ITIL 4 讲解:Event,Incident 和 Crisis, 流程如何界定?
这个话题源自客户的提问:如果监控报告发生了异常,
1. 运维团队处理了,这算是Even还是Incident管理流程?
2. 如果没有处理,异常越来越严重(当然处理的时候也有可能问题越来越严重),发生了危机,是属于Incident的管理流程还是需要建立一个新的流程(Crisis Management)?
其实这一场景的管理,在ITIL 4中,划分为三个实践: 监控和事态管理(Monitoring and Event Management ),事件管理(Incident Management)和服务连续性管理(Service Continuity Management)。在回答这个问题之前,我们先看看这三个实践的范围和流程。这里先要说明,由于翻译的问题,Incident Management从ITIL V3,一直翻译成事件管理,其实我认为翻译成故障管理更合适。为了避免歧义和不纠结翻译的问题,下文都用英语单词Event, Incident描述。
区分三个关键词语
事态 Event: 对服务或其他配置项(CI)的管理具有重要意义的任何状态更改
事件 Incidnet: 服务的意外中断或服务质量的降低
灾难 Disaster: 对组织造成重大损失或重大损失的突发性意外事件。要将事件归类为灾难,该事件必须符合组织预定义的某些业务影响标准
从ITIL 4给出的定义来看,他们之间的关系应该是:
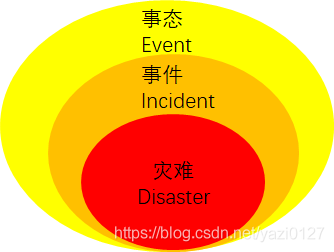
Event是由监控系统反映出来的关于CI项的状态变化,产生的信息有可能是一个通知,有可能是潜在故障,需要我们关注,有可能是故障,也有可能是重大故障或者灾难。对于Event的管理,需要我们去定义Event的类型,告警的阈值,Event的优先级和Incident优先级的对应,以及何时触发Incident Management。
Incident就是我们理解的故障,生产系统的异常情况,有可能产生中断,也有可能未产生中断。
Disaster是灾难,比如数据中心全部中断服务,业务系统大面积瘫痪。企业需要提前制定危机工作小组,以及确定沟通计划,比如上报监管机构,开展企业危机公关处理程序等等。
对比三个实践的范围和流程
| 实践 | 目的 | 范围 |
| 监控和事态管理 | 目的是系统地观察服务和服务组件,并记录和报告确定为事态状态变化。此实践可识别基础设施、服务、业务流程和信息安全事件并确定其优先级,并建立对这些事件的适当响应,包括对可能导致潜在故障或事件的情况作出响应。 | 涵盖了组织服务管理的所有方面,这些方面需要控制并且可以自动化。这包括: ●确定和优化监控范围 ●实施和维护持续监控 ●建立和维护事件识别、分类和处理规则 ●实施流程和自动化工具,以实施规定的事件管理规则 ●根据商定和实施的规则和流程持续处理事件 ●以商定的形式向相关利益相关者提供有关受监控服务和资源的当前和历史状态的信息。 |
| 事件管理 | 事件管理实践的目的是通过尽快恢复正常的服务操作,将事件的负面影响降至最低。 | 事件管理实践的范围包括: ●检测和登记事件 ●诊断和调查事故 ●将受影响的服务和CI恢复到商定的质量 ●管理事件记录 ●在事件生命周期内与相关利益相关者沟通 ●审查事件,并在解决后开始改进服务和事件管理实践。 |
| 服务连续性管理 | 服务连续性管理做法的目的是确保在发生灾难时,服务的可用性和性能保持在足够的水平。该实践提供了一个建立组织弹性的框架,该框架能够产生有效的响应,保护关键利益相关者的利益以及组织的声誉、品牌和价值创造活动。 | 服务连续性管理实践包括以下方面: ●执行BIA,量化服务的不可用对服务提供商和服务消费者的影响 ●制定服务连续性战略(如果相关,将其纳入业务连续性管理战略)。这应包括风险缓解措施的要素以及选择适当、全面的恢复方案 ●制定和管理服务连续性计划(如果相关,为业务连续性计划提供清晰的接口) ●进行演习并测试灾难情况下的服务连续性计划调用。 |
