Python之常用模块&包
Python之常用模块&包
一、模块&包概念
1.1 模块的概念
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中
一个.py文件就称之为一个模块(Module)。
使用模块有什么好处
最大的好处是大大提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块一共三种:
(1)python标准库
(2)第三方模块
(3)应用程序自定义模块
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
1.2 包(package)
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名:
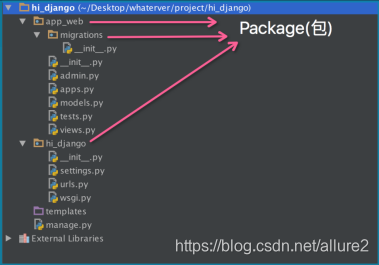
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,view.py模块的名字就变成了hello_django.app01.views,类似的,manage.py的模块名则是hello_django.manage。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。init.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
调用包就是执行包下的__init__.py文件
二、软件目录结构规范
2.1 为什么要设计好目录结构
“设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。
对于这种风格上的规范,一直都存在两种态度:
一类同学认为,这种个人风格问题"无关紧要”。理由是能让程序work就好,风格问题根本不是问题。
另一类同学认为,规范化能更好的控制程序结构,让程序具有更高的可读性。
我是比较偏向于后者的,因为我是前一类同学思想行为下的直接受害者。我曾经维护过一个非常不好读的项目,其实现的逻辑并不复杂,但是却耗费了我非常长的时间去理解它想表达的意思。从此我个人对于提高项目可读性、可维护性的要求就很高了。"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
所以,我认为,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿
2.2 目录组织方式
关于如何组织一个较好的Python工程目录结构,已经有一些得到了共识的目录结构。在Stackoverflow的这个问题上,能看到大家对Python目录结构的讨论。
这里面说的已经很好了,我也不打算重新造轮子列举各种不同的方式,这里面我说一下我的理解和体会。
假设你的项目名为foo, 我比较建议的最方便快捷目录结构这样就足够了:
Foo/ |-- bin/ | |-- foo | |-- foo/ | |-- tests/ | | |-- __init__.py | | |-- test_main.py | | | |-- __init__.py | |-- main.py | |-- docs/ | |-- conf.py | |-- abc.rst | |-- setup.py |-- requirements.txt |-- README 1.bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。 2.foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。 3.docs/: 存放一些文档。 4.setup.py: 安装、部署、打包的脚本。 5.requirements.txt: 存放软件依赖的外部Python包列表。 6.README: 项目说明文件。
2.2.1 关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
1.软件定位,软件的基本功能。
2.运行代码的方法: 安装环境、启动命令等。
3.简要的使用说明。
4.代码目录结构说明,更详细点可以说明软件的基本原理。
5.常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
2.2.2 关于requirements.txt和setup.py
setup.py
一般来说,用setup.py来管理代码的打包、安装、部署问题。业界标准的写法是用Python流行的打包工具setuptools来管理这些事情。这种方式普遍应用于开源项目中。不过这里的核心思想不是用标准化的工具来解决这些问题,而是说,一个项目一定要有一个安装部署工具,能快速便捷的在一台新机器上将环境装好、代码部署好和将程序运行起来。
这个我是踩过坑的。
我刚开始接触Python写项目的时候,安装环境、部署代码、运行程序这个过程全是手动完成,遇到过以下问题:
1.安装环境时经常忘了最近又添加了一个新的Python包,结果一到线上运行,程序就出错了。
2.Python包的版本依赖问题,有时候我们程序中使用的是一个版本的Python包,但是官方的已经是最新的包了,通过手动安装就可能装错了。
3.如果依赖的包很多的话,一个一个安装这些依赖是很费时的事情。
4.新同学开始写项目的时候,将程序跑起来非常麻烦,因为可能经常忘了要怎么安装各种依赖。
setup.py可以将这些事情自动化起来,提高效率、减少出错的概率。"复杂的东西自动化,能自动化的东西一定要自动化。"是一个非常好的习惯。
