在Deepin(深度)操作系统上使用docker在idea中搭建一个简单的Hadoop集群(二)
2020-07-15 06:14
483 查看
本文直接承接上一份博客具体详情不再过多赘述
第一部分传送门:https://blog.csdn.net/welson650/article/details/105280996
五、idea操作部分
5.用上面的新建指令或者直接右键在hadoop文件夹下新建config文件夹,并导入/编写配置文件(配置文件共9个,1-4见上一篇):
(5)mapred-env.sh:
mapred-env.sh配置文件
(6)mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-master:19888</value> </property> </configuration>
(7)slaves(工作节点):
hadoop-slave1 hadoop-slave2
(8)yarn-env.sh:
yarn-env.sh配置文件
(9)yarn-site.xml:
<?xml version="1.0"?> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-master</value> </property> </configuration>
6.在day2下新建docker-compose.yml配置文件:
version: '3' services: hadoop-master: image: test/hadoop container_name: hadoop-master networks: - test-net stdin_open: true # -i interactive tty: true # -t tty entrypoint: [ "sh", "-c", "service ssh start; bash"] volumes: - ./data/master:/data hadoop-slave1: image: test/hadoop container_name: hadoop-slave1 networks: - test-net stdin_open: true tty: true entrypoint: ["sh" ,"-c","service ssh start; bash"] volumes: - ./data/slave1:/data hadoop-slave2: image: test/hadoop container_name: hadoop-slave2 networks: - test-net stdin_open: true tty: true entrypoint: ["sh" ,"-c","service ssh start; bash"] volumes: - ./data/slave2:/data networks: test-net: external: false
7.在day2下新建install.sh,并编写代码,执行安装操作:
#!/bin/bash echo "===========自动化安装Hadoop===========" echo "系统要求1.安装了docker 2安装了docker-compose" read -r -p "准备好了吗? [Y/n] " envConfirm case $envConfirm in [yY][eE][sS]|[yY]) echo "Yes 继续执行" ;; [nN][oO]|[nN]) echo "No 终止执行" exit 1 ;; *) echo "Invalid input... 终止执行" exit 1 ;; esac if [ -d "$PWD/data/" ];then sudo rm -rf $PWD/data fi mkdir -p $PWD/data/ cd hadoop docker build -t test/hadoop . cd - docker-compose -f docker-compose.yml up -d echo "集群构建成功"
8.在day2目录下,运行
bash install.sh指令看到
hadoop-master done hadoop-slave1 done hadoop-slave2 done
即证明节点创建成功。
进入http://localhost:9000/#/containers查看节点状态,可以看到三个节点状态均为Running。
9.启动Hadoop的hdfs和yarn服务:
(1)输入
docker exec -it hadoop-master bash进入该集群的hadoop-master节点,依次执行如下代码,获取三台机器之间的访问权限,如果中途需要输入yes/no输入yes即可,切记每次ssh后一定要exit,不然后续可能报错。
ssh hadoop-master exit ssh hadoop-slave1 exit ssh hadoop-slave2 exit
(2)全部执行无误后,在hadoop-master上运行
hdfs namenode -format进行格式化(此处无需进行切换直接输入指令,回车即可)。
(3) 成功后,运行
start-dfs.sh指令,待执行成功后,可以查看***:500070(***为localhost:9000上查到的hadoop-master节点的ip地址),看到如下效果则说明运行正常:
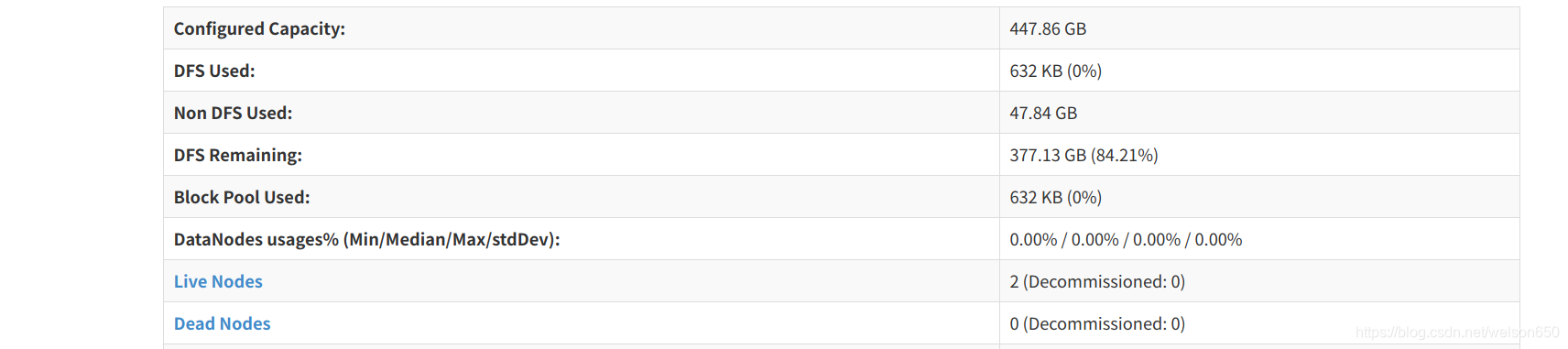
(4)这一步运行成功后,执行
start-yarn.sh启动yarn服务,一般上一步能够成功这一步就不会报错。
(5)执行
mr-jobhistory-daemon.sh start historyserver开启JobHistoryServer服务。
(6)待上一步运行完成后,输入jps可以看到namenode,ResourceManager, Jps,SecondaryNameNode,JobHistoryServer(hadoop-master)五个进程,hadoop-slave里面有jps,nodemanager,datanode三个进程,说明执行成功,此时这个简单的hadoop集群就搭建完成了。
注:(1)关闭集群时应先关闭服务,先后执行下面两条指令完成退出操作:
stop-all.sh exit
(2)第二次启动时,不要执行
bash install.sh,这样会导致集群被覆盖,节点过期。
应执行
docker-compose -f docker-compose.yml up -d,然后执行
docker exec -it hadoop-master bash进入集群,不需要输入格式化指令(仅第一次启动时执行),完成后续操作。

相关文章推荐
- 使用docker搭建hadoop分布式集群
- 使用docker搭建hadoop分布式集群
- 使用Docker在本地搭建Hadoop分布式集群
- 基于Docker搭建Hadoop集群(ubuntu操作系统)
- 使用Docker搭建Hadoop集群
- CentOS7中使用Docker简单搭建RabbitMQ集群
- 使用docker搭建弹性hadoop集群
- 用Docker在一台笔记本电脑上搭建一个具有10个节点7种角色的Hadoop集群(上)-快速上手Docker
- 使用Docker在本地搭建Hadoop分布式集群 的错误总结(持续更新)
- 使用Docker在本地搭建Hadoop分布式集群
- 使用idea搭建一个简单的SSM框架:(1)使用idea创建maven项目
- 使用Docker搭建hadoop集群
- 【大数据平台技术】—— 使用Docker搭建Hadoop分布式集群 —— 酱懵静
- 使用idea搭建一个简单的SSM框架:(3)配置spring+mybatis
- 详解从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
- 使用docker搭建hadoop分布式集群
- 使用Docker在本地搭建Hadoop分布式集群
- 如何使用一个IP搭建ES集群——Docker如你所愿
- 16 :使用docker搭建hadoop分布式集群
- 详解使用docker搭建hadoop分布式集群