百度飞桨PaddlePaddle论文复现——Few shot video-to-video Synthesis论文解读
百度飞桨PaddlePaddle论文复现——Few shot video-to-video Synthesis论文解读
飞桨课程复现顶会论文:link
引言
这篇文章是基于之前的vid2vid优化得到,作者认为之前的工作的没有泛化效果,本片文章的亮点就是这两年正热的注意力机制,作者使用注意力机制的新型网络权值生成模块实现和增强小样本的泛化能力。
源码,原文章
论文方法
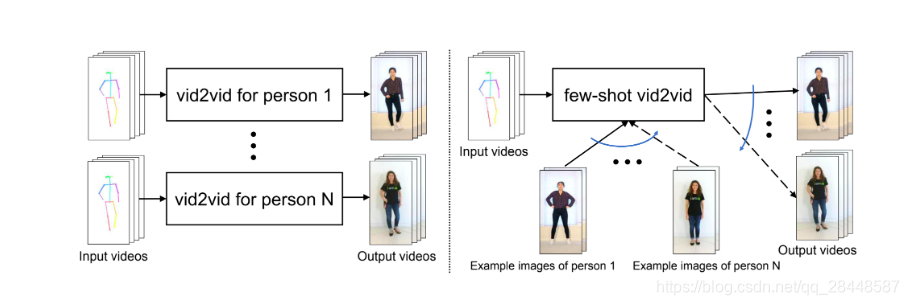
1,few-shot vid2vid 框架需要两个输入来生成视频,如图1所示。除了像vid2vid中那样的输入语义视频外,它还需要第二个输入,该输入由一些在测试时可用的目标域样本图像组成。注意,这在现有的vid2vid方法中中是不存在的。我们的模型使用这些少量的示例图像,通过一种新的网络权值生成机制来动态配置视频合成机制。具体来说,我们训练一个模型来使用样本图像生成网络权值并精心设计了学习目标函数,方便学习网络权值生成模块。
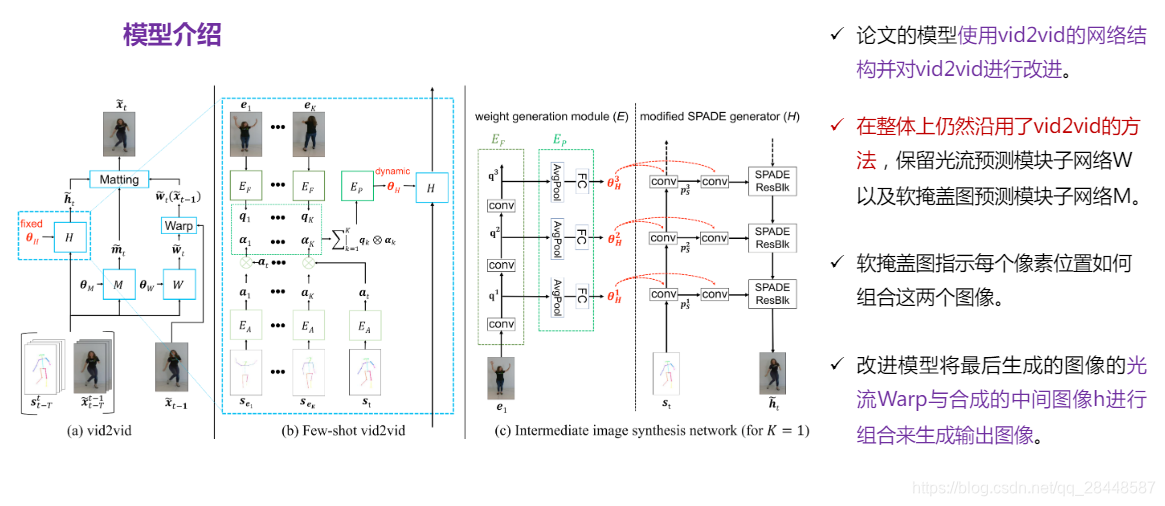
2,该图显示了,模型是将最后生成的图像的光流wrap版本与合成的中间图像进行组合来生成输出图像。 软遮挡图m指示在每个像素位置如何组合这两个图像。 直观地,如果先前生成的帧中观察到像素,则将有利于从变形图像中复制像素值。
Few-shot vid2vid 在整体上仍然沿用了目前的方法,保留光流预测模块子网络 W 以及软掩盖图预测模块子网络 M(W和M被设计用于使最后生成的图像变形,并且变形(image warping)本身就是在域之间自然共享的机制)。
考虑到我们的额外少量目标图片输入,few-shot vid2vid 集中优化了中间图像合成的模块 H(Fig b, c),用一个语义图像合成模型 SPADE 作为图片生成器取代了原先工作中的生成模型,SPADE 模型包含多个空间微调分支(spatial modulation branch)以及一个主要的图像合成分支。
这样做,首先,大大减少了网络 E(后面展开叙述) 必须生成的参数数量,从而避免 了过拟合问题。其次,它避免了从示例图像到输出图像的快捷通道,因为所生成的权重仅在空间调制模块中使用,空间调制模块会为主图像合成分支生成调制值。
这种建模允许 F 利用测试时提供的示例图像来提取一些有用的模式,以合成未见过的域的视频。这里,提出一个额外的网络参数生成模块 E(network weight generation module),使用该模块 E 作用于每个空间微调分支,来抽取一些视频内存在的有用模式,从而使得生成器能够合成未训练过的场景的视频结果。具体来说,E 的设计是为了从提供的示例图像中提取模式,并使用它们来计算中间图像合成网络 H 的网络权重。
