prometheus + grafana 对flink 进行监控
2020-12-18 09:37
1531 查看
prometheus + grafana 对flink 进行监控
标签(空格分隔): flink系列
一:flink监控简介
二:Flink的Metric架构
- 三: prometheus + grafana 的 对 flink 的监控部署构建
一:flink监控简介
1.1 前言
Flink提供的Metrics可以在Flink内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的Task日志,比如作业很大或者有很多作业的情况下,该如何处理?此时Metrics可以很好的帮助开发人员了解作业当前状况。对于很多大中型企业来讲,我们对进群的作业进行管理时,更多的是关心作业精细化实时运行状态。例如,实时吞吐量的同比环比、整个集群的任务运行概览、集群水位,或者监控利用 Flink 实现的 ETL 框架的运行情况等,这时候就需要设计专门的监控系统来监控集群的任务作业情况。
二: Flink的Metric架构
2.1 flink metric
Flink Metrics是Flink实现的一套运行信息收集库,我们不但可以收集Flink本身提供的系统指标,比如CPU、内存、线程使用情况、JVM垃圾收集情况、网络和IO等,还可以通过继承和实现指定的类或者接口打点收集用户自定义的指标。 通过使用Flink Metrics我们可以轻松地做到: • 实时采集Flink中的Metrics信息或者自定义用户需要的指标信息并进行展示; • 通过Flink提供的Rest API收集这些信息,并且接入第三方系统进行展示。