setuptools的文档比较庞大,刚接触的话,可能不太好找到切入点。学习技术的方式就是看他人是怎么用的,可以参考一下Python的一个Web框架,flask是如何写的: setup.py
requirements.txt
这个文件存在的目的是:
1.方便开发者维护软件的包依赖。将开发过程中新增的包添加进这个列表中,避免在setup.py安装依赖时漏掉软件包。
2.方便读者明确项目使用了哪些Python包。
这个文件的格式是每一行包含一个包依赖的说明,通常是flask>=0.10这种格式,要求是这个格式能被pip识别,这样就可以简单的通过 pip install -r requirements.txt来把所有Python包依赖都装好了。具体格式说明: 点这里。
2.2.3 关于配置文件的使用方法
注意,在上面的目录结构中,没有将conf.py放在源码目录下,而是放在docs/目录下
很多项目对配置文件的使用做法是:
1.配置文件写在一个或多个python文件中,比如此处的conf.py。
2.项目中哪个模块用到这个配置文件就直接通过import conf这种形式来在代码中使用配置。
这种做法我不太赞同:
1.这让单元测试变得困难(因为模块内部依赖了外部配置)
2.另一方面配置文件作为用户控制程序的接口,应当可以由用户自由指定该文件的路径。
3.程序组件可复用性太差,因为这种贯穿所有模块的代码硬编码方式,使得大部分模块都依赖conf.py这个文件。
所以,我认为配置的使用,更好的方式是,
1.模块的配置都是可以灵活配置的,不受外部配置文件的影响。
2.程序的配置也是可以灵活控制的。
能够佐证这个思想的是,用过nginx和mysql的同学都知道,nginx、mysql这些程序都可以自由的指定用户配置。
所以,不应当在代码中直接import conf来使用配置文件。上面目录结构中的conf.py,是给出的一个配置样例,不是在写死在程序中直接引用的配置文件。可以通过给main.py启动参数指定配置路径的方式来让程序读取配置内容。当然,这里的conf.py你可以换个类似的名字,比如settings.py。或者你也可以使用其他格式的内容来编写配置文件,比如settings.yaml之类的。
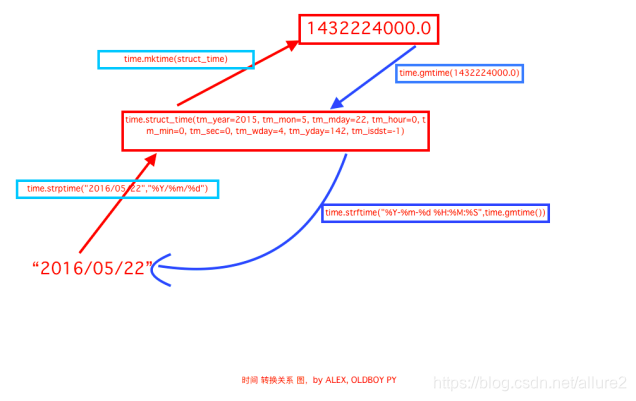
三、time模块
详情见代码:D:\code\PycharmProjects\pythonProject\Function\时间模块.py
四、random模块
4.1 生成随机数
详情见代码:D:\code\PycharmProjects\pythonProject\Function\ 随机数模块.py
iimport random
print(random.random()) # 打印一个随机数,范围是0-1
print(random.randint(1,8)) # 打印1-8的随机整数,包含8
print(random.choice('hello')) # 随机打印一个字母
4.2 生成随机验证码
import random def voiled_code(): code = '' for i in range(6): add = random.choice([random.randrange(10), chr(random.randrange(65, 90))]) code += str(add) return code print(voiled_code())
五、OS模块
代码详见:D:\code\PycharmProjects\pythonProject\module\ OS_module.py
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 只能删除文件,不能删除文件夹
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
六、SYS模块
代码详见:D:\code\PycharmProjects\pythonProject\module\ SYS_module.py
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
七、hashlib模块
代码详见:D:\code\PycharmProjects\pythonProject\module\ hashlib_module.py
对文件进行加密:两种方式(md5、sha256)
方式一:使用md5方式进行加密
import hashlib
m = hashlib.md5() # 使用md5加密算法
print(m) # <md5 HASH object @ 0x0000026CAB44F788>
m.update('hello world!!!'.encode('utf-8')) # 进行加密
print(m.hexdigest()) # 取值 f6835168c4823ac89c1bc97154a675a8
m.update('allure'.encode('utf-8')) # 在之前的基础上,进行加密
print(m.hexdigest())
# 等同于上面一样
m2 = hashlib.md5() # 使用md5加密算法
m2.update('hello world!!!allure'.encode('utf-8')) # 进行加密
print(m2.hexdigest()) # 取值 f6835168c4823ac89c1bc97154a675a8
方式二:使用sha256方式进行加密
m = hashlib.sha256()
m.update('hello world!!!allure'.encode('utf-8'))
