solr调用lucene底层实现倒排索引全流程解析
1.什么是Lucene?
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse的2.1版本中也采用了Lucene作为帮助子系统的全文索引引擎,相应的IBM的商业软件Web Sphere中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等。
2.什么是solr?
为什么要solr:
1、solr是将整个索引操作功能封装好了的搜索引擎系统(企业级搜索引擎产品)
2、solr可以部署到单独的服务器上(WEB服务),它可以提供服务,我们的业务系统就只要发送请求,接收响应即可,降低了业务系统的负载
3、solr部署在专门的服务器上,它的索引库就不会受业务系统服务器存储空间的限制
4、solr支持分布式集群,索引服务的容量和能力可以线性扩展
solr的工作机制:
1、solr就是在lucene工具包的基础之上进行了封装,而且是以web服务的形式对外提供索引功能
2、业务系统需要使用到索引的功能(建索引,查索引)时,只要发出http请求,并将返回数据进行解析即可
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
3.lucene和solr的关系
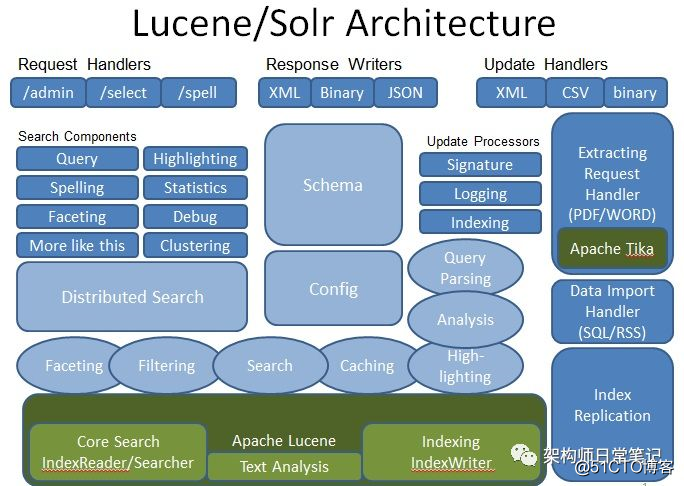
solr是门户,lucene是底层基础,solr和lucene的关系正如hadoop和hdfs的关系。那么solr是怎么调用到lucene的呢?
我们以查询为例,来看一下整个过程,导入过程可以参考:
solr源码分析之数据导入DataImporter追溯
4.solr是怎么调用到lucene?
4.1.准备工作
lucene-solr本地调试方法
使用内置jetty启动main方法。
4.2 进入Solr-admin:http://localhost:8983/solr/
创建一个new_core集合
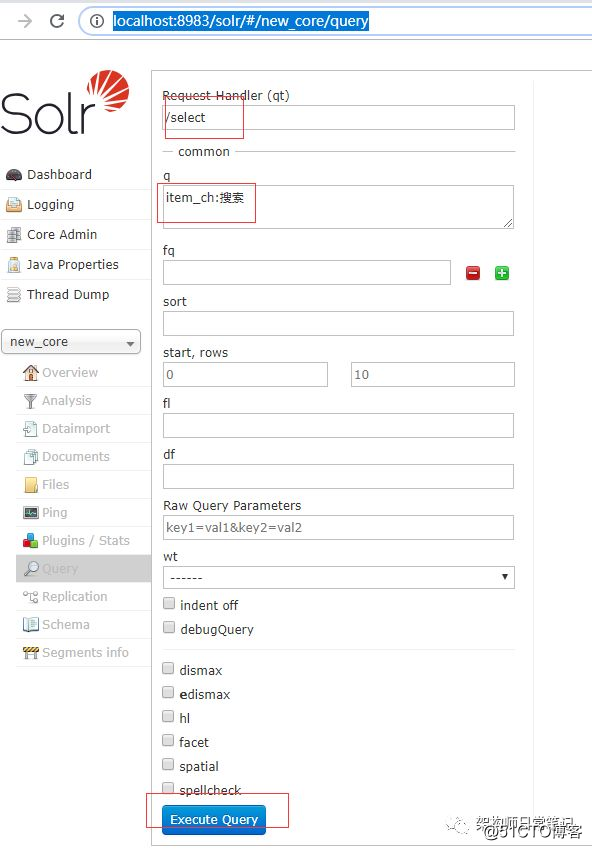
4.3 进入http://localhost:8983/solr/#/new_core/query
选择一个field进行查询
4.4 入口是SolrDispatchFilter,整个流程如流程图所示
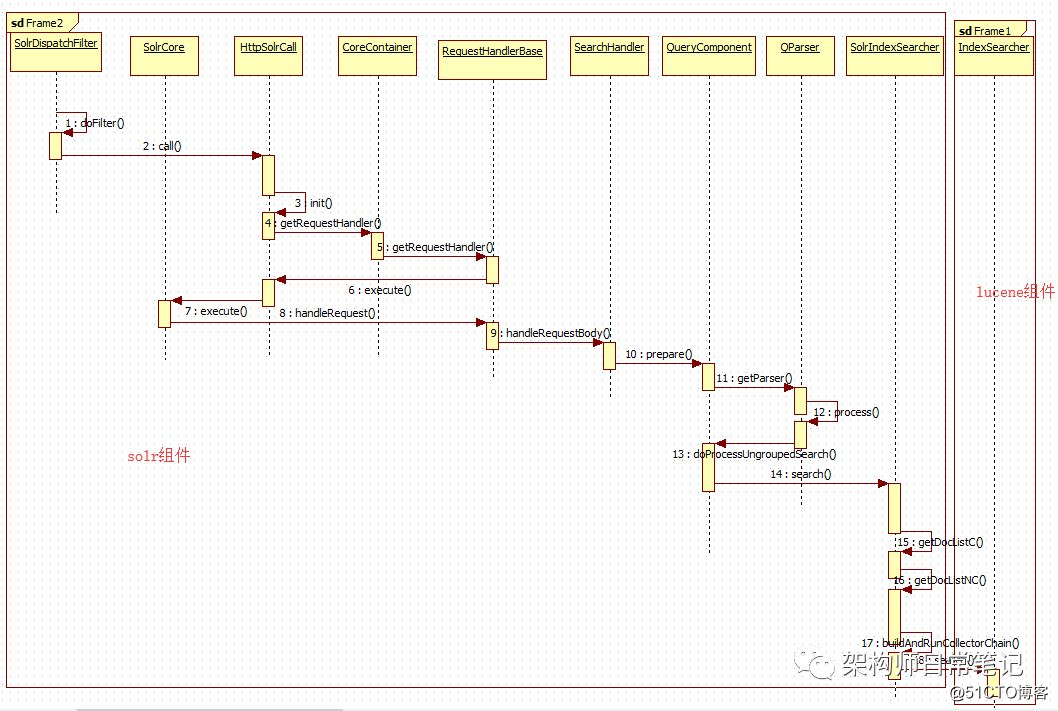
