终极指南!创建Pandas Series的2种简单方法
熊猫系列是数据结构中最重要的部分。熊猫系列可以定义为Excel工作表中的一列。我们可以使用SQL数据库,CSV文件和已存储的数据来创建系列。在Pandas中创建系列的方法有很多,但是,我们将以这两种方式进行练习:
——使用ndarray或numpy数组
——使用Python字典
在本熊猫系列教程结束时,我确定您可以在系列上创建并执行任何任务。配套课程请点击这里:

#1.什么是Pandas Series?
Pandas Series可以认为是数据结构的基础。它基本上只不过是一维类似数组的结构,可用于处理和操作数据。令它与众不同的是它的索引属性,该属性具有令人难以置信的功能并且易变。配套课程请点击这里:
熊猫系列的参数: data:这是您希望系列拥有的值。 index:这是与您用于系列的值相关的索引。 dtype:这指定系列中值的类型。 copy:复制输入的数据。
首先,我们导入pandas库。
>>> import pandas as pd
#2.如何创建熊猫系列? 导入库后,在第二个代码框中,继续输入以下代码-
>>> dataflair_arr= pd.Series([2,3,-4,6])
这将创建您的系列。
要访问该系列,请对以下代码进行编码-
>>> dataflair_arr
输出- 0 2 1 3 2 -4 3 6 d类型:int64
恭喜你! 您已经在熊猫中创建了自己的第一个系列。

2.1使用ndarray或numpy数组创建系列 我们还可以使用ndarray或numpy array创建一个序列: 首先,我们将导入numpy库:
>>> import numpy as np
这使我们将库称为np。初始化之后,我们创建一个numpy数组,然后将其变成一系列。
>>> npa = np.array(['d','a','t','a']) >>> dataflair_ar= pd.Series(npa) >>> dataflair_ar
第一行创建numpy数组,第二行将其转换为pandas系列。
输出-
0 d
1 a
2 t
3 a
dtype:对象

2.2从python字典创建系列 我们可以从python 字典创建系列。 为此,我们首先需要创建一个字典:
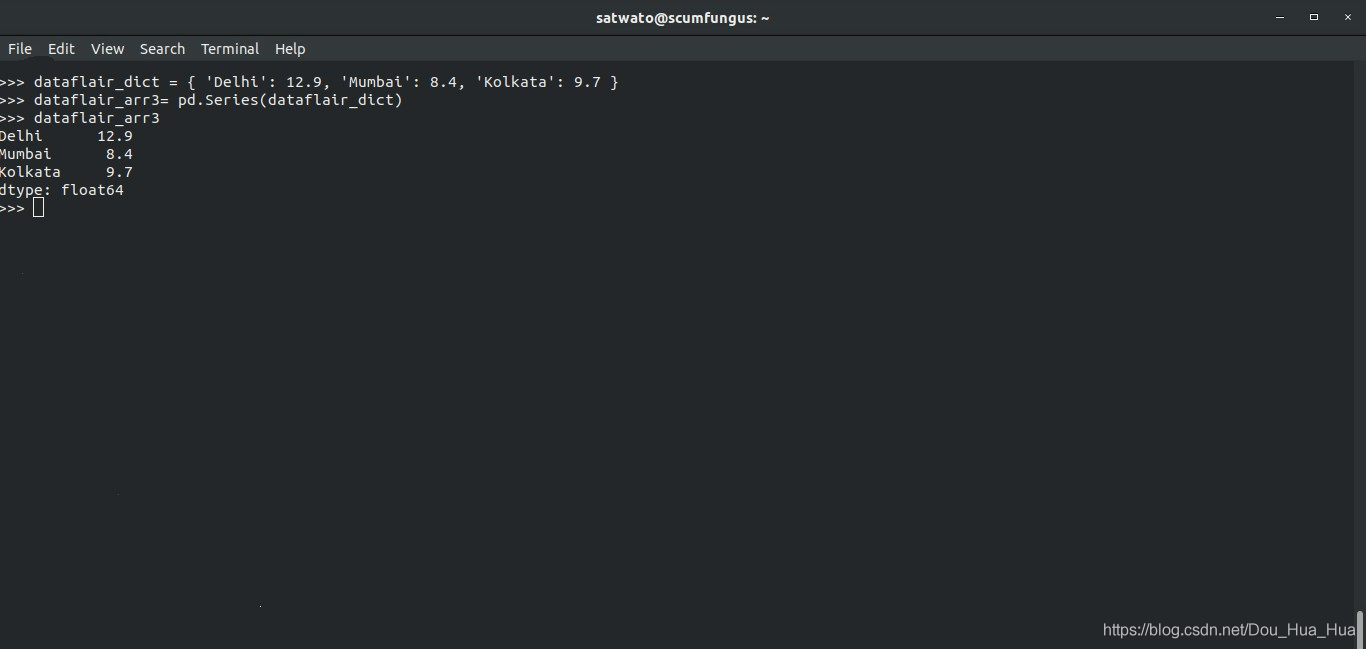
>>> dataflair_dict = { 'Delhi': 12.9, 'Mumbai': 8.4, 'Kolkata': 9.7 }要将这本词典变成熊猫系列,我们要做的就是:
>>> dataflair_arr3= pd.Series(dataflair_dict) >>> dataflair_arr3
输出-
Delhi 12.9
Mumbai 8.4
Kolkata 9.7
dtype: float64
dtype:float64
#3.如何更改熊猫系列的索引? 为了首先在熊猫系列中建立索引,我们将创建一个列表。配套课程请点击这里:
>>> num=[‘n1’,’n2’,’n3’,’n4’]
这是我们的列表,我们希望它成为值的索引(我们已提供)。因此,我们编写以下代码并运行它:
>>> dataflair_arr2= pd.Series([4,5,-2,2], index=num >>> dataflair_arr2
输出-

