Flink实战,实时流量统计 TOPN访问URL
2021-01-03 17:09
896 查看
跟 https://blog.51cto.com/mapengfei/2580330 类似场景,来从Nginx、Apache等web服务器的日志中读取数据,实时统计出来访问热度最高的TOPN访问URL,并且要确保数据乱序的处理,lag等情况下,还要确认数据的准确性
目标:
从log文件中读取数据(也可以参考上一篇从kakfa中),取http 的method为get的请求,并且把静态文件访问过滤掉,进行实时统计 实现: 1、读取文件 2、做过滤,method=get url不为静态信息 3、生成一个滑动窗口,大小10分钟,每次滑动5s,watermask 5s(为了保险允许数据延迟,allowedLateness 1分钟) 4、进行聚合统计分析排序输出
准备日志文件:
在resource目录下生成一个nginx.log里面内容: 1.1.1.1 - - 23/03/2020:05:06:03 GET /mapengfei/2580330 1.1.1.1 - - 23/03/2020:05:06:05 GET /mapengfei/2572888 1.1.1.3 - - 24/03/2020:05:06:05 GET /mapengfei/2572888
代码:
新建一个HotUrlAnalysis.scal的object文件
/*
*
* @author mafei
* @date 2021/1/3
*/
package com.mafei.hotUrlAnalysis
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import java.sql.Timestamp
import java.text.SimpleDateFormat
import scala.collection.mutable.ListBuffer
// 定义要提取的数据格式
case class NginxLog(clientIp: String, userId: String,ts:Long,method:String,url:String)
// 定义窗口聚合结果样例类
case class UrlViewCount(url: String, windowEnd: Long, count: Long)
object HotUrlAnalysis {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //定义取事件时间
env.setParallelism(1) //防止乱序
//1、从文件中读取数据
val inputStream = env.readTextFile("/opt/java2020_study/UserBehaviorAnalysis/HotUrlAnalysis/src/main/resources/nginx.log")
val dataStream = inputStream
.map(data=>{
val splitResult = data.split(" ") //因为日志格式是以空格分隔的
//因为日志中格式是字符串的,我们需要的是13位毫秒的时间戳,所以需要转换下
val dateFormatConvert = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss") // 格式: 天/月/年:时:分:秒
val ts = dateFormatConvert.parse(splitResult(3)).getTime
NginxLog(splitResult(0), splitResult(1),ts,splitResult(4), splitResult(5))
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[NginxLog](Time.seconds(5)) { //这里设置watermark延迟5秒
override def extractTimestamp(t: NginxLog): Long = t.ts //指定时间事件的时间戳
})
//开窗聚合,排序输出
var aggStream = dataStream
.filter(_.method == "GET")//过滤下,只要method是get请求的数据
.filter(data=>{
val pattern= "^((?!\\.(css|js)$).)*$".r
(pattern findFirstIn data.url).nonEmpty
}) //再过滤下,像css/js之类的url不算
// .keyBy("url") //这样子写返回的是个元组类型
.keyBy(_.url)
.timeWindow(Time.minutes(10), Time.seconds(5))
.allowedLateness(Time.minutes(1)) //可以watermark时间设置小一点,到时间先输出,但是窗口先不关,等到allowedLateness的时间了再关
.sideOutputLateData(new OutputTag[NginxLog]("late")) //加一个侧输出流,为了防止数据的乱序超过了1分钟
.aggregate(new PageCountAgg(),new PageViewCountResult())
val resultStream = aggStream
.keyBy(_.windowEnd) //按照结束时间进行分组,收集当前窗口内的,取一定时间内的数据
.process(new TopUrl(10))
resultStream.print()
aggStream.getSideOutput(new OutputTag[NginxLog]("late")).print("这是1分钟之后的延迟数据。。。。")
env.execute("执行热门url访问统计")
}
}
class PageCountAgg() extends AggregateFunction[NginxLog,Long,Long]{
override def createAccumulator(): Long = 0L
