机器学习3---数据的特征工程之特征处理
特征处理
概念
特征处理是指通过特定的统计方法(数学方法)将数据转换成算法要求的数据。
- 数值型数据:归一化、标准化、缺失值处理;
- 类别型数据:one-hot编码;
- 时间类型:时间的切分。
sklearn特征处理API
sklearn.preprocessing
归一化
- 概念:通过对原始数据进行变换把数据映射到(默认为[0, 1])指定范围。

- sklearn归一化API:sklearn.preprocessing.MinMaxScaler
语法:
(1)实例化:MinMaxScalar(feature_range = (0, 1),……)
即每个特征值缩放到指定范围(默认[0, 1])
(2)MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples, n_features]
返回值:与转换前相同的array - 归一化步骤:
(1)实例化MinMaxScalar
(2)通过fit_transform转换
from sklearn.preprocessing import MinMaxScaler def mm(): """ 归一化处理 :return: None """ # 实例化 mm = MinMaxScaler(feature_range=(2, 3)) # fit_transform data = mm.fit_transform([[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]) print(data) return None if __name__ == '__main__': mm()
运行结果:

- 归一化适用场景:
例:

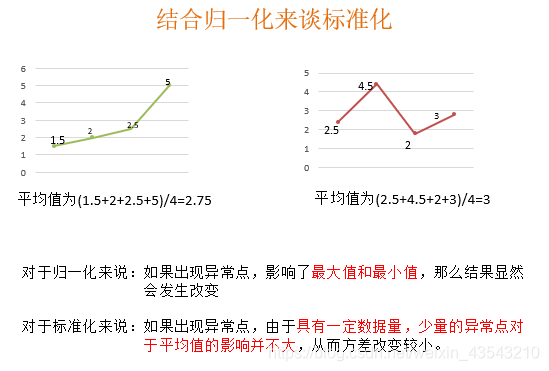
若不进行归一化,在进行后续的数据处理时,如k近邻算法,会发现里程数相比其他两个特征对最终结果的影响更大。因此,在认为几个特征同等重要时,有必要对数据进行归一化处理(归一化的目的即是使某一个特征对结果不会造成更大影响)。 - 归一化存在的问题
当数据中存在异常点(如下图所示)时,会影响数据的最大值和最小值,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
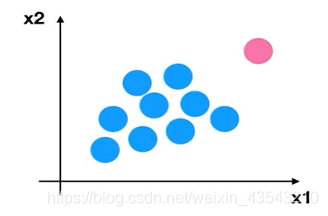
标准化
标准化能解决上面提出的异常点问题。
-
概念
标准化通过对原始数据进行变换,将数据变换到均值为0,方差为1的范围内:
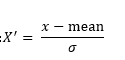

-
sklearn标准化API:
sklearn.preprocessing.StandardScaler
(1)StandardScaler.fit_transform(X)
X: numpy格式的数据[n_samples, n_features]
返回值:与转换前形状相同的array
(2)StandardScaler.mean
原始数据中每列特征的平均值
(3)StandardScaler.std
原始数据中每列特征的方差 -
标准化步骤
(1)实例化StandardScaler
(2)通过fit_transform转换 -
标准化适用场景
标准化在已有样本足够过的情况比较稳定,适合现代嘈杂大数据场景。
缺失值处理
- 缺失值处理方法
| 删除 | 若每列或者行数据缺失值达到一定比例,建议放弃整行或者整列 |
|---|---|
| 插补 | 可以通过缺失值每行或者每列的平均值、中位数来填充 |
-
缺失值处理API:
sklearn.preprocessing.Imputer
(1)实例化:
Imputer(missing_values = “NaN”, strategy = “mean”, axis = 0)
注:axis=0为列方向
(2)Imputer.fit_transform(X)
X: numpy array格式的数据[n_samples, n_features]
返回值:与转换前形状相同的array -
Imputer流程:
(1)初始化Imputer,指定“缺失值”,指定填补策略,指定行或列(缺失值也可以是别的指定要替换的值)
(2)调用fit_transform() -
关于np.nan(np.NaN)
(1)numpy的数组中可以使用np.nan或者np.NaN来代替缺失值,属于float类型;
(2)如果是文件中的一些缺失值,可以替换成nan,通过np.array转换成float类型的数据即可。如:replace(“?”,np.nan)
from sklearn.preprocessing import Imputer import numpy as np def im(): """ 缺失值处理 :return: """ im = Imputer(missing_values="NaN", strategy="mean", axis=0) data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6]]) print(data) return None if __name__ == '__main__': im()
运行结果:


- 不会做特征工程的 AI 研究员不是好数据科学家!上篇 - 连续数据的处理方法 本文作者:s5248 编辑:杨晓凡 2018-01-19 11:32 导语:即便现代机器学习模型已经很先进了,也别
- 【特征工程】2 机器学习中的数据清洗与特征处理综述
- 机器学习——特征工程之数据预处理
- 机器学习—数据的特征工程
- 【方法】机器学习中的数据清洗与特征处理
- 结合美团下单率预测详解机器学习中的数据清洗与特征处理
- 机器学习处理流程、特征工程,模型设计实例
- Python机器学习笔记 使用sklearn做特征工程和数据挖掘
- 机器学习建模的数据特征工程—— 《Python深度学习》读书笔记(3)
- 【机器学习 第三周】简单的数据预处理和特征工程
- 机器学习中的数据清洗与特征工程
- 特征工程(补充)--机器学习数据集里的不均衡数据问题
- 机器学习(八)使用sklearn库进行数据分析_——特征处理之过滤、包裹、嵌入型
- 机器学习中的数据清洗与特征处理综述
- 机器学习之数值特征处理及数据探索
- 机器学习中的数据清洗与特征处理综述
- 机器学习:数据特征预处理(缺失值处理)
- 机器学习——数据表示和特征工程
- 机器学习(九)使用sklearn库进行数据分析_——文本特征处理
- 机器学习中的数据清洗与特征处理综述