论文笔记——Permutohedral-GCN: Graph Convolutional Networks with Global Attention
【论文笔记】Permutohedral-GCN: Graph Convolutional Networks with Global Attention
作者:HeshamMostafa,MarcelNassar
代码:无
摘要
图卷积网络(GCNs)通过聚集图中邻居节点的特征来更新节点的特征向量。这会忽略来自遥远节点的潜在有用贡献。本文引入了一种全局注意力机制,其中一个节点可以有选择地关注并聚合图中任何其他节点的特征。注意力系数依赖于可学习的节点嵌入之间的欧氏距离,我们证明了基于注意力的全局聚集方案类似于高维高斯滤波。通过采用基于permutohedral lattice的近似滤波方法,我们提出的全局聚合方案的时间复杂度仅随节点数线性增长。由此产生的GCN,称之为permutohedral-GCNs。它们在多个节点分类基准上实现了最新的性能。
创新点
- 提出了全局注意力机制
- 采用permutohedral lattice的近似滤波方法
- 与GAT不同,本文的注意力系数依赖于可学习的节点嵌入之间的欧氏距离
解决的问题
- 解决了聚合范围有限,忽略距离较远但有用的节点信息的问题
- 两个相邻节点可以从两个非常不同的节点集合中聚合信息,减轻了过平滑问题
模型
模型架构
由于在基于注意力的全局聚集方案中不考虑图结构,因此将全局聚集方案获得的节点特征与传统聚集方法从节点的图邻域获得的节点特征连接起来。因此,一半的节点特征向量是由图中所有节点的注意力加权聚集得到的,另一半则是由图邻域中的节点的注意力加权聚集得到的。
模型的可学习参数是投影矩阵W∈R^(F’×F)和一组用于对通用注意力函数A进行参数化的参数Φ。节点v_i与v_j之间的未规范化的注意系数由下式给出:
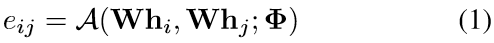
- 结构注意力:只关注节点的邻域
计算结构注意力系数:
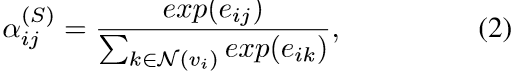
聚集邻居特征:
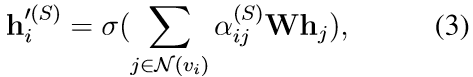
- 全局注意力:关注图中所有节点
计算全局注意力系数:
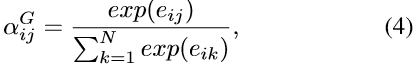
聚集所有特征:
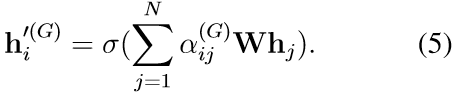
- 将得到的两种特征(结构上聚合的特征向量和全局上聚合的特征向量)连接:
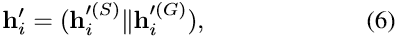
多头注意力,使用A个注意头,输出特征向量的维数为2AF’:
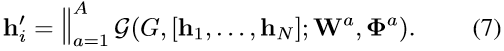
全局注意力机制
非局部滤波
在图像去噪中,与一般统计假设下的局部滤波器相比,非局部图像滤波器具有更好的性能。
对于N个点,假设点i在D-维欧几里德相似空间中具有位置p_i,和一个关联特征向量f_i∈R^F。一般的非局部过滤操作可以写成:
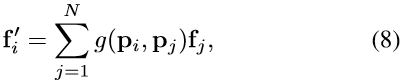
g是加权函数。最常见的加权函数是高斯核exp(-λ^2 ‖p_i-p_j ‖_2^2),我们使用的加权函数是指数衰减核,它产生非局部滤波方程:
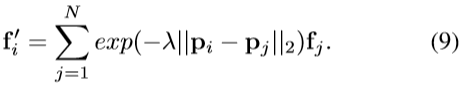
欧式距离
引入了一种基于欧氏距离的注意机制:
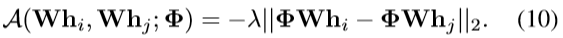
