Logstash:数据的反扁平化 (unflatten)
2020-08-25 10:59
806 查看
反扁平化 (unflatten) 和 扁平化 (flatten)相反,它可以把一个零散的数据变成一个更加有意义的的一种表述,比如,针对以下的数据:
| image_title | image_url | image_size |
| picture1 | http://www.my.com/1.jpg | 32000 |
| picture2 | http://www.my.com/2.jpg | 48000 |
在上面,它显示的是一个典型的结构化表格。通常这个可能是来自另外一个数据库的数据。如果这样的数据导入到 Elasticsearch 中,就会出现很多的字段,比如:
[code]"image_title": "picture1", "image_url" : "http://www.my.com/1.jpg", "image_size": "32000"
显然这是一种非常扁平的存储方式,对于我们分析数据并不很好。如果你去参考 Elastic 的 ECS,你会发现更多的时候,如下的这种表述方式更加友好,也便于我们分析:
[code]{
"image": {
"title": "picture1",
"url": "http://www.my.com/1.jpg",
"size": 3200
}
}
在上面,我们使用了一个叫做 image 的 object,它里面含有三个字段。这种表述更加易于我们分析数据。从上面的那个结构变为下面的这个结构就叫做反扁平。在下面我们来讲述如何在 Logstash 中来实现。
我们首先来创建一个叫做 logstash_unflatten.conf 为配置文件:
logstash_unflatten.conf
[code]input {
generator {
lines => [
'{ "image_title": "picture1", "image_url" : "http://www.my.com/1.jpg", "image_size": "32000" }'
]
count => 1
codec => "json"
}
}
filter {
mutate {
rename => {
"image_title" => "[image][title]"
"image_url" => "[image][url]"
"image_size" => "[image][size]"
}
}
}
output {
stdout {
codec => "rubydebug"
}
}
在上面的 input 部分,我们使用了一个 generator 生成一个单次的事件。在 filter 的部分,我们使用 rename 来吧这个世界组织到 image 的这个 object 里去。运行 Logstash:
[code]./bin/logstash -f logstash_unflatten.conf
我们可以看到如下的结果:
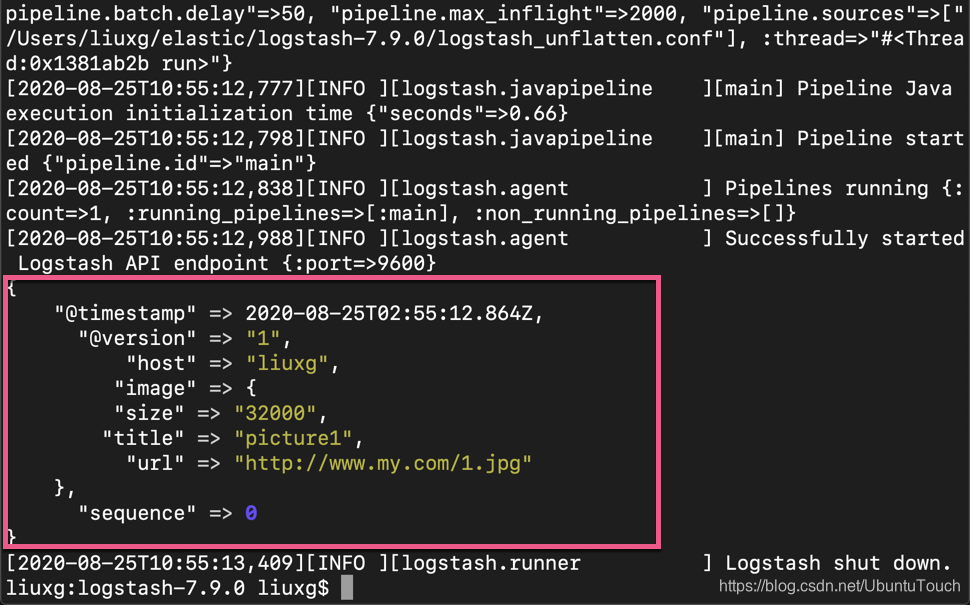
从上面,我们可以看出来,之前的那些 image_title, image_url 及 image_size 都变成 image 这个 object 里的字段值了。

相关文章推荐
- 大数据实时日志收集工具logstash 安装
- ElasticSearch5+logstash的logstash-input-jdbc实现mysql数据同步
- Logstash同步ORACLE数据至ES
- logstash使用webhdfs插件指定输出字段存储数据到hdfs时间分层(还能保留原来数据)
- logstash 导入数据,查看每秒导入的数据量及已导入数量和已导入时间
- lasticsearch 入门:Filebeat 安装及输出数据到 elasticsearch 或 logstash
- Elasticsearch系列(九)----使用Logstash-input-jdbc同步数据库中的数据到ES
- EasyUI comboxtree 数据扁平化封装
- ElasticSearch5+logstash的logstash-input-jdbc实现mysql数据同步
- 大数据技术-数据采集-Flume.logstash等
- logstash如何将kakfa合并的数据拆分然后写入ES
- logstash无法读取redis数据
- Logstash使用jdbc_input同步Mysql数据时遇到的空时间SQLException问题
- logstash 中input插件读取的数据没有日期,现在想在filter插件的csv插件中插入以时间字段
- Logstash:运用 memcache 过滤器进行大规模的数据丰富
- 使用 log4js UDP 发送数据到 logstash
- Logstash过滤器修改数据
- logstash发送数据给ElasticSearch,自定义索引(填坑)
- 利用logstash-output-jdbc从mysql导入数据到es中,如何构建多级节点的JSON
- 使用logstash将kafka数据入到elasticsearch