print(m.hexdigest()) # 18c37412288f1f79fe86eb13d5cb6a53d5b4c946390f576b7088ed3cabc009b2
八、logging&logger模块
8.1 简单应用
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
8.2 配置logging,日志格式,输出位置
# 将日志输出到文件中
'''
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
'''
import logging
# 可以灵活的设置logging要展示的级别
logging.basicConfig(level=logging.DEBUG,
# 时间 文件名字 行号 级别名字 内容
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
# 时间格式
datefmt='%a, %Y %b %d %H:%M:%S',
# 文件名字
filename='test.log',
# 文件模式 w:覆盖之前的问价内容 a:追加内容到文件中
filemode='a')
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
format参数中可能用到的格式化串:
""" %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息 """
8.3 logger配置
代码详见:D:\code\PycharmProjects\pythonProject\module\ logging_logger_module.py
可以将日志文件输出到文件中和控制台中
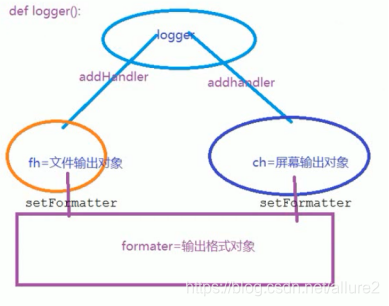
import logging
logger = logging.getLogger()
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log')
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
九、configParser模块(用于生成和修改软件的配置文件)
基本不用
9.1 创建配置文件
1、获取配置文件的对象
2、添加配置文件内容
3、将配置文件写入到本地
import configparser
# 获取配置文件的对象
config = configparser.ConfigParser()
# 创建模块
config["DEFAULT"] = {'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'}
config['DEFAULT']['ForwardX11'] = 'yes' # 在default模块中添加一个属性
config['bitbucket.org'] = {
'USER': 'hg'}
config['topsecret.server.com'] = {} # 创建空模
# 给空模块添加属性
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
# 将配置文件写入到文本中 ,将会生成一个example.ini文件
with open('example.ini', 'w') as configfile:
config.write(configfile)
9.2 读取配置文件
代码详见:D:\code\PycharmProjects\pythonProject\module\ – configParser_module.py
import configparser
# 获取配置文件的对象
config = configparser.ConfigParser()
# 读取配置文件
config.read('example.ini')
print(config.sections())
print(config.defaults()) # 读取default的内容
print(config['bitbucket.org']['user']) # 获取某一个属性的值
# 打印其他配置文件属性的时候,default会打印出来
for key in config['bitbucket.org']:
print(key)
9.3 修改配置文件(创建配置文件,之后覆盖配置文件)
config.set('bitbucket.org', 'user', 'allure')
config.write(open('example.ini', 'w'))
9.4 删除配置文件的某一个模块
config.remove_section('bitbucket.org')
config.write(open('example.ini', 'w'))
9.5 删除配置文件某一模块下的某个属性
config.remove_option('bitbucket.org', 'user')
config.write(open('example.ini', 'w'))
十、RE模块
代码详见:D:\code\PycharmProjects\pythonProject\module\ – RE.py
10.1 由来
python提供的string匹配无法满足现实的需求,eg:匹配手机号、邮箱需要模糊匹配,so出现了正则表达式。
10.2 用来做什么
匹配字符串
10.3 简介
就本质而言,正则表达式(或RE)是一种小型的、高度专业化的编程语言,(在python中)他内嵌在python中,并通过re模块实现。正则表达式模块被编译成一系列的字节码,然后由用C编写的匹配引擎执行。
