Python编程从入门到实践一(列表、字典、读写文件txt,json、if/while、函数、类和对象)
2020-07-29 10:36
246 查看
文章目录
chap2 变量和简单的数据类型
写在前面
变量类型:int、float、str、tuple都是不可变类型 list、dict、set是可变类型
- 转义字符使用
- python可以+=呀~
- 双引号 ’ “” ’
- lstrip 等strip \n \t都会去掉
- 整数除法// 浮点数除法/
- int和string型,两个不能相加
str(a)
调用等就是a.__str__()
,包括None与其他也不能相加
chap3 列表操作
小结
| 一些常用函数 | 列表的推导式(一行式) | 切片 |
|---|---|---|
| append | 结果是一个列表 | a=b[:] |
| extend | 结果是嵌套列表 | seq[::-1] |
| sort/reverse |
结果一个列表 从左到右从大到小拆列表
all_data=[['John', 'Emily', 'Michael', 'Mary', 'Steven'],
['Maria', 'Juan', 'Javier', 'Natalia', 'Pilar', 'Shenzaier']]
result = [name for names in all_data for name in names if name.count('e')>=2]
结果两个列表,从右往左,从大到小拆列表
some_tuples = [(1, 2, 3), (4, 5, 6), (7, 8, 9)] [[x for x in tup] for tup in some_tuples]
- 增(append insert),删(pop remove),排序sorted(reverse = True) & .sort(reverse = True),倒序.reverse() 后两个.调用都会改变原来的列表
b.sort(key=len) #还可以用key按字符串长度进行排序
- reversed元素倒序排列
list(reversed(range(10))) [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
- 切片右区间始终是开的
- 前十个整数的平方,并存在列表中打印,简化定义版本;如果需要取元素,老老实实写for循环 for item in list:
a = [i for i in range(2,11,2)] names = ['judy','nick','natasha'] divided_name = [i for name in names for i in name ] print(divided_name) #ans: ['j', 'u', 'd', 'y', 'n', 'i', 'c', 'k', 'n', 'a', 't', 'a', 's', 'h', 'a']
- 复制列表2种方式及区别
复制列表,原列表值不变
直接a = b 则ab相关联,a变b也变,vice versa
b = a[:]
- 联合列表
extend是扩展 []+[]=[]
append是加元素[].append[]=[[]]