override def add(in: NginxLog, acc: Long): Long = acc +1
override def getResult(acc: Long): Long = acc
override def merge(acc: Long, acc1: Long): Long = acc+acc1
}
class PageViewCountResult() extends WindowFunction[Long,UrlViewCount,String,TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[UrlViewCount]): Unit = {
out.collect(UrlViewCount(key,window.getEnd,input.iterator.next()))
}
}
/**
* 输入参数
* K: 排序的字段类型,这里是WindowEnd时间戳,所以是Long类型
* I: 输入的数据,是上一步PageViewCountResult输出的类型,所以是UrlViewCount
* O: 输出的类型,这个自己定义,看实际情况,这里直接打印了,所以String
*/
class TopUrl(topN:Int) extends KeyedProcessFunction[Long,UrlViewCount,String]{
lazy val urlViewCountListState: ListState[UrlViewCount] = getRuntimeContext.getListState(new ListStateDescriptor[UrlViewCount]("urlViewCountList", classOf[UrlViewCount]))
override def processElement(i: UrlViewCount, context: KeyedProcessFunction[Long, UrlViewCount, String]#Context, collector: Collector[String]): Unit = {
urlViewCountListState.add(i) //把每次的结果都加到自定义的list里头,方便后边做排序
context.timerService().registerEventTimeTimer(i.windowEnd) //注册一个定时器,在窗口关闭的时候触发
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, UrlViewCount, String]#OnTimerContext, out: Collector[String]): Unit = {
//为了方便排序,定义另一个ListBuffer,保存ListState的所有数据
val allPageListBuffer: ListBuffer[UrlViewCount] = ListBuffer()
val iter = urlViewCountListState.get().iterator()
while (iter.hasNext){
allPageListBuffer += iter.next()
}
//清空ListState的数据,已经放到urlViewCountListState 准备计算了,等下次触发就应该是新的了
urlViewCountListState.clear()
// 先按照count,从大到小排序,然后再取前N个
val sortItemViewCounts = allPageListBuffer.sortBy(_.count)(Ordering.Long.reverse).take(topN)
//格式化输出数据:
val result : StringBuilder = new StringBuilder
result.append("当前窗口的结束时间:\t").append(new Timestamp(timestamp)).append("\n")
//遍历结果列表中的每个ItemViewCount , 输出到一行
for(i <- sortItemViewCounts.indices){
val currentItemViewCount = sortItemViewCounts(i)
result.append("Top").append(i+1).append("\t")
.append("URL = ").append(currentItemViewCount.url).append("\t")
.append("访问量: ").append(currentItemViewCount.count).append("\n")
}
result.append("---------------------------------------\n\n\n")
Thread.sleep(1000)
out.collect(result.toString())
}
}
代码结构及输出效果:
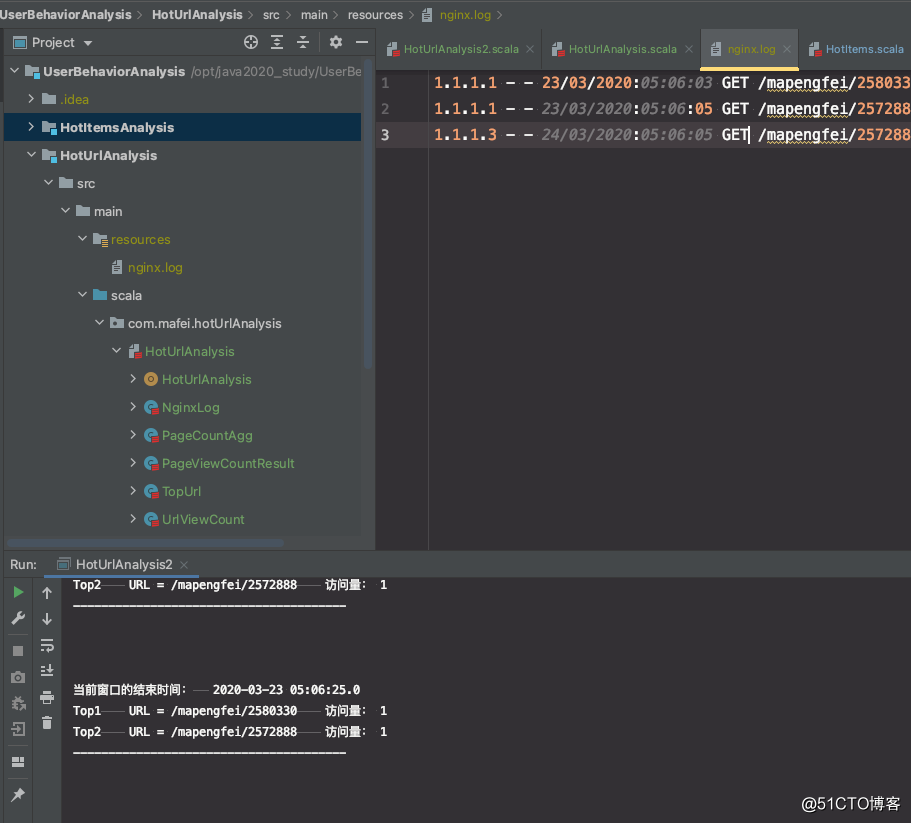
问题点
在数据乱序的情况下,虽然能全部输出,但有2个问题点上面的代码,
一个是在TopUrl 中保存数据用的是list,在滑动窗口先到达,延迟数据过会儿到达的时候,数据会重复输出,也就是url会出现2次
第二个问题是在第二次延迟输出的时候,本来应该加上之前的数据,但是没有,而是重新从0开始计算
最终效果:
| URL | 出现次数 | 出现原因 |
|---|---|---|
| /a | 3 | 在5秒内统计数据输出的 |
| /a | 1 | allowedLateness延迟数据达到产生的 |
解决办法:
从list改为map,并且因为之前每次都会清空list,可以改为等真正的窗口结束后再清空就可以了
主要改动的地方:
processElement 和onTimer这2个方法
/*
*
* @author mafei
* @date 2021/1/3
*/
package com.mafei.hotUrlAnalysis