代入公式(4)和(5)
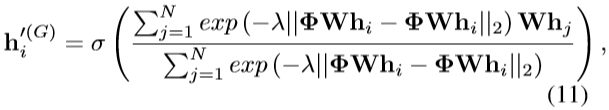
令
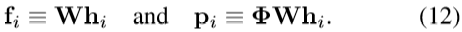
代入公式(11)
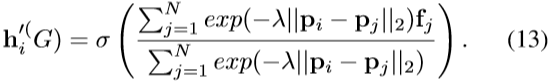
Permutohedral lattice
- 作用:计算每对节点的时间复杂度为𝑂(𝑁^2 ),使用permutohedral lattice近似滤波可将复杂度降为𝑂(𝑁)
- 步骤:
(1)Splatting。𝑝_1,…,𝑝_𝑁被投影到D维多面体晶格的超平面上,所有格点的特征向量、初始化为零。对于每个位置𝑝_𝑖,按其与格点的接近程度对其缩放,将特征𝑓_𝑖添加为每个格点的特征向量(即按距离加权求和)
(2)Blurring。只使用晶格点的一个小邻域来计算晶格点的输出特征,因为来自较远点的贡献很小。关键近似:一个格点仅从其邻域聚集特征,而不是所有格点
(3)Slicing。点𝑝_𝑖的输出特征为其封闭晶格点的特征加权求和

实验
- 基于motif count的节点分类
数据集:生成由两个motifs的随机组合形成的随机图
对比算法:GAT - Transductive节点分类
数据集:
①引文图:Cora、Citeeser、Pubmed
②WebKB图:Cornell、 Texas和、Wisconsin。这些图反映了各大学计算机科学系网页的结构。节点表示网页,边表示网页链接。
③演员共现图:Actor。该图是通过爬取维基百科文章构建的。每个节点代表一个演员,一个边表示一个演员出现在另一个演员的维基百科页面上。节点分为五类。
对比算法:GCN、GAT、Geom-GCN及其变体
实验结果
- 基于motif count的节点分类
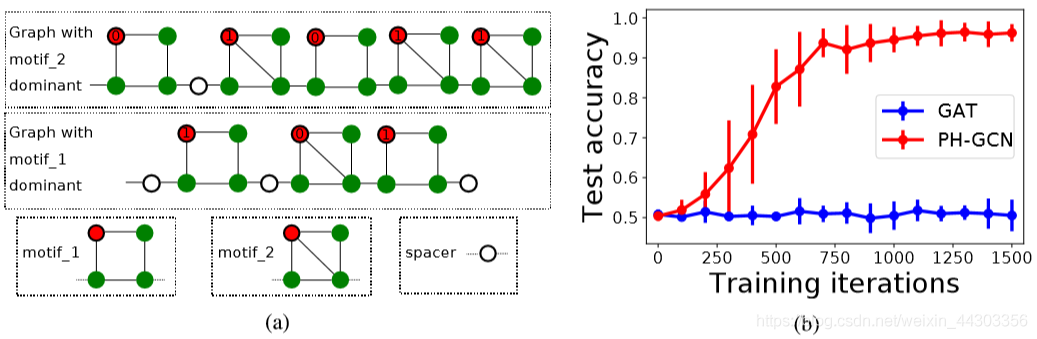
图2(a)归纳节点分类任务中的两个样本图。图具有链式结构,链式中的每个元素可以是motif_1、motif_2或单个节点(间隔节点)。每个节点都连接到自身(未显示自边)。具有相同颜色的节点具有相同的特征向量。红色节点出现在motif_1和motif_2中。其目的是根据图中每个红色节点是否存在于主导motif(即出现频率最高的motif)中来对其进行分类。例如,在中间图中,motif_1占主导地位,因此motif_1中的红色节点具有标签1,motif_2中的红色节点具有标签0(标签显示在节点内部)。(b)GAT和PH-GCN作为训练迭代函数的准确性。10次试验的平均误差和标准误差。 - Transductive节点分类
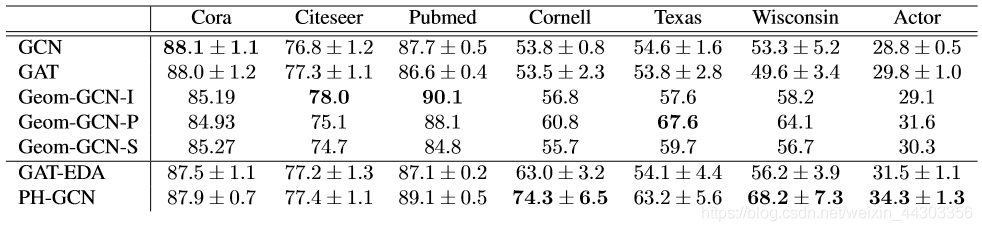
1.对于Cora和Citeseer,PH-GCN的性能与GCN和GAT无显著差异;在Pubmed上,PH-GCN比GCN和GAT有显著改进。在这三个引文图上缺乏一致的主要改进,可以归因于它们的高分类性。其中属于同一类别的节点倾向于连接在一起。在高度分类的图中,由于相似的节点在图中是紧密的,所以节点不需要长距离聚集就可以从相似的节点中积累特征。
2.对于WebKB图和Actor,PH-GCN相对GCN和GAT性能优势巨大。对于WebKB图,由于图很小,精度标准差可能很大,并且训练/验证/测试的差异会显著改变学习问题。
3.对于所有图,PH-GCN要么优于Geom-GCN所有变体,要么优于其中两个。Geom-GCN的一个问题是在训练开始之前必须选择一个嵌入算法来生成固定节点的嵌入,并且没有明确的方法来选择在任务中表现最好的嵌入算法。PH-GCN完全回避了这个问题,在学习任务的同时学习嵌入,从而始终获得高性能。