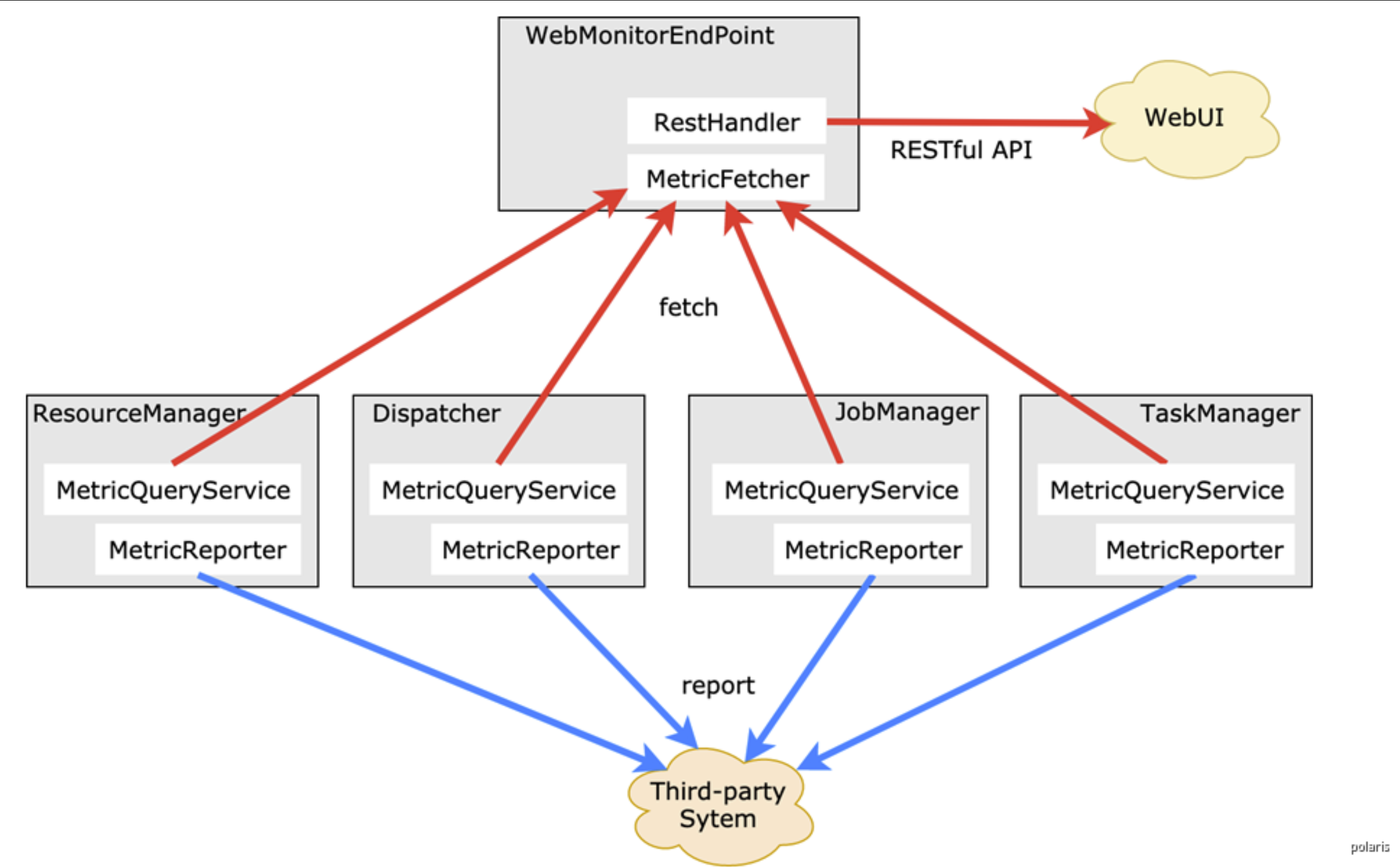
2.2 监控架构
从Flink Metrics架构来看,指标获取方式有两种。一是REST-ful API,Flink Web UI中展示的指标就是这种形式实现的。二是reporter,通过reporter可以将metrics发送给外部系统。Flink内置支持JMX、Graphite、Prometheus等系统的reporter,同时也支持自定义reporter。 由于Flink Web UI所提供的metrics数量较少,也没有时序展示,无法满足实际生产中的监控需求。Prometheus+Grafana是业界十分普及的开源免费监控体系,上手简单,功能也十分完善。
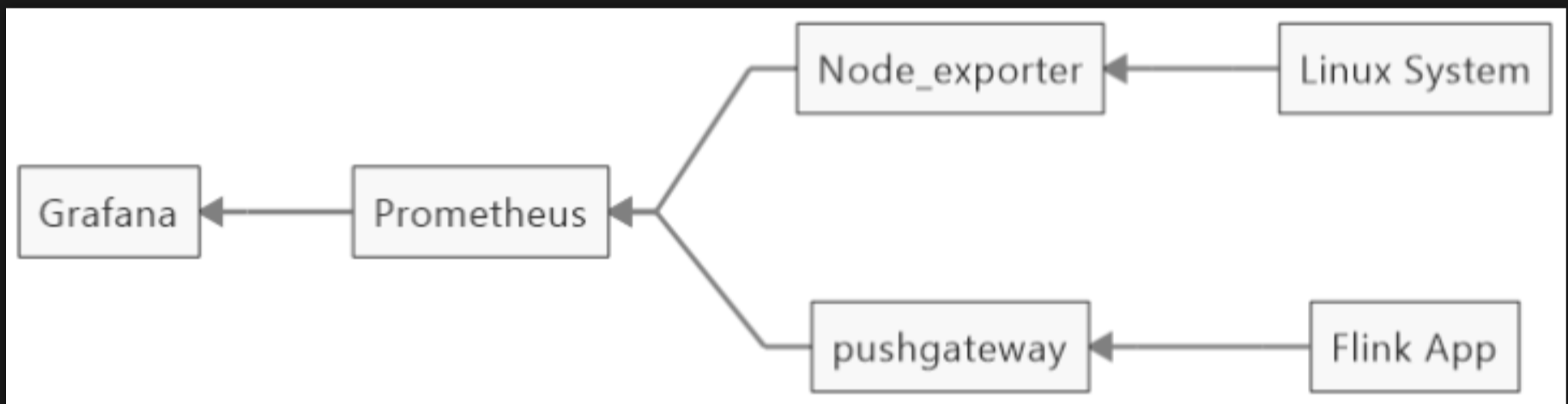
三:prometheus + grafana 的 对 flink 的监控部署构建
3.1 安装prometheus
Prometheus本身也是一个导出器(exporter),提供了关于内存使用、垃圾收集以及自身性能 与健康状态等各种主机级指标。 