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, MapState, MapStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import java.sql.Timestamp
import java.text.SimpleDateFormat
import scala.collection.mutable.ListBuffer
/**
* import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.api.java.tuple.{Tuple, Tuple1}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.util.Collector
import java.sql.Timestamp
import java.util.Properties
import scala.collection.mutable.ListBuffer
* @param clientIp
* @param userId
* @param ts
* @param method
* @param url
*/
// 定义要提取的数据格式
case class NginxLog2(clientIp: String, userId: String,ts:Long,method:String,url:String)
// 定义窗口聚合结果样例类
case class UrlViewCount2(url: String, windowEnd: Long, count: Long)
object HotUrlAnalysis2 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //定义取事件时间
env.setParallelism(1) //防止乱序
//1、从文件中读取数据
val inputStream = env.readTextFile("/opt/java2020_study/UserBehaviorAnalysis/HotUrlAnalysis/src/main/resources/nginx.log")
val dataStream = inputStream
.map(data=>{
val splitResult = data.split(" ") //因为日志格式是以空格分隔的
//因为日志中格式是字符串的,我们需要的是13位毫秒的时间戳,所以需要转换下
val dateFormatConvert = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss") // 格式: 天/月/年:时:分:秒
val ts = dateFormatConvert.parse(splitResult(3)).getTime
NginxLog2(splitResult(0), splitResult(1),ts,splitResult(4), splitResult(5))
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[NginxLog2](Time.seconds(5)) { //这里设置watermark延迟5秒
override def extractTimestamp(t: NginxLog2): Long = t.ts //指定时间事件的时间戳
})
//开窗聚合,排序输出
var aggStream = dataStream
.filter(_.method == "GET")//过滤下,只要method是get请求的数据
.filter(data=>{
val pattern= "^((?!\\.(css|js)$).)*$".r
(pattern findFirstIn data.url).nonEmpty
}) //再过滤下,像css/js之类的url不算
// .keyBy("url") //这样子写返回的是个元组类型
.keyBy(_.url)
.timeWindow(Time.minutes(10), Time.seconds(5))
.allowedLateness(Time.minutes(1)) //可以watermark时间设置小一点,到时间先输出,但是窗口先不关,等到allowedLateness的时间了再关
.sideOutputLateData(new OutputTag[NginxLog2]("late")) //加一个侧输出流,为了防止数据的乱序超过了1分钟
.aggregate(new PageCountAgg2(),new PageViewCountResult2())
val resultStream = aggStream
.keyBy(_.windowEnd) //按照结束时间进行分组,收集当前窗口内的,取一定时间内的数据
.process(new TopUrl2(10))
resultStream.print()
aggStream.getSideOutput(new OutputTag[NginxLog2]("late")).print("这是1分钟之后的延迟数据。。。。")
env.execute("执行热门url访问统计")
}
}
class PageCountAgg2() extends AggregateFunction[NginxLog2,Long,Long]{
override def createAccumulator(): Long = 0L
override def add(in: NginxLog2, acc: Long): Long = acc +1
override def getResult(acc: Long): Long = acc
override def merge(acc: Long, acc1: Long): Long = acc+acc1
}
class PageViewCountResult2() extends WindowFunction[Long,UrlViewCount2,String,TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[UrlViewCount2]): Unit = {