#4.如何对系列进行数学运算? 如果要将值检查为相应的索引,只需使用以下命令
>>> dataflair_arr2 [ 'n2' ]
这将返回值5。 我们可以使用参数来过滤一系列值。为此,我们来看下面的示例:
>>> dataflair_arr2 [ dataflair_arr2> 2 ]
这是什么意思?这基本上是告诉该系列您想要一个大于2的所有值的列表。配套课程请点击这里: 运行上面给出的代码,我们得到: n1 4 n2 5 dtype:int64
因为4和5是pandas系列中唯一的值,所以大于2。如果系列中是否存在某个索引,请使用python本机代码中的'in'参数。
>>> ‘n3’ in dataflair_arr2
这将返回“ True”。
>>> dataflair_arr2*5
输出-
n1 20
n2 25
n3 -10
n4 10
d类型:int64

#5.证明缺失值 让我们创建一个城市列表,并将其实现为一系列作为索引:
>>> cities=['Delhi', 'Kolkata', 'Mumbai', 'Chennai'] >>> dataflair_arr4=pd.Series(dict,index=cities) >>> dataflair_arr4
你有注意到吗?钦奈(Chennai)是新添加的,在原始系列中没有任何价值。在此,金奈的值表示为NaN。
Delhi 12.9
Kolkata 9.7
Mumbai 8.4
Chennai NaN
dtype: float64
NaN是熊猫表示缺失值的方式。

#6.如何在熊猫中添加两个系列? 是的,可以在熊猫中添加两个系列。
>>> dataflair_arr4 + dataflair_arr3
输出-
Chennai NaN
Delhi 25.8
Kolkata 19.4
Mumbai 16.8
dtype: float64

#7.如何访问熊猫系列中的一系列元素? 假设我们要访问arr4的前2个元素。我们所要做的就是在pandas中使用range函数,我们可以借助':'来使用它。 访问前两个元素的代码为:
>>> dataflair_arr4 [ :2 ]
输出- Delhi 12.9 Kolkata 9.7 dtype: float64
最后两个的代码是:
>>> dataflair_arr4 [ 2 :]
输出- Mumbai 8.4 Chennai NaN dtype: float64
因此,该函数基本上以series [x:y]的方式工作,其中x是范围的第一行的数字,y是范围的最后一行的数字。我们试试吧 :
>>> dataflair_arr4 [ 1 :3 ]
输出-
Kolkata 9.7
Mumbai 8.4
dtype: float64

摘要 现在,您可以在熊猫系列上创建并执行任何任务。学习系列概念成为大熊猫的主人是非常重要的。借助熊猫系列,您可以在其他两个数据结构中获得专业知识;数据框和面板。配套课程请点击这里:
更多文章和资料|点击下方文字直达 ↓↓↓ 阿里云K8s实战手册 [阿里云CDN排坑指南]CDN ECS运维指南 DevOps实践手册 Hadoop大数据实战手册 Knative云原生应用开发指南 OSS 运维实战手册

- HTTP/HTTPS底层原理揭秘
- Git使用http协议push时避免输入账号密码的方法
- 图解高内聚与低耦合,傻瓜都能看懂!
- Python网络爬虫开发实战使用XPath,xpath的多种用法
- 完美解决MySQL数据库建表报错((ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that )
- unity 原型_使用Unity和React快速进行原型制作
- 2020-08-12
- 对甘特图活动进行分组教程
- ios提醒事项同步日历scriptable代码
- pr软件日常有用吗_JS开发人员获得PR批准的20个超级有用技巧
- Docker轻量级虚拟机
- element表格数据发生变化 表格错位解决方案
- Opencv4.4安装
- Mybatis 和 Solon 勾搭在一起,也是个漂亮组合
- 学web前端自学好还是培训好?
- plc几种常用的编程语言特点
- 剑指offer刷题
- 百度飞桨 | 深度学习入门① 机器学习和深度学习综述(转载;个人删改版)
- VGG16等keras预训练权重文件的本地存放位置
- UNITY自用笔记-虚拟摇杆