prometheus官网下载址: https://prometheus.io/download/ wget https://github.com/prometheus/prometheus/releases/download/v2.21.0/prometheus-2.21.0.linux-amd64.tar.gz # tar zxvf prometheus-2.21.0.linux-amd64.tar.gz # mv prometheus-2.21.0.linux-amd64 /usr/local/prometheus # chmod +x /usr/local/prometheus/prom* # cp -rp /usr/local/prometheus/promtool /usr/bin/
3.2 配置prometheus
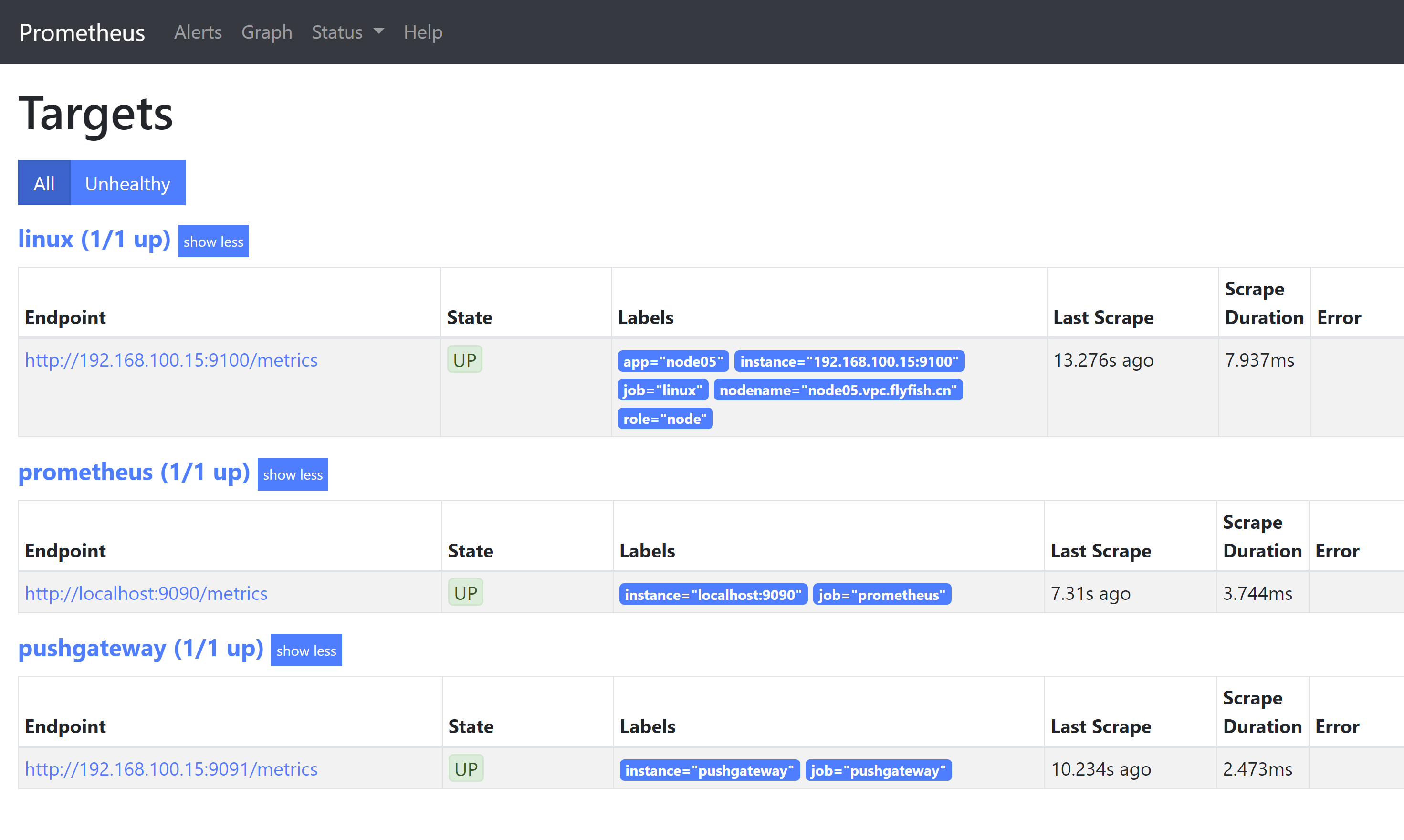
最后 加上pushgateway 收集: 此处将pushgateway 与 prometheus 安装在一台机器上面 - job_name: 'linux' static_configs: - targets: ['192.168.100.15:9100'] labels: app: node05 nodename: node05.vpc.flyfish.cn role: node - job_name: 'pushgateway' static_configs: - targets: ['192.168.100.15:9091'] labels: instance: 'pushgateway'