out.collect(UrlViewCount2(key,window.getEnd,input.iterator.next()))
}
}
/**
* 输入参数
* K: 排序的字段类型,这里是WindowEnd时间戳,所以是Long类型
* I: 输入的数据,是上一步PageViewCountResult2输出的类型,所以是UrlViewCount2
* O: 输出的类型,这个自己定义,看实际情况,这里直接打印了,所以String
*/
class TopUrl2(topN:Int) extends KeyedProcessFunction[Long,UrlViewCount2,String]{
lazy val UrlViewCount2MapState: MapState[String,Long] = getRuntimeContext.getMapState(new MapStateDescriptor[String,Long]("UrlViewCount2Map",classOf[String],classOf[Long]))
override def processElement(i: UrlViewCount2, context: KeyedProcessFunction[Long, UrlViewCount2, String]#Context, collector: Collector[String]): Unit = {
UrlViewCount2MapState.put(i.url,i.count)
context.timerService().registerEventTimeTimer(i.windowEnd) //注册一个定时器,在窗口关闭的时候触发
//再另外注册一个定时器,1分钟之后触发,这时窗口已经彻底关闭,不再有聚合结果输出,可以清空状态
context.timerService().registerEventTimeTimer(i.windowEnd + 60000L)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, UrlViewCount2, String]#OnTimerContext, out: Collector[String]): Unit = {
/**
* 使用mapState的方式
*/
//判断定时器触发时间,如果已经是窗口结束时间1分钟之后,那么直接清空状态
if(timestamp == ctx.getCurrentKey+60000L){
UrlViewCount2MapState.clear()
return
}
val allUrlViewCount2sBuffer: ListBuffer[(String,Long)] = ListBuffer()
val iter = UrlViewCount2MapState.entries().iterator()
while (iter.hasNext){
val entry = iter.next()
allUrlViewCount2sBuffer += ((entry.getKey, entry.getValue))
}
// 先按照count,从大到小排序,然后再取前N个
val sortItemViewCounts = allUrlViewCount2sBuffer.sortBy(_._2)(Ordering.Long.reverse).take(topN)
//格式化输出数据:
val result : StringBuilder = new StringBuilder
result.append("当前窗口的结束时间:\t").append(new Timestamp(timestamp)).append("\n")
//遍历结果列表中的每个ItemViewCount , 输出到一行
for(i <- sortItemViewCounts.indices){
val currentItemViewCount = sortItemViewCounts(i)
result.append("Top").append(i+1).append("\t")
.append("URL = ").append(currentItemViewCount._1).append("\t")
.append("访问量: ").append(currentItemViewCount._2).append("\n")
}
result.append("---------------------------------------\n\n\n")
Thread.sleep(1000)
out.collect(result.toString())
}
}

相关文章推荐
- Flink之实时统计指定时间段内热门商品的TopN(双11一小时内的热门品牌排行榜)
- [Scala] Flink项目实时流量统计(二)
- Spark SQL 笔记(13)——实战网站日志分析(3)按照流量统计TopN
- Flink统计电商ICON导航流量实战
- Hadoop链式MapReduce、多维排序、倒排索引、自连接算法、二次排序、Join性能优化、处理员工信息Join实战、URL流量分析、TopN及其排序、求平均值和最大最小值、数据清洗ETL、分析气
- awk日志分析 取出访问最多的IP,URL,以及五分钟内的访问流量
- 如何统计servlet一次访问对带宽流量的占用
- 某最新《大数据实时流统计实战》
- ASP.net中网站访问量统计方法代码(在线人数,本月访问,本日访问,访问流量,累计访问)
- Kafka项目实战-用户日志上报实时统计之分析与设计
- 网络分析shell脚本(实时流量+连接统计)
- Flink 零基础实战教程:如何计算实时热门商品
- 一个强大的网络分析shell脚本分享(实时流量、连接统计)
- Spark企业级实战项目:道路交通实时流量监控预测系统
- 统计apache日志所有ip的访问次数和流量
- Vue中使用matomo进行访问流量统计的实现
- MapReduce实战练习一:手机流量统计
- Spark Streaming从Kafka中获取数据,并进行实时单词统计,统计URL出现的次数
- 大数据实时流统计实战
- 广告流量实时统计 scala版本 过滤黑名单 统计各省市实时广告用户点击量