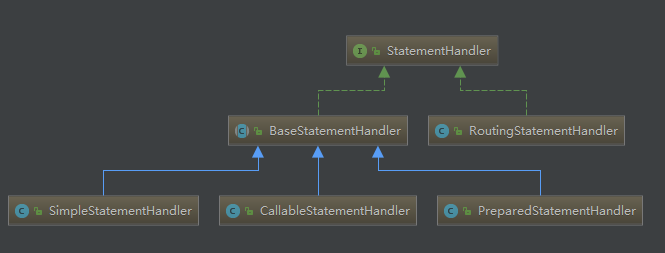
创建StatementHandler
在configuration中newStatementHandler()里,创建了一个StatementHandler对象,先得到RoutingStatementHandler(路由)。
public StatementHandler newStatementHandler() {
StatementHandler statementHandler = new RoutingStatementHandler();
//执行StatementHandler类型的插件
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
RoutingStatementHandler创建的时候是就是创建基本的StatementHandler对象。
这里会根据MapperStament里面的statementType决定StatementHandler类型。默认是PREPARED。
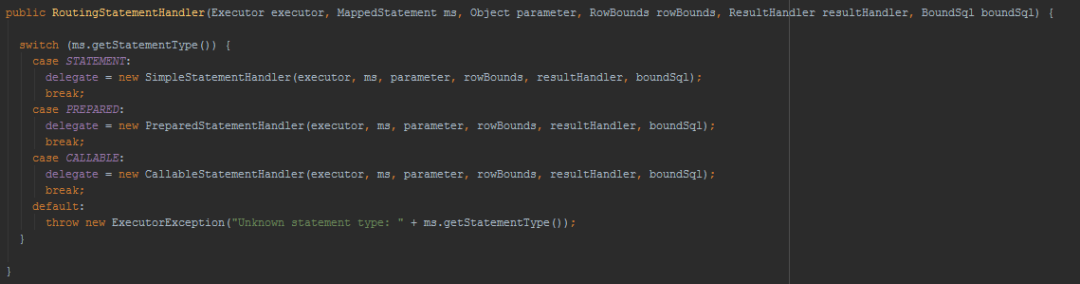
StatementHandler里面包含了处理参数的ParameterHandler和处理结果集的ResultHandler。
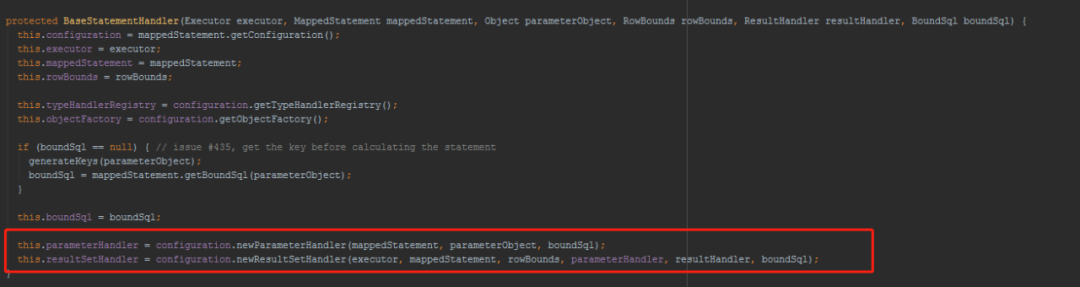
上面说的这几个对象正式被插件拦截的四大对象,所以在创建的时都要用拦截器进行包装的方法。
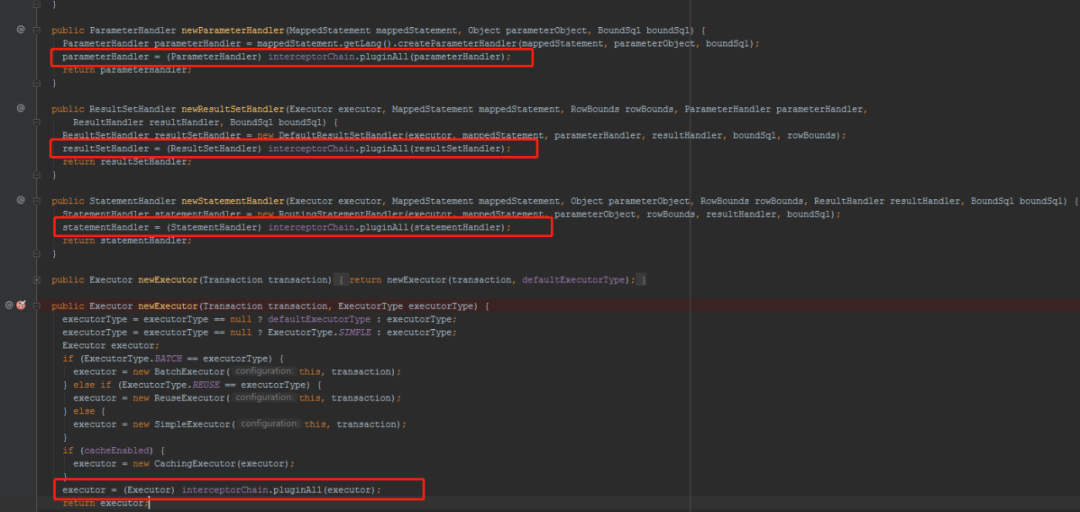
对于插件相关的,请看之前已发的插件文章:插件原理分析。
我们故事继续:
创建Statement
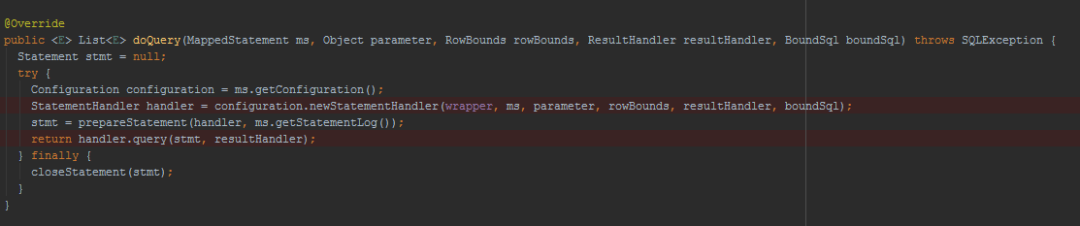
创建对象后就会执行RoutingStatementHandler的query方法。
//RoutingStatementHandler中
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
//委派delegate=PreparedStatementHandler
return delegate.query(statement, resultHandler);
}
这里设计很有意思,所有的处理都要使用RoutingStatementHandler来路由,全部通过委托的方式进行调用。
执行SQL
然后执行到PreparedStatementHandler中的query方法。
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
//JDBC的流程了
ps.execute();
//处理结果集,如果有插件代理ResultHandler,会先走到被拦截的业务逻辑中
return resultSetHandler.handleResultSets(ps);
}
看到了ps.execute(); 表示已经到JDBC层面了,这时候SQL就已经执行了。后面就是调用DefaultResultSetHandler类进行结果集处理。
到这里,SQL语句就执行完毕,并将结果集赋值并返回了。
总算搞完把Mybatis主干源码掠了一遍,松口气~,能看到这里,证明小伙伴也是蛮用心的,辛苦了。越努力越幸福!
