Life-Long Learning(LLL)终身学习的理解
Life-Long Learning(LLL)
看了李宏毅老师的Life-Long Learning视频,以及粗略阅读了A continual learning survey:Defying forgetting in classification tasks这篇综述文章,菜菜的小孙对LLL有了初步的认知。(每次换方向都会秃头,记录一下今日2020年8月3日小孙又去剪了头发,心好痛)
目录
- Life-Long Learning(LLL)
- 一、什么是lifelong learning?
- 二、longlife learning过程
- 三、longlife learning方法
- 四、Multi-task learning,Transfer Learning,LifeLong learning之间的区别
- 五、lifelong learning评价指标
一、什么是lifelong learning?
细数机器学习处理的问题,概括得讲,可以分为如下几大类:
- 计算机视觉(CV): object classification, object detection, object segmentation, style transfer, denoising, image generation, image caption
- 语音(Speech) : speech recogniton, speech synthesis
- 自然语言处理(NLP): Machine translation, text classfication, emotional recogniton
- 推荐系统: Recommendation, CRT
目前针对各个大类的不同子类问题, 都会去设计不同的网络结构,采用不同的数据集去处理,使得这个网络只能处理给定的任务,换一个任务就无能为力了。我们需要设计一个网络,在 不同的任务上分别训练,使得该网络能够胜任所有的任务,这种能力叫持续学习 (continual learning/ life-long learning) 。终身学习相当于一种能够从连续的信息流中学习的自适应算法,随着时间的推移,这些信息逐渐可用。关键的是,新信息的容纳应该在没有灾难性遗忘或干扰的情况下发生。
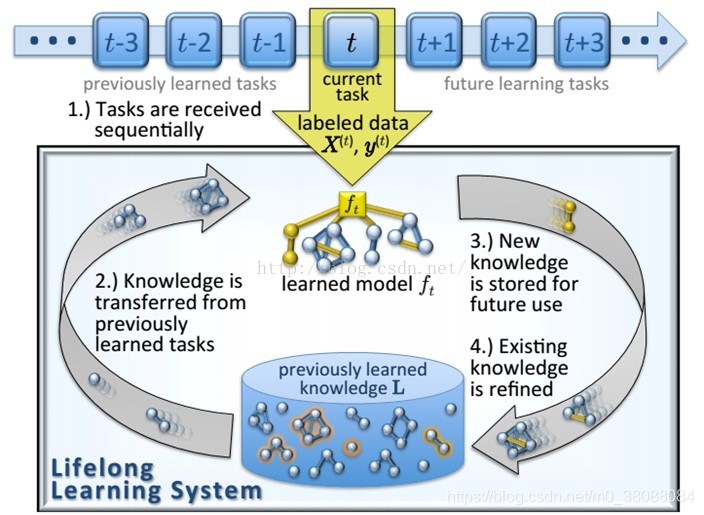
二、longlife learning过程
对于终身学习来说,我们需要解决的主要有三个方面的问题:
- 1.知识保留(Knowledge Retention):如果只使用一个模型来不断的学习不同的任务,自然希望它在学习新的任务的时候,也不要忘记已经学习到的东西。与multi-task learning不太一样(详细见第四部分)——稳定性
- 2.知识迁移(Knowledge Transfer):我们希望我们的模型可以使用已经学习到的东西来帮助解决新的问题,达到触类旁通的效果。与transfer learning又不太一样(详细见第四部分)——可塑性
- 3.模型扩展(Model Expansion):如果模型比较简单,也许处理简单问题时还可以,但是在处理复杂问题时结果不太满意。故我们希望模型可以自己根据问题的复杂度进行扩展,变为更加复杂的模型。一般扩展模型是党目前任务的准确度不够好或者loss降不下去的时候会扩展模型,如Net2Net。
知识迁移流程:
- 1.任务按顺序接收
- 2.从先前学习的任务中迁移知识
- 3.存储新知识以备将使用
- 4.改善现有知识
三、longlife learning方法
Regularization:在网络参数更新的时候增加限制,使得网络在学习新任务的时候不影响之前的知识。这类方法中,最典型的算法就是EWC。
Ensembling: 当模型学习新任务的时候,增加新的模型(可以是显式或者隐式的方式),使得多个任务实质还是对应多个模型,最后把多个模型的预测进行整合。增加子模型的方式固然好,但是每多一个新任务就多一个子模型,对学习效率和存储都是一个很大的挑战。google发布的PathNet是一个典型的ensembling算法。
