算法——数据结构基础(数组、队列、栈、链表、散链表)
算法——数据结构基础
文章结构概览
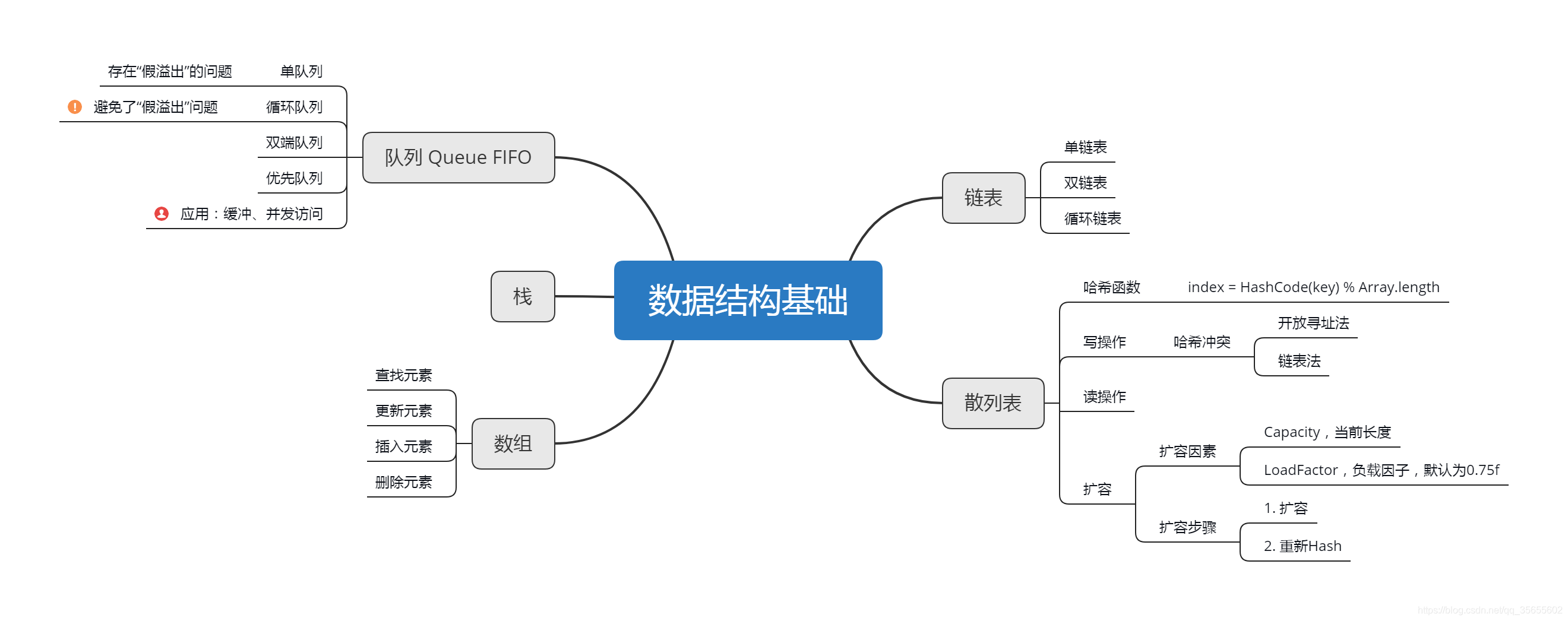
数组:顺序存储
读操作多,写操作少
- 1.读取(查找)元素:读取对应的下标
高效的查找元素的算法:二分查找 - 2.更新元素:对元素进行重新赋值
- 3.插入元素:尾部插入、中间插入、超范围插入
扩容问题,时间复杂度:O(n)
插入并移动元素,时间复杂度:O(n) - 4.删除元素:1) 删除对应位置,后面的元素往前挪
2) 把最后一个元素复制到删除元素所在的位置,再删除最后一个元素
删除元素,时间复杂度:O(n)
package array; /**
* Copyright (C), 2019-2020
* author candy_chen
* date 2020/6/16 9:58
* version 1.0
* Description: 数组
*/
/**
*测试数组从中间插入元素
*/
public class test_array {
private int[] array;
private int size;
public test_array(int capacity) {
this.array = new int[capacity];
size = 0;
}
/**
*
* @param element 插入的元素
* @param index 插入的位置
* @throws Exception
*/
public void insert (int element,int index) throws Exception{
//判断访问下标是否超出范围
if (index <0 || index >size){
throw new IndexOutOfBoundsException("超出数组实际范围");
}
//从右向左循环,将元素逐个向右挪1位
for (int i=size -1;i>=index;i--){
array[i+1] = array[i];
}
//腾出的位置放入新元素
array[index] = element;
size++;
}
/**
* 数组扩容
*/
public void resize(){
int[] arrayNew = new int[array.length*2];
//从旧数组复制到新数组
System.arraycopy(array,0,arrayNew,0,array.length);
array = arrayNew;
}
/**
* 数组删除元素
* @param index 删除的位置
* @return
*/
public int delete(int index){
if (index <0 || index >size){
throw new IndexOutOfBoundsException("超出数组实际范围");
}
int deletedElement = array[index];
//从左向右循环
for (int i=index;i<size-1;i++){
array[i] = array[i+1];
}
size--;
return deletedElement;
}
/**
* 输出数组
*/
public void output(){
for (int i=0;i<size;i++){
System.out.println(array[i]);
}
}
public static void main(String[] args) throws Exception {
test_array test_array = new test_array(10);
test_array.insert(3,0);
test_array.insert(7,1);
test_array.insert(9,2);
test_array.insert(5,3);
test_array.insert(6,1);
test_array.output();
}
}
链表:随机存储
单链表
- 1.查找节点:时间复杂度:O(n)
从头节点开始向后一个一个节点逐一查找 - 2.更新节点:旧数据替换成新数据即可,时间复杂度:O(1)
- 3.插入节点:尾部插入、中间插入、头部插入,时间复杂度:O(1)
尾部插入:把最后一个节点的next指针指向新插入的节点
头部插入:把新节点的next指针指向原先的头节点
把新节点变成链表的头节点
中间插入:插入位置的前置节点的next指针指向插入的新节点
将新节点的next指针指向前置节点的next指针原先所指向的节点 - 4.删除节点:尾部删除、头部删除、中间删除,时间复杂度:O(1)
尾部删除:直接将倒数第二个节点的next指针指向空即可
头部删除:链表的头节点设为原先头节点的next指针即可
中间删除:把删除及诶单的前置节点的next指针指向要删除元素的下一个节点
MyLinkedList.java
package array;/**
* Copyright (C), 2019-2020
* author candy_chen
* date 2020/6/18 21:36
* version 1.0
* Description: 单链表的增删改查
*/
/**
*
*/
public class MyLinkedList {
//头节点指针
private Node head;
//尾节点指针
private Node last;