x.extend([7, 8, (2, 3)]) # 添加多个元素
- 切片
利用步长step对列表进行翻转
seq = [1, 2, 5, 6, 3, 7, 8] seq[::-1] [8, 7, 3, 6, 5, 2, 1] ------------------------------------- seq = [1, 2, 5, 6, 3, 7, 8] seq[::2] [1, 5, 3, 8]
chap4 字典
小结
| 一些常用函数 | |
|---|---|
| update两个字典合并 | |
| dict(zip())序列合成列表 | |
| dict.get(value,defalt_value)是否在字典中 | |
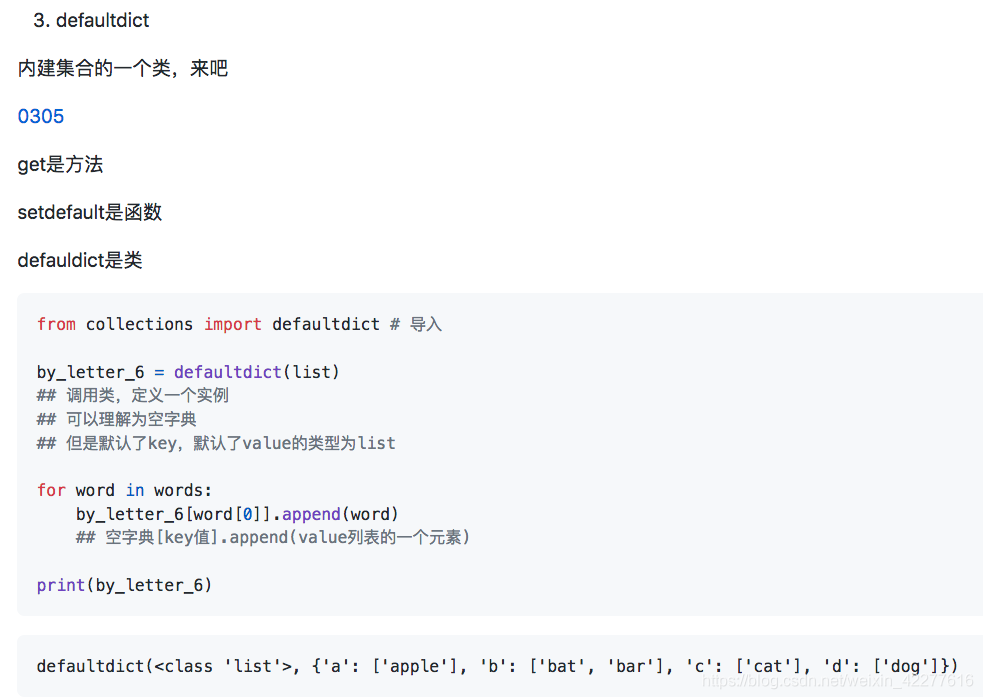
| dict.setdefault或者defaultdict类 |
- 删除
del dict_name[key]
或者index_value = dict_name.pop(index)
{0: 'a', 2: 'c'}
b = a.pop(0)
a {2: 'c'}
b 'a'
- 遍历 item(),keys(),values()
- update将两个字典合并,注意key值相同会被覆盖
a.update({3: 'd', 4: 'e', 0:'f'})
a
{0: 'f', 1: 'b', 2: 'c', 3: 'd', 4: 'e'}
- 序列合成字典
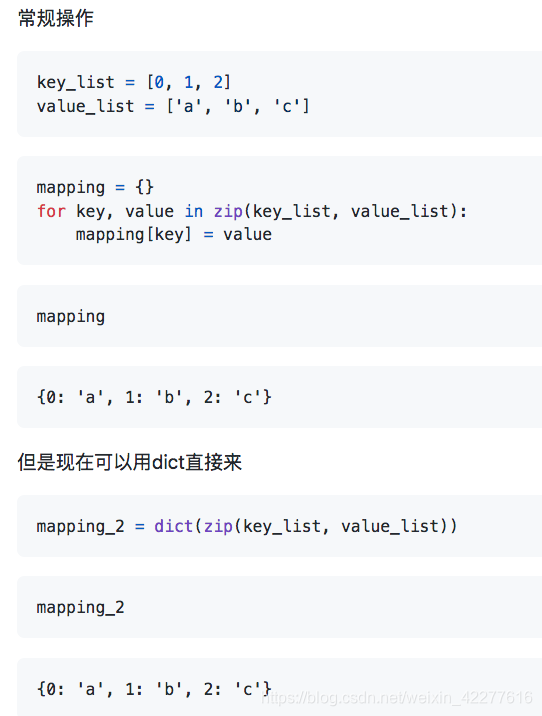 - 测试一个key在不在字典里,在就要这个值,不在就返回默认值,比如’不在’
- 测试一个key在不在字典里,在就要这个值,不在就返回默认值,比如’不在’
 - setdefault
- setdefault
如果键不存在于字典中
将会添加键,并设置默认类型(0(int),’ '(str),{}(dict),[](list),或者set()(set)),若在字典中,则跳过default_value继续后续操作
set() 表示空集合,set表示set类型
这里表示的是值
用set的话,变成了<class ‘set’> 即值为类型,该类型叫set
用set()就表示是一个值 set类型的空值


- 字典中的东西没有顺序,若想要,则需要sorted(set函数去重)
for fruit_name in sorted(fruit.keys()): print(fruit_name)
- 定义字典必须有键和值
错误的example:
fruit = {
'apple':1,
'banana':2,
}
vegetable={
'eggplant':1,
'tomato':2,
}
my_fav_wrong = {fruit,vegetable}
#TypeError: unhashable type: 'dict'
改成列表正确
my_fav_correct = [fruit,vegetable]
如果要字典套字典,只能定义为
my_fav_correct2 = {
'fruit':{
'apple':1,
'banana':2,
},
'vegetable':{
'eggplant':1,
'tomato':2.