建议抽时间,再次debug,还有就是画画类之间的关系图,还有就是Mybatis中设计模式好好回味回味。

总结
从调用userMapper的selectById()方法开始,到方法和SQL关联起来,参数处理,再到JDBC中SQL执行。
完整流程图:
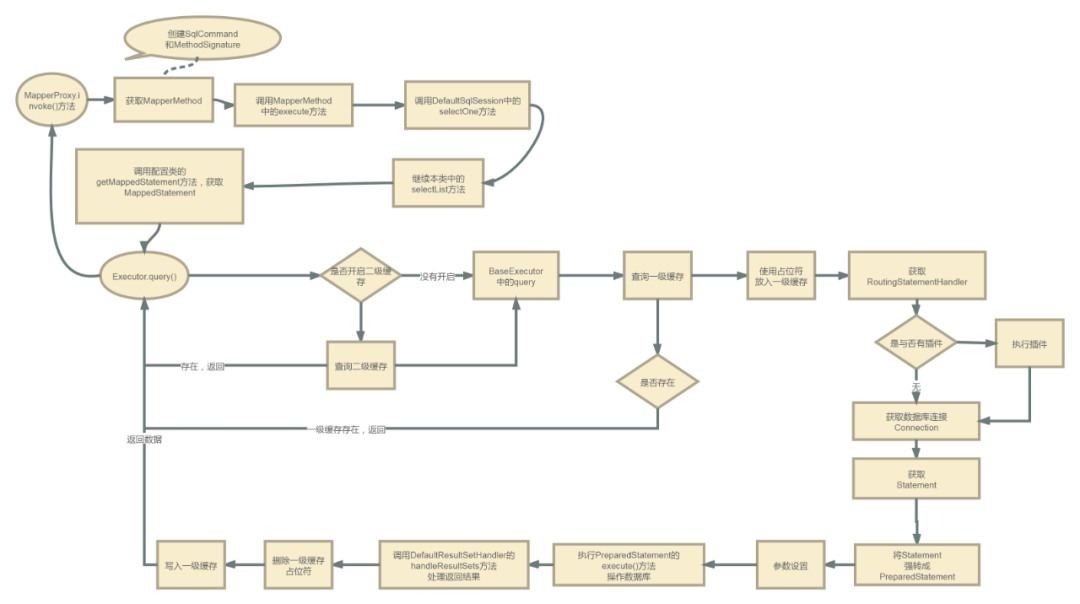
感兴趣的小伙伴,可以对照着这张流程图就行一步一步的debug。
记着:努力的人,世界不会亏待你的。

- SQL中两个关联表批量更新数据的方法
- mybatis中的执行增删改查sql的所有方法
- 1 --SQLite 怎么关联起来
- 毕业3年的程序员,怎么进BAT | 12000字揭秘阿里连环炮面试(附开发手册)
- 在项目中,多个方法会调用相同的sql语句,怎么解决各个方法的不同sql查询,解决冲突。
- SSM-MyBatis-08:Mybatis中SqlSession的commit方法为什么会造成事物的提交
- adt怎么关联第三方jar包源码的方法
- 【MyBatis学习11】关联关系collection:1对多关联的两种方法
- 在C#中把两个DataTable连接起来,相当于Sql的Inner Join方法
- Mybatis之SqlSessionFactoryBean源码初步解析(二)主写怎么解析resultMap以及查询语句
- 在excel中把一些数据相关联起来的方法
- 毕业3年的程序员,怎么进BAT | 12000字揭秘阿里连环炮面试(附开发手册)
- Mybatis通过一条SQL查出关联的对象
- 设置在控制台打印 MyBatis 动态生成 SQL 语句的方法
- ling to sql 中出现错误“已有打开的与此 Command 相关联的 DataReader,必须首先将它关闭”原因及解决方法
- 博为峰JavaEE技术文章 ——MyBatis Provider之@SelectProvider SQL方法
- 程序里的SQL、mybatis下的查询慢的优化方法(非SQL语句优化)
- sublime text 3中php文件与浏览器关联起来的方法。
- 怎么编写mybatis.xml文件,实现sql增删改查
- mybatis中sql语句传入多个参数方法