//链表实际长度
private int size;
/**
* 链表插入元素
* @param data 插入元素
* @param index 插入位置
*/
public void insert(int data,int index) throws Exception {
if (index < 0 || index > size){
throw new IndexOutOfBoundsException("超出链表节点范围");
}
Node insertedNode = new Node(data);
if (size == 0){
head = insertedNode;
last = insertedNode;
}else if (index == 0) {
//插入头部 把新节点的next指针指向原先的头节点
// 把新节点变成链表的头节点
insertedNode.next = head;
head = insertedNode;
}else if (size == index){
//插入尾部 把最后一个节点的next指针指向新插入的节点
last.next = insertedNode;
last = insertedNode;
}else{
//插入中间 插入位置的前置节点的next指针指向插入的新节点
// 将新节点的next指针指向前置节点的next指针原先所指向的节点
Node prevNode = get(index -1);
Node nextNode = prevNode.next;
prevNode.next = insertedNode;
insertedNode.next = nextNode;
}
//插入元素后需要给链表长度加一
size++;
}
/**
* 链表删除元素
* @param index 删除的位置
* @return removeNode 返回删除的节点
*/
public Node remove(int index){
if (index < 0||index >= size){
throw new IndexOutOfBoundsException("超出链表节点范围!!");
}
Node removeNode = null;
if (index == 0){
//删除头节点 链表的头节点设为原先头节点的next指针即可
removeNode = head;
head = head.next;
}else if (index == size-1){
//删除尾节点 直接将倒数第二个节点的next指针指向空即可
Node prevNode = get(index -1);
removeNode = prevNode.next;
prevNode.next = null;
last = prevNode;
}else {
//删除中间节点 把删除及诶单的前置节点的next指针指向要删除元素的下一个节点
Node prevNode = get(index -1);
Node nextNode = prevNode.next.next;
removeNode = prevNode.next;
prevNode.next = nextNode;
}
size--;
return removeNode;
}
/**
* 查找链表元素
* @param index 查找的位置
* @return temp
*/
private Node get(int index) {
if (index < 0 || index >= size){
throw new IndexOutOfBoundsException("超出链表节点范围");
}
Node temp = head;
for (int i = 0;i<index;i++){
temp = temp.next;
}
return temp;
}
/**
* 输出链表
*/
public void output(){
Node temp = head;
while (temp != null){
System.out.println(temp.data);
temp = temp.next;
}
}
/**
* 链表节点
*/
private static class Node{
int data;
Node next;
public Node(int data) {
this.data = data;
}
}
public static void main(String[] args) throws Exception {
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.insert(3,0);
myLinkedList.insert(7,1);
myLinkedList.insert(9,2);
myLinkedList.insert(5,3);
myLinkedList.output();
System.out.println("------------------");
myLinkedList.insert(6,1);
myLinkedList.output();
System.out.println("------------------");
myLinkedList.remove(0);
myLinkedList.output();
System.out.println("------------------");
}
}
如何判断链表有环?