prometheus 的开机启动: cat > /usr/lib/systemd/system/prometheus.service <<EOF [Unit] Description=Prometheus [Service] ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml -- storage.tsdb.path=/usr/local/prometheus/data --web.enable-lifecycle --storage.tsdb.retention.time=180d Restart=on-failure [Install] WantedBy=multi-user.target EOF --- #service prometheus start #chkconfig prometheus on
3.3 安装 prometheus 的node_exporter 与 pushgateway 的插件
node_exporter : #tar -zxvf node_exporter-1.0.1.linux-amd64.tar.gz #mv node_exporter-1.0.1.linux-amd64 /usr/local/node_exporter #/usr/local/node_exporter/node_exporter &
pushgateway: #tar -zxvf pushgateway-1.2.0.linux-amd64.tar.gz #mv pushgateway-1.2.0.linux-amd64 /usr/local/pushgateway/ # /usr/local/pushgateway/pushgateway &
###3.4 flink metric 的配置
flink-conf.yaml 到最后加上 ---- metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter metrics.reporter.promgateway.host: 192.168.100.15 metrics.reporter.promgateway.port: 9091 metrics.reporter.promgateway.jobName: pushgateway metrics.reporter.promgateway.randomJobNameSuffix: true metrics.reporter.promgateway.deleteOnShutdown: true ---- 然后同步所有flink的 works 节点
重启flink 的集群 ./stop-cluster.sh ./start-cluster.sh
3.4.1 打开pushgateway
3.4.2 prometheus 页面
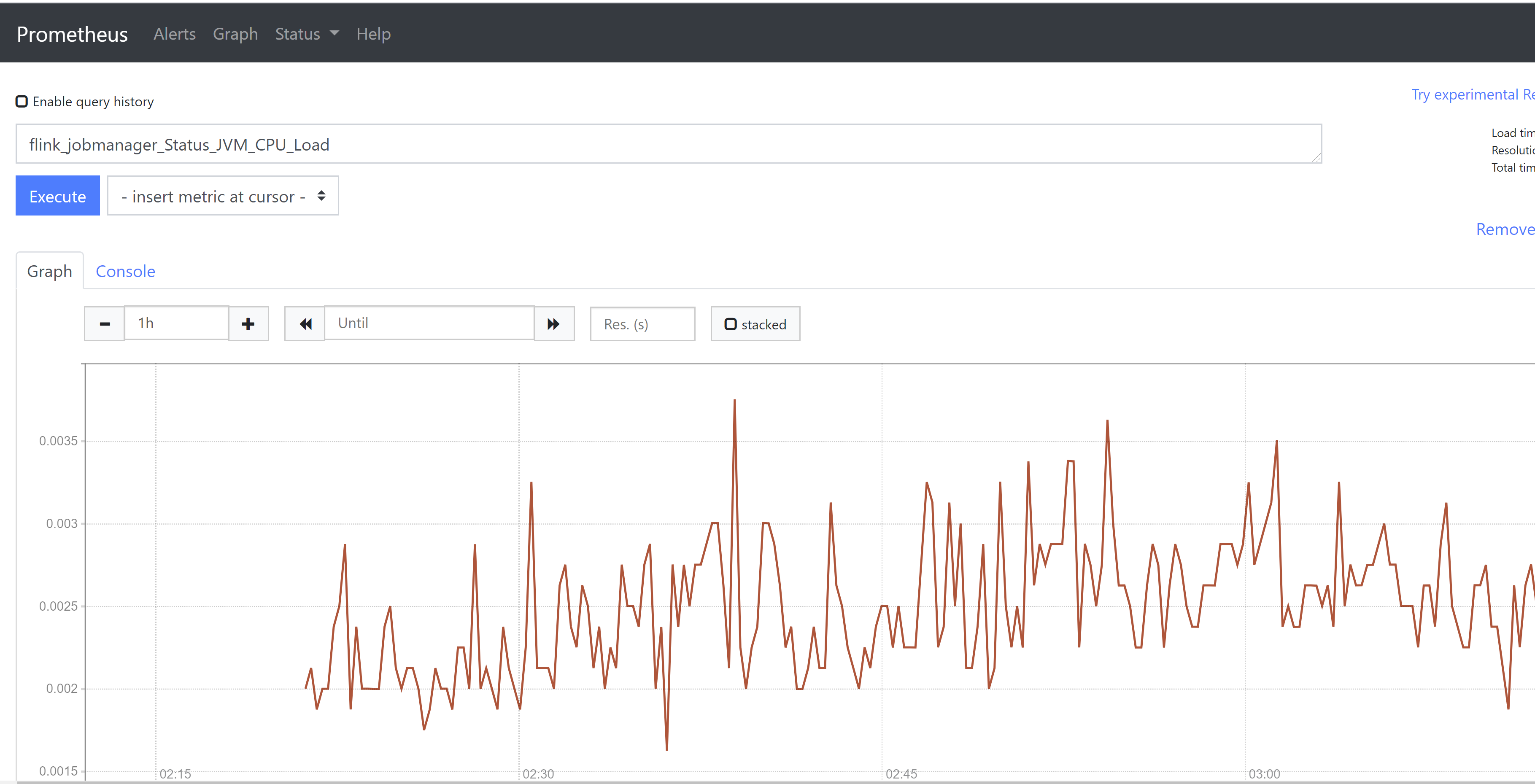