}
}
chap5 读写文件
读写文件,先问问自己文件名,w还是读,用不用改encoding
- 读 txt全部内容 ,read
#注意encoding的格式,打开中文
#UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128)
#如何打开 with open() read()函数全部读取
with open("chap7.txt",encoding='utf-8') as file:
contents = file.read() #每一个字为一个列表中的元素
print(contents)
- 读 txt逐行内容,readlines(readline只有一行)
readlines()方法读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素,但读取大文件会比较占内存
#逐行读取,创建包含文件各行内容的列表readlines file_name = "chap7.txt" with open(file_name,encoding='utf-8') as file: lines = file.readlines() for line in lines: print(line) print(line.rstrip())#去掉空行
- 写 txt
file_write_name = '000.txt'
with open(file_write_name,'w',encoding='utf-8') as file:
file.write('一愿社稷昌\n')
file.write('二愿黎民宁\n')
file.write('三愿我所爱无忧无恙,岁岁长安\n')
- 分析文本
split 功能:当不给split函数传递任何参数时,分隔符sep会采用任意形式的空白字符:空格、tab、换行、回车等,但还是给一个参数吧
title = "何事?\n寻人。\n........\n你从此以后,可就和真龙同寿了。\n求之不得。\n"
a = title.split("\n")
print(a)
- json存列表呀字典呀一个字符串blabla
json 读取load 写入dump
import json number = [1,2,3,4,5,6,7,8,9] file_name = 'numbers.json' with open(file_name,'w') as file: #开始漏掉w,,读写文件,先问问自己文件名,w还是读,用不用改encoding json.dump(number,file) with open(file_name) as file: a = json.load(file) print(a)
chap6 逻辑条件if
- in 和 not in
- if else 怕错点话,在一维里,分析所有的情况,再写程序
- 帮助人们挣钱的,教育相关,个性化学生学习安排易错点,多维交流(时间空间)平台
chap7 input & while
- input : 返回的值是string型!
i = input("please enter your age:")
print("Hey,I'm "+ i +" years old")
- eval() 函数用来执行一个字符串表达式,并返回表达式的值。
eval("3**2")
#ans:
#9
- while: while循环 quit退出
- break & continue 和c++一样不写了
prompt = "Tell me sth,and I'll repeat it back to you: "\ +"\n Enter 'quit' to end the program" str = '' while str!='quit': str = input(prompt) if str !='quit': print(str)
练习一 while循环 *退出
注意之前定义了str
再调用str() , 会有not callable的错误!
price = 0
while True:
age = input("how old are you?")
if age=='*':
break
else:
age = int(age)
if age<0:
print("input again")
continue
elif age>=1 and age <=12:
price = 0
elif age>12:
price=12
print("your cost is "+str(price)+" $.")
练习二 移除元素
orders = ['a','b','c','a','a']
while 'a' in orders:
orders.remove('a')
chap8 函数
字典作为可变函数参数
- 函数内对字典进行修改,原来的字典也会进行改变。
extra = {'city': 'Beijing', 'job': 'Engineer'}
def person(kw):
kw['city']='qingdao'
person(extra)
print(extra)
结果:
{'city': 'qingdao', 'job': 'Engineer'}
- 函数内对字典修改,不会影响到原来的字典。可直接传一个字典或者调用函数时按A= B的格式输入任意多个键值对**
extra = {'city': 'Beijing', 'job': 'Engineer'}
def person(**kw):
kw['city']='qingdao'
person(**extra)
print(extra)
结果:
{'city': 'Beijing', 'job': 'Engineer'}
列表元组任意数量实参
def make_pizza(*toppings): #这里的参数是元组形式
total = ''
for index,i in enumerate(toppings):
print(i)
total += i
if index == len(toppings)-1:
total+='.'
else:
total+=','
print("make a pizza: "+total)
toppings = ['mushrooms','green peppers','extra cheese'] # 或者定义成元组
make_pizza(*toppings)
- 直接传入a,一起改变,
- 传入参数的值的时候就传切片,一维好用不改变
change_book_list = change(a[:]) - 利用*,
!!!三者区别!!!
模块找不到错误
将函数存在 a.py 文件下,在同一个路径里 b.py 调用
直接from b import * ,然后调用 函数() 报错找不到
‘’’
当我们导入一个模块时:import xxx,默认情况下python解析器会搜索当前目录、已安装的内置模块和第三方模块,搜索路径存放在sys模块的path中:
‘’’
import sys
sys.path.append("根目录")
chap9 类和对象
- 和java相似的 一个类封装了属性和方法,但是不同的是self顶替了一开始定义的一些属性
- 只需要创建实例就可以调用属性使用方法了
- 继承:写在类的括号里 + 构造器里调用父类的初始化函数
- 如果有一个父类的方法子类不适用,override即可
- C类也可以作为B类(是A类的子类)属性初始化的方式
-
类的导入 from 文件名 import 类名
-
如果有重名就先 import 文件名 然后文件名.类名创建实例
-
python 标准库 从collection中导入类
from collections import OrderedDict favorite_languages = OrderedDict() favorite_languages['jen'] = 'python' favorite_languages['judy'] = 'c' favorite_languages['nick'] = 'ruby' for key,value in favorite_languages.items(): print(key.title()+"'s favorite language is "+value)
格式规范
- 类名 首字母大写没有下划线 文档字符串注释
- 类中的函数之间空一行,如果再定义不同的类则空两行
- import 导入先导入标准库 空一行再自定义模块中的类
class Resaurant():
'''这里写注释:模拟饭店调查'''
def __init__(self,resaurant_name,cuisine_type):
self.resaurant_name = resaurant_name
self.cuisine_type = cuisine_type
self.number_served = 0
def describe_resaurant(self):
print(self.cuisine_type+' in '+self.resaurant_name+" is really good!")