对比完目的和范围后就会发现,Monitoring and Event management关注的是监控范围,确定要维护的信息和产生信息的处理规则,阈值的确定和报告(目前监控管理面临的痛点是信息太多,应该如何提炼有价值的信息),Incident Management关注的是尽快恢复服务,而连续性管理关注的是如果识别风险,制定措施和计划,保证系统的连续服务,并定期演练连续性计划。
三个实践的接口和关联
在企业实践的运维过程中,很多事情都是连续的,但是我们很难用一个流程把所有的事情活动都确定下来。于是ITIL对于流程进行了适当的分割,对于流程的范围也做出了界定,虽然这一定程度上不太符合目前DevOps提倡的端到端,事实上这是目前企业IT运维的现状。
ITIL4有进步的一点是,每个practice都写明了和其他practice的接口,也强调了“ITIL实践只是价值流环境中使用的工具的集合;它们应该根据情况在必要时进行组合。” 这三个实践的接口部分是:
1. 需要定义从Event到Incident的关联场景。
2. 需要定义从Incident到Disaster的关联场景。
如果我们要做流程的切割,那么根据ITIL的最佳实践,建议:
1. Incident的早期发现、诊断、故障自愈:应属于Monitoring and Event Management。
2. 来自监控系统的Event,产生了业务中断,或者有潜在业务影响和风险,Event要按照Incident的处理流程,作为Incident来处理。
3. 制定服务连续性计划并将其与Incident Management管理活动分开管理时,应该有一个明确的触发服务连续性程序的标准。在评估故障的业务影响时,运维专家应确定重大故障是否可能导致灾难,并通知危机管理小组,以便他们能够做出决定。
最后总结
根据以上的解释,如果监控报告发生了异常,
1. 运维团队处理了,这算是Even还是Incident管理流程?
【答】:运维团队进行处理了,应该遵循Incident管理流程,去除异常,恢复服务。
2. 如果没有处理,异常越来越严重(当然处理的时候也有可能问题越来越严重),发生了危机,是属于Incident的管理流程还是需要建立一个新的流程(Crisis Management)?
【答】:如果还没有升级成为灾难,需要上报危机工作小组的话,还是按照Incident管理流程。如果需要,Incident 管理流程中,可以建立Major Incident子流程(重大故障管理流程),进行区别对待处理,包括激活24*7团队,事后要生产重大故障报告,管理问题管理流程分析原因等等。
写在最后,ITIL的最佳实践和流程可以组合应用,尤其是在企业大规模运维业务中,流程的边界分割可以依据企业情况灵活使用。
希望本文可以就Event, Incident和Crisis(Disaster)给大家一点启发。
附:服务连续性:https://blog.51cto.com/yazi0127/2551977
监控和Event: https://blog.51cto.com/yazi0127/2550306

- TWebBrowser流程讲解及如何判断下载网页成功
- TWebBrowser流程讲解及如何判断下载网页成功
- 如何记忆和理解ITIL中一项职能+五大流程
- TWebBrowser流程讲解及如何判断下载网页成功
- 如何记忆和理解ITIL中一项职能+五大流程
- 《中小型IT环境如何实施ITIL流程》(录音下载)
- 电力企业的管理流程如何界定?
- (转载)如何用PHP开发一个完整的网站 讲解开发流程 多人开发
- android事件传递流程 onTouchEvent onInterceptTouchEvent()
- 葫芦娃关于快速幂流程的详细讲解
- hitTest:withEvent:方法流程
- 如何把javaweb项目部署到阿里云linux Centos系统ECS云服务器(流程)
- 如何领购和作废电子发票流程
- 详细讲解如何在MFC单/多文档中创建多视图(具体代码)
- 详细讲解Maven插件MyBatis-Generator以及如何修改源码
- 2020年毕业设计流程讲解,日期划分等!!(个人总结,请与下半年学校下发文件对比参考)
- Uevent 上报event事件给上层的详细讲解
- 如何简单形象又有趣地讲解神经网络是什么?
- 如何评估一个好的ITIL解决方案?
- 超级详细讲解如何利用AJAX+Struts2异步检测用户名是否重复(附源码)