感知器算法原理详解
2020-07-04 18:14
60 查看
感知器是人工神经网络中的一种典型结构, 它的主要的特点是结构简单。它是一种分类学习器,是很多复杂算法的基础。其“赏罚概念”在机器学习算法在中广为应用。在分类正确时,对正确的权重向量w赏,即w不变;当分类错误时,对权重向量罚,即将权重向量w向着争取的方向转变。
算法步骤
在这里先对感知器算法步骤进行说明。
假设有样本集如下图所示,其中xi为样本特征向量,yi为对应样本分类标签。
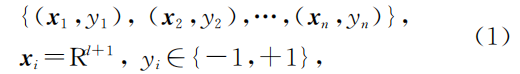
在传统线性可分的二分类情况下,可以使wTx>=0时分类为正样本,wTx<0分类为负样本。
算法步骤如下图所示,对所有负样本乘以-1以方便算法流程,即使wTx>=0时判断为分类正确。
随机生成初始权重向量w0,在每轮迭代中,若样本i分类正确即wTxi>=0时,不对w进行修改;当本轮迭代中,针对样本i出现分类错误,即wTxi<0时,对权重向量w“罚”,使之朝着正确的趋势改进。η为学习率。
在迭代次数t=T时,如果无错误分类,则迭代结束。

算法步骤解释
用错分样本xi作为权重向量的改进尺度,迭代能否收敛呢?答案是肯定的,对于特征向量xi,其内积大于xiTxi必定大于0。即:

而当我们讨论到为什么要用自身样本特征向量xi作为“罚”时,实际上,对于权重向量w,如果某个样本特征向量x被错误分类,则wTx<0。我们可以用对所有错分样本的求和来表示对错分样本的惩罚:

Γ为所有错分样本集。Jp(w)为风险泛函。
对于解向量w*,我们希望它满足以下公式。即无错分样本时,Jp(w*)值为0。实际上,当Jp(w)越趋近于0时,我们可以认为样本越朝着正确的方向前进。

对于Jp(w*)的最小化,可以由梯度下降法求解。t为迭代次数,η为学习率。即:
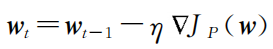
根据上式:

那么,我们最终的迭代方案可以为:


相关文章推荐
- Canny边缘检测算法原理及其VC实现详解(二)
- 今日头条推荐算法原理全文详解之三
- Java贪心算法之Prime算法原理与实现方法详解
- 基于Excel的QR二维码生成工具——原理及算法详解(之四)
- 路由器原理和路由协议、算法详解
- GZIP压缩原理分析(13)——第五章 Deflate算法详解(五04) 预备知识(03) 游程编码
- Canny边缘检测算法原理及其VC实现详解(二)
- 决策树CART算法原理详解
- python实现感知器算法详解
- Canny边缘检测算法原理及其VC实现详解(一)
- 今日头条推荐算法原理全文详解之二
- Canny边缘检测算法原理及其VC实现详解(一)
- Canny边缘检测算法原理及其VC实现详解(一)
- 详解正则表达式匹配算法原理
- GZIP压缩原理分析(21)——第五章 Deflate算法详解(五12) 动态哈夫曼编码分析(01) 本节说明
- KNN(k-nearest neighbor的缩写)最近邻算法原理详解
- [A3C]:算法原理详解
- KNN算法原理详解及python代码实现
- Canny边缘检测算法原理及其VC实现详解(二)
- 今日头条推荐算法原理全文详解之一