栈:
先进后出,FILO
- 入栈 时间复杂度:O(1)
- 出栈 时间复杂度:O(1)
MyStack.java
package array;/**
* Copyright (C), 2019-2020
* author candy_chen
* date 2020/6/19 20:10
* version 1.0
* Description: 测试
*/
/**
*
*/
public interface MyStack<Item> extends Iterable<Item> {
MyStack<Item> push(Item item);
Item pop() throws Exception;
boolean isEmpty();
int size();
}
ArrayStack.java
package array;/**
* Copyright (C), 2019-2020
* author candy_chen
* date 2020/6/19 20:09
* version 1.0
* Description: 测试
*/
import java.util.Iterator;
/**
*
*/
public class ArrayStack<Item> implements MyStack<Item> {
//栈元素数组,只能通过转型来创建泛型数组
private Item[] a = (Item[]) new Object[1];
//元素数量
private int N = 0;
@Override
public MyStack<Item> push(Item item) {
check();
a[N++] = item;
return this;
}
private void check() {
if (N > a.length){
resize(2 * a.length);
}else if (N > 0 && N<= a.length /4){
resize(a.length /2);
}
}
private void resize(int size) {
Item[] tmp = (Item[]) new Object[size];
for (int i = 0; i < N; i++) {
tmp[i] = a[i];
}
a = tmp;
}
@Override
public Item pop() throws Exception {
if (isEmpty()) {
throw new Exception("stack is empty");
}
Item item = a[--N];
check();
// 避免对象游离
a[N] = null;
return item;
}
@Override
public boolean isEmpty() {
return N == 0;
}
@Override
public int size() {
return N;
}
@Override
public Iterator<Item> iterator() {
// 返回逆序遍历的迭代器
return new Iterator<Item>() {
private int i = N;
@Override
public boolean hasNext() {
return i > 0;
}
@Override
public Item next() {
return a[--i];
}
};
}
}
队列:
先进先出 FIFO
出口端叫队头,入口端叫队尾
- 循环队列:
队列满了的判定条件: (队尾下标 + 1) % 数组长度 = 队头下标
(rear + 1 )%array.length == front
队列最大容量比数组长度小1 - 双端队列:
结合了栈和队列的特点,既可以先进先出,也可以先入后出
从队头一端可以出队或入队,从队尾一端也可以出队或入队 - 优先队列:
谁的优先级高,谁先出队(二叉堆实现的)
MyQueue.java
package array;/**
* Copyright (C), 2019-2020
* author candy_chen
* date 2020/6/19 11:12
* version 1.0
* Description: 循环队列
*/
/**
*
*/
public class MyQueue {
private int[] array;
private int front;
private int rear;
public MyQueue(int capacity){
this.array = new int[capacity];
}
/**
* 入队
* @param element 入队的元素
* @throws Exception 队列已满
*/
public void enQueue(int element) throws Exception {
if ((rear + 1 )%array.length == front){
throw new Exception("队列已满");
}
array[rear] = element;
rear = (rear + 1)%array.length;
}
/**
* 出队
* @return
* @throws Exception
*/
public int deQueue() throws Exception {
if (rear == front){
throw new Exception("队列已空!");
}
int deQueueElement = array[front];
front = (front+1)%array.length;