从上面的流程图可以看出,solr采用filter的模式(如struts2,springmvc使用servlet模式),然后以容器的方式来封装各种Handler,Handler负责处理各种请求,最终调用的是lucene的底层实现。
注意:solr没有使用lucene本身的QueryParser,而是自己重写了这个组件。
5.总结
从solr-lucene架构图所示,solr封装了handler来处理各种请求,底下是SearchComponent,分为pre,process,post三阶段处理,最后调用lucene的底层api。
lucene 底层通过Similarity来完成打分过程,详细 介绍了lucene的底层文件结构,和一步步如何实现打分。
参考资料:
【1】http://www.blogjava.net/hoojo/archive/2012/09/06/387140.html

- Lucene 4.X 倒排索引原理与实现: (3) Term Dictionary和Index文件 (FST详细解析)
- Lucene 4.X 倒排索引原理与实现: (3) Term Dictionary和Index文件 (FST详细解析)——直接看例子就明白了!!!
- Lucene 4.X 倒排索引原理与实现: (3) Term Dictionary和Index文件 (FST详细解析)
- Mybatis 代码流程及实现原理解析(三)
- MIT 2012 分布式课程基础源码解析-底层通讯实现
- solr 查询解析流程
- 深入解析Go中Slice底层实现
- lucene查询之 queryparser查询;及代码示例;代码实现;及查询语法解析
- new/delete和new[]/delete[]的底层调用和简单实现
- SQL解析顺序与MySQL底层实现
- 张正友相机标定Opencv实现以及标定流程&&标定结果评价&&图像矫正流程解析(附标定程序和棋盘图)
- JAVA序列化和反序列化的底层实现原理解析
- solr&lucene3.6.0源码解析(二)
- Arm Linux系统调用流程详细解析
- caffe源码深入学习6:超级详细的im2col绘图解析,分析caffe卷积操作的底层实现
- QT源码解析(五)QLibrary跨平台调用动态库的实现
- SpringMVC流程源码解析及SpringMVC相关知识点(Spring父子容器,SpringBoot对映射处理器功能拓展实现对静态资源的访问原理)
- GIS底层实现流程
- 张正友相机标定Opencv实现以及标定流程&&标定结果评价&&图像矫正流程解析(附标定程序和棋盘图)
- 上层APP调用底层硬件驱动过程解析