def open_resaurant(self):
print("It's opening!")
def set_number_served(self,number):
if number>=self.number_served:
self.number_served = number
print('A total of '+str(self.number_served)+' people were served')
def increment_number_served(self,increment_number):
self.number_served += increment_number
print('A total of '+str(self.number_served)+' people were added')
# resaurant = Resaurant('Yang','Spicy Hot Pot')
# resaurant.set_number_served(100)
# resaurant.increment_number_served(50)
class IceCreamStand(Resaurant):
'''定义一个冰激凌摊'''
def __init__(self,resaurant_name,cuisine_type):
super().__init__(resaurant_name,cuisine_type)
self.flavors = ['vanilla','chocolate','durian']
def print_flavors(self):
print('The flavors are as followed:')
for flavor in self.flavors:
print('\t -'+flavor)
resaurant_2 = IceCreamStand('Mcdonald','ice_cream')
resaurant_2.print_flavors()
PyMOTW-3 怎么用python3标准库中的类和函数
- collections OrderedDict 有序字典可以按字典中元素的插入顺序来输出。
如果有序字典中的元素一开始就定义好了,后面没有插入元素这一动作,那么遍历有序字典,其输出结果为空,因为缺少了有序插入这一条件,所以此时有序字典就失去了作用,所以有序字典一般用于动态添加并需要按添加顺序输出的时候。
但是可以
d = OrderedDict([('a','A'),('b','B'),('c','C')])
chap10 测试代码测试类
测试代码
- python自定义unittest单元测试类,帮助完成测试工程
- 我们自己定一个class,继承unittest;断言测试函数;调用unittest.main()
import unittest #文件
from chap8 import get_formatted_name
# a = get_formatted_name("a","b")
# print(a)
class NamesTestCase(unittest.TestCase):
'''测试'''
def test_first_last_name(self):
name = get_formatted_name('judy','Smith')
self.assertEqual(name,'Judy Smith')
unittest.main()
# 各种断言的方法:譬如核实等于,不等于,在list,不在list,结果为True,结果为False等等
测试类
可以构造一个setUp函数,写好 被测试的类的实例和预测的结果
PEP 8规范 1.尽量不要使用小写l(1) o(0) 2.空行 缩进等的规范

相关文章推荐
- Python入门 列表 for while if...else... 函数
- 学生系统--(列表、带返回值的函数、if 、while)文件读写的应用
- Python入门 [输出,注释,列表,元祖,集合,字典,if,while,for]
- Revit中Dynamo编程——在Python Script中读写txt格式文件
- Python编程 从入门到实践 第六章 字典
- Python编程从入门到实践三(画图\读操作csv文件\zip & groupby)
- python 编程 入门到实践 第四章 列表操作和元祖 (课后题加原书)
- python编程:从入门到实践 第六章 字典
- python从入门到放弃篇9.1(字典,列表,计数器,while True,for嵌套,for与if嵌套)实现贩卖机程序升级版v2.0
- python 编程 入门到实践 6章 字典与嵌套
- Python读取txt文件,将xxx=111,yyy=222转换为json或字典格式
- python编程:从入门到实践 第十章 文件和异常
- Python编程从入门到实践 第4章 操作列表
- Python编程:从入门到实践 第5章 if语句
- Python编程:从入门到实践 第3章 列表简介
- Python3实现的字典、列表和json对象互转功能示例
- Python编程:从入门到实践 学习笔记 基础知识(二)列表
- Python编程从入门到实践笔记——函数
- Python编程从入门到实践笔记——操作列表
- 【原】使用Json作为Python和C#混合编程时对象转换的中间文件