return deQueueElement;
}
/**
* 输出队列
*/
public void output(){
for (int i = front;i!= rear;i=(i + 1)%array.length){
System.out.println(array[i]);
}
}
public static void main(String[] args) throws Exception {
MyQueue myQueue = new MyQueue(6);
myQueue.enQueue(3);
myQueue.enQueue(5);
myQueue.enQueue(6);
myQueue.enQueue(8);
myQueue.enQueue(1);
myQueue.deQueue();
myQueue.deQueue();
myQueue.deQueue();
myQueue.enQueue(2);
myQueue.enQueue(4);
myQueue.enQueue(9);
myQueue.output();
}
}
散列表(哈希表):hash table
散列表实现类(HashMap),提供了键(Key)和值(Value)的映射关系,只要给出一个Key就可以高效的找出匹配的Value,时间复杂度:O(1)
基本原理:
- 本质上是一个数组
1. 哈希函数
通过某种方式,把Key和数组下标进行转换,这个转换的中转站就叫做哈希函数
-
hashcode
-
HashMap
通过哈希函数,我们可以把字符串或者其他类型的key转换成数组的下标index,想要转化成数组的下标,做简单的转换方式是按照数组长度当进行取模运算
index = HashCode(key) % Array.length
例:给出一个长度为8的数组,当
key = 5720153303时,
index = HashCode(“5720153303”) % Array.length = 1420036703 % 8 = 7
key = this时,
index = HashCode(“this”) % Array.length = 3559070 % 8 = 6
2.散列表的读写操作:
(1) 写操作:put
就是在散列表中插入新的键值对(Entry) hashMap.put(“2020619”,“张三”)
哈希冲突:
数组的长度有限,当插入的Entry越来越多时,不同的Key通过哈希函数获得的下标有可能是相同的,则产生哈希冲突
解决方法:
-
-
开放寻址法
原理:当一个Key通过哈希函数获得对应的数组下标已经被占用时,则寻找下一个空档位置
应用:在java中,ThreadLocal使用的就是开放寻址法 -
-
链表法
原理:HashMap数组的每一个元素不仅是一个Entry对象,还是一个链表的头节点,每一个Entry对象通过next指针指向它的下一个Entry节点
当新的Entry映射与之冲突时,则与该位置为头节点,插入到该链表中
应用:java中的HashMap
(2) 读操作:get
通过给定的Key,在散列表中查找对应的Value
步骤:
-
-
通过哈希函数,把Key转换成数组下标
-
-
如果不冲突,则返回对应的Value; 如果冲突,则顺着链表往下找,查找匹配的节点
(3) 扩容:resize
-
当大量元素拥挤在相同数组下标位置,形成很长的链表,对后续插入和查询会有很大影响,则需要对散列表进行扩容
散列表实现类(HashMap)而言,扩容因素: -
-
Capacity,即HashMap的当前长度
-
-
LoadFactor,即HashMap的负载因子,默认为0.75f
扩容条件:HashMap.Size >= Capacity x LoadFactor
扩容步骤:
-
-
扩容:创建一个新的Entry数组,长度为原来的2倍
-
-
重新Hash:遍历元Entry数组,把原来的Entry重新Hash到新数组中。
重新Hash是因为长度扩大,Hash的规则也随之改变。原本拥挤的散列表重新变得稀疏,原来的Entry也红心得到尽可能的均匀分配
说明:根据网络资料进行搜索学习理解整理 若有侵权联系作者
- 参考书籍:漫画算法-小灰的算法之旅

- 【数据结构与算法】第二章 数组、链表、栈和队列(基础)
- 数据结构基础-(数组、链表、优先队列...)
- 【数据结构与算法基础】以数组实现的循环队列 / Circular Queue implemented by array
- 基础数据结构(栈,队列,数组,链表)
- JavaScript 数据结构与算法之美 - 线性表(数组、栈、队列、链表)
- 【数据结构与算法学习笔记】PART3 线性结构(除向量外,数组、栈、队列、链表)
- 数据结构和算法 (二)数据结构基础、线性表、栈和队列、数组和字符串
- 【算法学习笔记】07.数据结构基础 链表 初步练习
- 基础数据结构之数组与链表(二)
- 数据结构之用数组和链表实现队列
- 【算法学习笔记】07.数据结构基础 链表 初步练习
- 学点PYTHON基础的东东--数据结构,算法,设计模式---单向链表
- php学习第一章:PHP基础语法(三)数据结构与算法:2、单向链表
- (4) 数据结构与算法 ---- 线性表 及Java实现 顺序表、链表、栈、队列
- 数据结构之数组实现基础队列结构
- 数据存储的常用结构 堆栈、队列、数组、链表
- 【数据结构与算法】数组和单链表转平衡二叉树
- Java之美[从菜鸟到高手演变]之数据结构基础、线性表、栈和队列、数组和字符串
- 数据结构之栈、队列、数组、链表和红黑树
- 基础数据结构之数组与链表(五)