4.PH-GCN性能明显优于GAT-EDA。GAT-EDA仅仅用欧氏距离注意机制取代GAT中使用的注意机制,没有加入全局注意力。这说明PH-GCN的性能优势并不完全归因于我们使用的新的注意机制,基于全局注意的聚集也起着至关重要的作用。

- 论文笔记:Multi-Label Image Recognition with Graph Convolutional Networks
- 论文笔记之:Semi-supervised Classification with Graph Convolutional Networks
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
- 【论文笔记】An End-to-End Model for QA over KBs with Cross-Attention Combining Global Knowledge
- [深度学习论文笔记][Video Classification] Large-scale Video Classification with Convolutional Neural Networks
- 论文阅读笔记-Segmentation-Aware Convolutional Networks Using Local Attention Masks
- semi_supervised classification with graph convolutional networks论文阅读报告(1)
- 论文笔记之:Graph Attention Networks
- 论文笔记之:Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grained Recognition
- 【转】论文阅读笔记-Segmentation-Aware Convolutional Networks Using Local Attention Masks
- Deep learning论文笔记一:ImageNet Classification with Deep Convolutional Neural Networks
- GRAPH ATTENTION NETWORKS--论文阅读笔记
- IJCAI‘19 Semi-supervised User Profiling with Heterogeneous Graph Attention Networks阅读笔记
- 论文笔记:unsupervised representation learning with deep convolutional generative adversarial networks
- [深度学习论文笔记][Image Classification] ImageNet Classification with Deep Convolutional Neural Networks
- [论文笔记]:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
- 论文笔记:Learning Social Image Embedding with Deep Multimodal Attention Networks
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
- 论文笔记 Visual Tracking with Fully Convolutional Networks
- 经典计算机视觉论文笔记——《ImageNet Classification with Deep Convolutional Neural Networks》