Rehearsal:这个方法的idea非常的直观,我们担心模型在学习新任务的时候忘了旧任务,那么可以直接通过不断复习回顾的方式来解决呀(ง •_•)ง。在模型学习新任务的同时混合原来任务的数据,让模型能够学习新任务的同时兼顾的考虑旧任务。不过,这样做有一个不太好的地方就是我们需要一直保存所有旧任务的数据,并且同一个数据会出现多次重复学习的情况。其中,GeppNet是一个基于rehearsal的经典算法。
Dual-memory:这个方法结合了人类记忆的机制,设计了两个网络,一个是fast-memory(短时记忆),另一个slow-memory(长时记忆),新学习的知识存储在fast memory中,fast-memory不断的将记忆整合transfer到slow-memory中。其中GeppNet+STM是rehearsal和dual-memory相结合的一个算法。
Sparse-coding: 灾难性遗忘是因为模型在学习新任务(参数更新)时,把对旧任务影响重大的参数修改了。如果我们在模型训练的时候,人为的让模型参数变得稀疏(把知识存在少数的神经元上),就可以减少新知识记录对旧知识产生干扰的可能性。Sensitivity-Driven是这类方法的一个经典算法。
四、Multi-task learning,Transfer Learning,LifeLong learning之间的区别
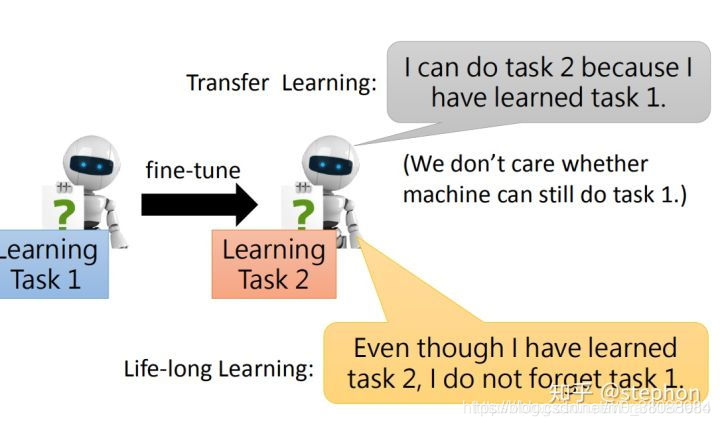
Transfer Learning VS LifeLong Learning:
Transfer learning只考虑在当前任务上的效果
而LifeLong Learning需要考虑在所有任务上的效果
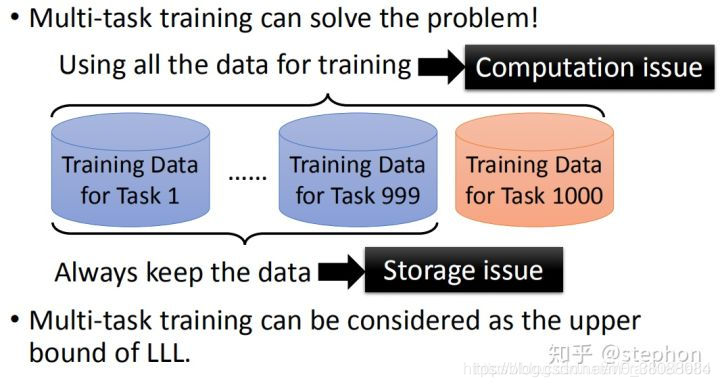
Multi-task Learning VS LifeLong Learning :
LifeLong Learning训练时只用当前任务的数据
Multi-task Learning会用到之前所有任务的数据
这带来了数据存储以及计算量不断增大的问题; Multi-task learning可以看作是LifeLong learning的upper bound
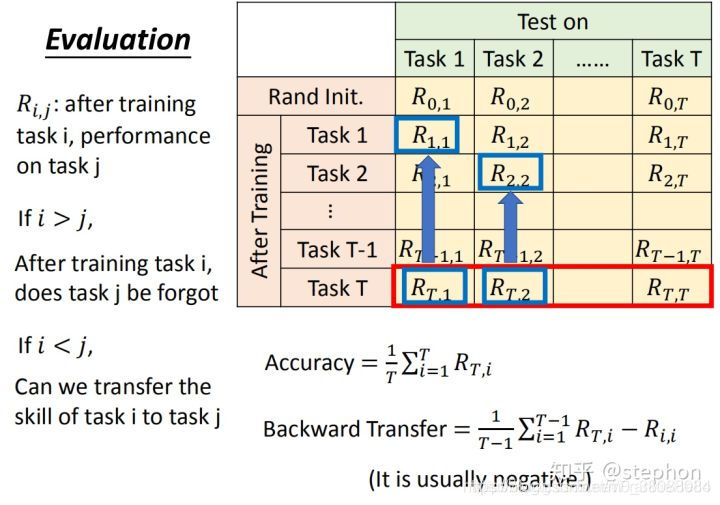
五、lifelong learning评价指标


- Spring学习01--初学者关于AOP和DI的理解
- 机器学习实战+统计学习方法之理解KNN(1.实战代码的详细走读和解析)
- Unity3D协同程序的学习理解与说明
- YII学习,初体验 ,对YII的一些理解.
- Ant学习理解(稍后会转载到新浪博客)
- JavaScript学习--Item13 理解 prototype, getPrototypeOf 和__proto__
- 【终身学习才是通往自由的入口】为…
- Source Xref 与 JavaDocs 学习理解
- Maven学习总结(19)——深入理解Maven相关配置
- 关于linux系统的日志文件的学习与理解
- CUDA系列学习(六) 从并行排序方法理解并行化思维——冒泡、归并、双调排序的GPU实现
- 深入理解Java多线程学习笔记-守护线程
- 【学习笔记】深入理解js原型和闭包(11)——执行上下文栈
- tensorflow学习二:概念知识和一个帮助理解的demo
- 2017年11月23日学习笔记_用python解决杨辉三角函数,以及理解
- scala学习笔记:理解lazy值
- 深入学习理解 1 java ExecutorService invokeAll 任务的批量提交invokeAll两种方
- java学习总结(16.05.17)对数据类型取值范围和数据溢出的理解(以byte类型为例)
- 【学习笔记】深入理解js原型和闭包(17)——补this
- 学习【深入理解java虚拟机】一 :泛型和擦除