3.4.5 关于 grafana 的 prometheus 的Datasources
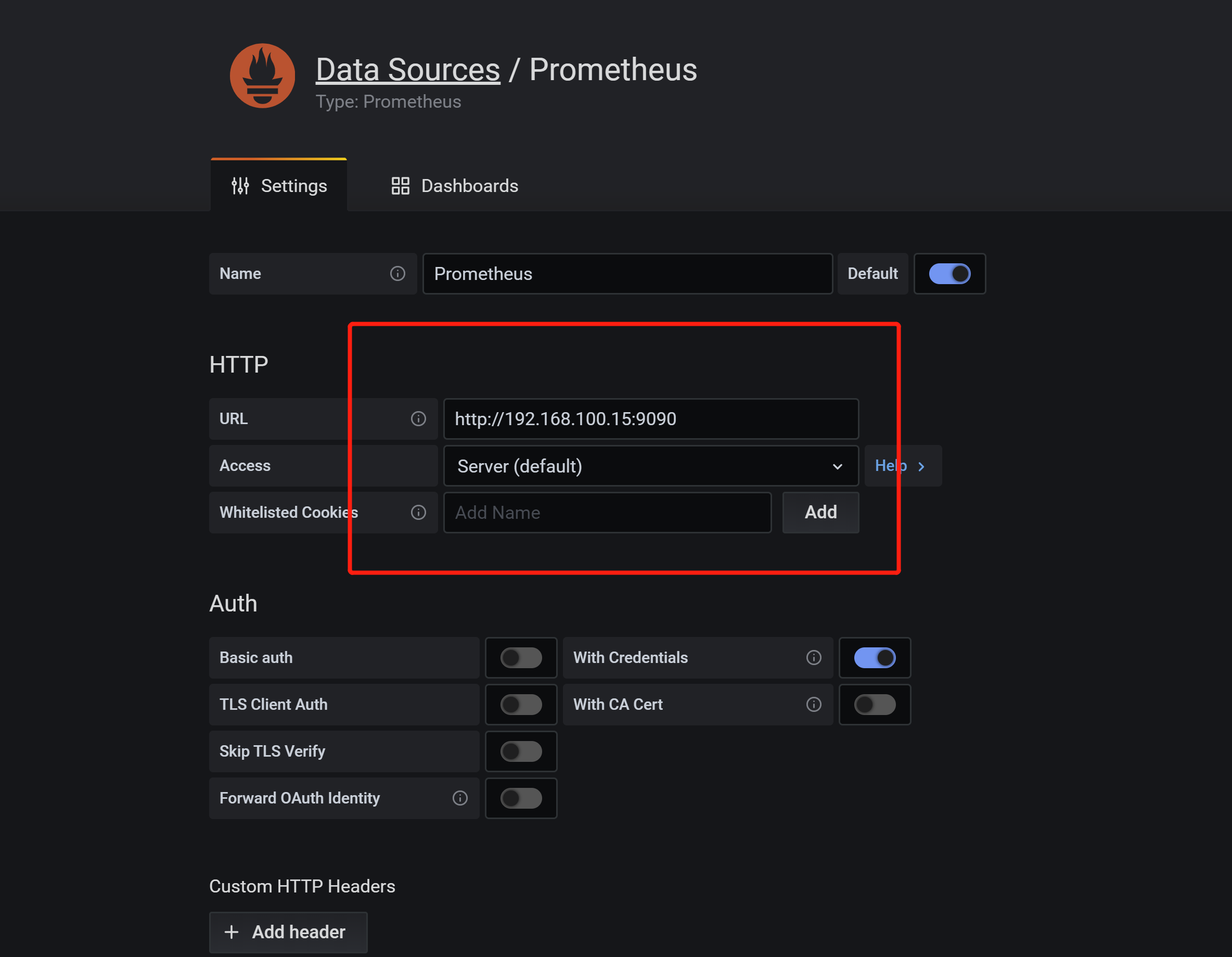

相关文章推荐
- 基于端口和Flink CEP进行恶意登录监控
- TPTP 进行性能监控[转]
- Zabbix对mongodb进行性能监控
- .net core使用App.Metrics+InfluxDB+Grafana进行APM监控
- 手机移动终端与PC进行音视频聊天和监控的开发 .
- SQL Server 手把手教你使用profile进行性能监控
- 监控linux系统某文件的生成,并进行另一个脚本
- AIX下用nmon进行监控和分析实战
- jvm监控工具jconsole进行远程监控配置
- 使用Shell脚本对Linux系统和进程资源进行监控
- 利用Supervisor进行进程状态监控和报警
- 给校园网络进行流量监控和流量分析
- Cacti与Nagios进行网络监控的区别
- 使用munin画图软件进行监控
- nagios通过脚本对系统进行定制监控
- 使用shell脚本进行服务器系统监控——文件系统监控(4)
- linux系统看系统性能进行性能监控的几大命令行
- 使用shell脚本进行服务器系统监控——文件系统监控(5)
- 对基于JUnit和Ant的测试用例执行过程使用Kieker(AspectJ)进行监控的方法
- linux通过cacti监控apache通过飞信邮件进行报警