10.4 字符匹配(普通字符,元字符)
10.4.1 普通字符
大多数字符和字母都会和自身匹配
re.findall(‘allure’, ‘helloallure’)
10.4.2 11个元字符(. ^ $ * + ? {} [] | () \ )
.(通配符):只能代指任意的一位字符,除了换行符
^(尖角符):从字符串的开始进行匹配,其他位置无关
$(结束符):匹配字符串的结束位置
*(重复匹配符):匹配0-多个字符
+(重复匹配符):匹配1-多个字符
?(0 or 1次符):匹配0 or 1次
{}(指定重复匹配符):匹配指定的次数,eg:{3}:匹配3次;{1,3}:匹配1-3次
(字符集)[ ]:多选一
eg:
[a,b,c]:a,b,c的任意一个字母
[a-z]:a-z的任意一个小写字母
[A-Z]:A-Z的任意一个大写字母
[0-9]:0-9的任意一个数字
[w, *]:取消元字符的特殊功能
[^a]:匹配取反
|(管道符):代表 或者 的意思;eg:(ab|c)
()(分组符):()里面的是一组
(反斜杠符):
\:
反斜杠后边跟元字符去除特殊功能,
反斜杠后边跟普通字符实现特殊功能。
引用序号对应的字组所匹配的字符串
\d:匹配任何十进制数;它相当于类[0-9]。
\D:匹配任何非数字字符;它相当于类[^0-9]。
\s:匹配任何空白字符;它相当于类[\t\n\r\f\v]。
\s:匹配任何非空白字符;它相当于类[^\t\n\r\f\v]。
\w:匹配任何字母数字字符;它相当于类[a-zA-20-9]。
\W:匹配任何非字母数字字符;它相当于类[^a-zA-20-9]
\b:匹配一个单词边界,也就是指单词和空格间的位置。
10.4.3 结论
(* == {0, +无穷大}; + == {1, +无穷大} == {1,}; ? == {0,1})
我们首先考察的元字符是"[“和”]"。他们常用来指定一个字符类别,所谓字符类别就是你想匹配的一个字符集。字符可以单个列出,也可以用"-“号分隔的两个给定字符来表示一个字符区间。例如,[abc]将匹配"a”,“b”,或"c"中的任意个字符:也可以用区间[a-c]来表示同一个字符集,和前者效果一致。如果你只想匹配小写字母,那么RE应写成[a-z]
元字符在类别里并不起作用。例如,[akm]将匹配字符"a","k","m",或"]将匹配字符"a","k","m",或"]将匹配字符"a","k","m",或""中的任意一个;"$"通常用作元字符,但在字符类别里,其特性被除去,回复称普通字符
10.5 常用方法
findall():查找所有复合的条件 search():返回一个对象,需要group():匹配出第一个满足条件的结果 match():只在字符串开始匹配,也只返回一个对象,使用group()返回结果 split():根据指定的字符串切分 sub():替换指定的字符串 subn():替换指定的字符串,并返回替换了几次 compile(): 这个方法是Patten类的工厂方法,用于将字符串形式的正则表达式编译为Patten对象。第二个参数flag是匹配模式,取值可以使用安慰或运算符'|'表示同时生效,比如re.I | re.M 可以把正则表达式建议称一个正则表达式对象。可以把那些经常使用正则表达式编译成正则表达式对象,这样可以提高一定的效率
十一、json&pickle序列化模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json x="[null,true,false,1]" print(eval(x)) print(json.loads(x))
11.1 什么是序列化
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
11.2 json
代码详见:D:\code\PycharmProjects\pythonProject\module\ – json_mudole.py
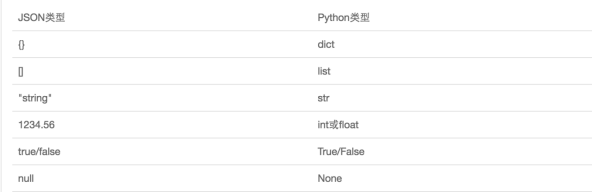
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下
方式一:使用dumps/loads,手动read/write
import json
# 将数据写入到到文件中
dic = {'name': 'allure', 'age': '23', 'sex': 'man'}
data = json.dumps(dic)
f = open('json.txt', 'w')
f.write(data)
f.close()
# 将数据从文件中读取出来
f2 = open('json.txt', 'r')
data = f2.read()
data = json.loads(data)
print(data)
print(data['name'])
print(data['age'])
print(data['sex'])
方式二:使用dump/load,python自动read/write
import json
# 将数据写入到到文件中
dic = {'name': 'allure', 'age': '23', 'sex': 'man', 'hobby': 'gile'}
f = open('json.txt', 'w')
data = json.dump(dic, f)
f.close()
# 将数据从文件中读取出来
f2 = open('json.txt', 'r')
data = json.load(f2)
print(data)
print(data['name'])
print(data['age'])
print(data['sex'])