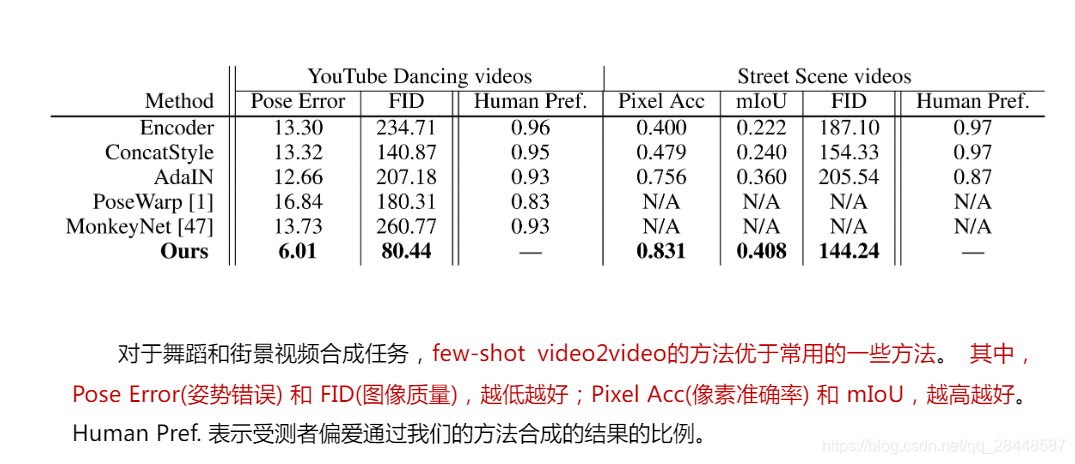
3,使用几个大规模的视频数据集,包括跳舞视频,头部讲话视频和街道场景视频与各种基准方法的比较进行了广泛的实验验证。实验结果表明,该方法有效地解决了现有vid2vid框架的局限性。此外,我们的模型的性能与训练数据集中视频的多样性以及测试时可用的样本图像的数量呈正比。当模型在训练时遇到更多不同的域时,它可以更好地泛化来处理未知的域。当在测试时给模型更多的样本图像时,合成视频的质量会提高。

- 【飞桨】【paddlepaddle】【论文复现】论文解读-BigGAN
- 百度飞桨PaddlePaddle论文复现营心得:First Order Motion Model for Image Animation
- 飞桨paddlepaddle论文复现——BigGAN论文翻译解读
- Few-Shot Unsupervised Image-to-Image Translation——ICCV2019论文解读
- 【PaddlePaddle飞桨复现论文】U-GAT-IT论文阅读
- 飞桨-论文复现 (PaddlePaddle)
- 飞桨PaddlePaddle论文复现营论文学习心得
- 【飞桨PaddlePaddle】StarGANv2论文复现
- 【paddlepaddle】【百度论文复现训练营】BigGAN论文阅读心得体会
- 飞桨 paddlepaddle论文复现
- 读U-GAT-IT论文「飞桨」「PaddlePaddle」「论文复现」
- 论文解读:StarGAN v2: Diverse Image Synthesis for Multiple Domains【PaddlePaddle】【论文复现】
- 【飞桨】【论文复现】百度顶会论文复现营之论文精读:U-GAT-IT论文笔记
- 【飞桨】【PaddlePaddle】【论文复现】StarGAN v2论文及其前置:GAN、CGAN、pix2pix、CycleGAN、pix2pixHD、StarGAN学习心得
- BiCycleGAN——Toward Multimodal Image-to-Image Translation,NIPS2017论文解读
- Learning to Compare: Relation Network for Few-Shot Learning. (学习比较:用于few-shot learning 的关系网络)
- CVPR 2018 Convolutional Sequence to Sequence Model for Human Dynamics 论文解读
- 百度飞桨PaddlePaddle《Python小白逆袭大神》结营心得
- Multimodal Unsupervised Image-to-Image Translation论文翻译以及解读
- 百度PaddlePaddle飞桨 随手笔记心得