11.3 pickle
代码详见:D:\code\PycharmProjects\pythonProject\module\ – pickle_module.py
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
也有两种方式,此处只介绍一种,和json一样
import pickle
# 将函数数据写入到文件中
def foo():
print('ok')
data = pickle.dumps(foo)
f = open('PICKLE.txt', 'wb')
f.write(data)
f.close()
# 将函数数据从文件中是读取出来
def foo():
print('ok')
f = open('PICKLE.txt', 'rb')
data = f.read()
data = pickle.loads(data)
print(data())
十二、shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
# 将数据写人到shelve.txt
f = shelve.open('shelve.txt')
f['info1'] = {'sex': 'man', 'naem': 'allure', 'age': '23'}
f['info2'] = {'sex': 'man', 'naem': 'allure', 'age': '23', 'hobby': 'girl'}
f.close()
# 将数据从shelve.txt中读取出来
data = f.get('info1')
print(data)
data = f.get('info2') # data = f.get('info2', 'default'),如果没有参数,直接返回'default'
print(data)
十三、XML模块(很少用,以后用json)
13.1 介绍
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
13.2 xml在python中的模块操作
1、导入框架
import xml.etree.ElementTree as ET
2、查询、修改、删除、创建操作
查询
# 解析xml文件
tree = ET.parse('./data/xml')
# 获取 root
root = tree.getroot()
# 遍历 data 标签
print(root.tag)
# 遍历 xml 文档
''''''
for childs in root:
print(childs.tag, childs.attrib)
for child in childs:
print(child.tag, child.text)
# 只遍历 year 节点
''''''
for node in root.iter('year'):
print(node.tag, node.text)
修改
# 修改
''''''
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated", "yes")
tree.write("./data/xml")
删除
# 删除node
'''''''
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('./data/xml')
创建操作
# 创建XML文件
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml, "name", attrib={"enrolled": "yes"})
age = ET.SubElement(name, "age", attrib={"checked": "no"})
sex = ET.SubElement(name, "sex")
sex.text = '33'
name2 = ET.SubElement(new_xml, "name", attrib={"enrolled": "no"})
age = ET.SubElement(name2, "age")
age.text = '19'
et = ET.ElementTree(new_xml) # 生成文档对象
et.write("./data/test.xml", encoding="utf-8", xml_declaration=True)
ET.dump(new_xml) # 打印生成的格式
九、应用
计算器的代码:D:\code\PycharmProjects\pythonProject\module\ --计算器.py

- Python成长之路(常用模块学习)
- Python常用模块os & sys & shutil模块
- Python常用操作系统及内置模块命令
- 【python】os和os.path模块及其常用函数方法
- python-nmap模块常用方法说明
- python中常用的正则模块学习
- [转]常用的python模块及安装方法
- Python 常用模块
- 2.2.0 Python常用模块一
- Python模块常用的几种安装方式
- python os模块 常用命令
- python 常用的模块(hashlib)转
- 常用的python模块及安装方法
- os---Python里的OS模块常用函数说明
- python 常用模块详解
- python time模块常用函数
- 【七月Python入门】 第七课并发编程以及系统常用模块
- Python 模块之Logging(四)——常用handlers的使用
- Python运维中20个常用的库和模块
- python 常用模块的使用