12种生成对抗样本的方法
钉钉、微博极速扩容黑科技,点击观看阿里云弹性计算年度发布会!>>>

1 Box-constrained L-BFGS
Szegedy[22] 等人首次证明了可以通过对图像添加小量的人类察觉不到的扰动误导神经网络做出误分类。他们首先尝试求解让神经网络做出误分类的最小扰动的方程。
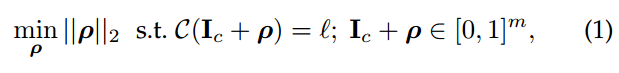
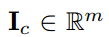 表示一张干净的图片,
表示一张干净的图片,
 是一个小的扰动,l是图像的label,C(`)是深度申请网络分类器。l和原本图像的label不一样。
是一个小的扰动,l是图像的label,C(`)是深度申请网络分类器。l和原本图像的label不一样。
但由于问题的复杂度太高,他们转而求解简化后的问题,即寻找最小的损失函数添加项,使得神经网络做出误分类,这就将问题转化成了凸优化过程。

L(.,.)计算分类器的loss。
2 Fast Gradient Sign Method (FGSM)
Szegedy 等人发现可以通过对抗训练提高深度神经网络的鲁棒性,从而提升防御对抗样本攻击的能力。GoodFellow[23] 等人开发了一种能有效计算对抗扰动的方法。而求解对抗扰动的方法在原文中就被称为 FGSM。
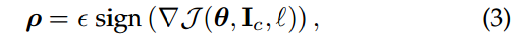
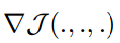 计算损失函数的梯度,sign符号函数。
计算损失函数的梯度,sign符号函数。
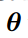 是参数。
是参数。
Miyato et al.[103]:

Kurakin[80] 等人提出了 FGSM 的「one-step target class」的变体。通过用识别概率最小的类别(目标类别)代替对抗扰动中的类别变量,再将原始图像减去该扰动,原始图像就变成了对抗样本,并能输出目标类别。
3 Basic & Least-Likely-Class Iterative Methods
one-step 方法通过一大步运算增大分类器的损失函数而进行图像扰动,因而可以直接将其扩展为通过多个小步增大损失函数的变体,从而我们得到 Basic Iterative Methods(BIM)[35]。而该方法的变体和前述方法类似,通过用识别概率最小的类别(目标类别)代替对抗扰动中的类别变量,而得到 Least-Likely-Class Iterative Methods[35]。
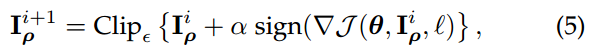
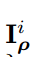 指的是第i次的被扰动的图片,
指的是第i次的被扰动的图片,
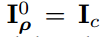 。
。
4 Jacobian-based Saliency Map Attack (JSMA)
对抗攻击文献中通常使用的方法是限制扰动的 l_∞或 l_2 范数的值以使对抗样本中的扰动无法被人察觉。但 JSMA[60] 提出了限制 l_0 范数的方法,即仅改变几个像素的值,而不是扰动整张图像。像素的数目有一个阈值。
5 One Pixel Attack
这是一种极端的对抗攻击方法,仅改变图像中的一个像素值就可以实现对抗攻击。Su[68] 等人使用了差分进化算法,对每个像素进行迭代地修改生成子图像,并与母图像对比,根据选择标准保留攻击效果最好的子图像,实现对抗攻击。这种对抗攻击不需要知道网络参数或梯度的任何信息。
6 Carlini and Wagner Attacks (C&W)
Carlini 和 Wagner[36] 提出了三种对抗攻击方法,通过限制 l_∞、l_2 和 l_0 范数使得扰动无法被察觉。实验证明 defensive distillation 完全无法防御这三种攻击。该算法生成的对抗扰动可以从 unsecured 的网络迁移到 secured 的网络上,从而实现黑箱攻击。
7 DeepFool
Moosavi-Dezfooli 等人 [72] 通过迭代计算的方法生成最小规范对抗扰动,将位于分类边界内的图像逐步推到边界外,直到出现错误分类。作者证明他们生成的扰动比 FGSM 更小,同时有相似的欺骗率。
8 Universal Adversarial Perturbations
诸如 FGSM [23]、 ILCM [35]、 DeepFool [72] 等方法只能生成单张图像的对抗扰动,而 Universal Adversarial Perturbations[16] 能生成对任何图像实现攻击的扰动,这些扰动同样对人类是几乎不可见的。该论文中使用的方法和 DeepFool 相似,都是用对抗扰动将图像推出分类边界,不过同一个扰动针对的是所有的图像。虽然文中只针对单个网络 ResNet 进行攻击,但已证明这种扰动可以泛化到其它网络上。
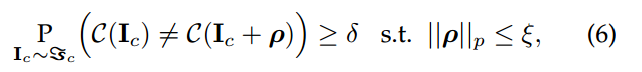
图像从
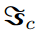 抽样,
抽样,
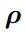 是通用的,满足(6) 的约束,P(.)表示概率,
是通用的,满足(6) 的约束,P(.)表示概率,
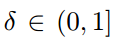 是fooling ratio,
是fooling ratio,
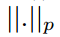 表示lp-norm。
表示lp-norm。
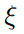 是阈值,它的值越小,就越难对图像施加扰动。
是阈值,它的值越小,就越难对图像施加扰动。
9 UPSET and ANGRI
Sarkar[146] 等人提出了两个黑箱攻击算法,UPSET 和 ANGRI。UPSET 可以为特定的目标类别生成对抗扰动,使得该扰动添加到任何图像时都可以将该图像分类成目标类别。相对于 UPSET 的「图像不可知」image-agnostic 扰动,ANGRI 生成的是「图像特定」image-specific 的扰动。它们都在 MNIST 和 CIFAR 数据集上获得了高欺骗率。
Upset:
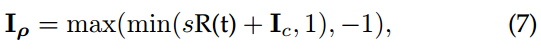
R(.)是残差生成网络,类别t作为输入,produces a perturbation R(t) for fooling. Ic的像素值[-1, 1],s是标量,所有值截断在[-1, 1]。
10 Houdini
Houdini[131] 是一种用于欺骗基于梯度的机器学习算法的方法,通过生成特定于任务损失函数的对抗样本实现对抗攻击,即利用网络的可微损失函数的梯度信息生成对抗扰动。除了图像分类网络,该算法还可以用于欺骗语音识别网络。
11 Adversarial Transformation Networks (ATNs)
Baluja 和 Fischer[42] 训练了多个前向神经网络来生成对抗样本,可用于攻击一个或多个网络。该算法通过最小化一个联合损失函数来生成对抗样本,该损失函数有两个部分,第一部分使对抗样本和原始图像保持相似,第二部分使对抗样本被错误分类。
12 Miscellaneous Attacks
这一部分列举了更多其它的生成对抗样本的方法,详情请参见原文。

表 1:以上列举的各种攻击方法的属性总结:「perturbation norm」表示其限制的 p-范数(p-norm)以使对抗扰动对人类不可见或难以察觉。strength 项(*越多,对抗强度越大)基于回顾过的文献得到的印象。

- Generating Adversarial Examples with Adversarial Networks 采用GAN的方法来生成对抗样本
- 源码干货 | 手把手教你使用TensorFlow生成对抗样本
- 图像对抗样本的生成(FGSM)
- 对抗样本生成的一些经验总结
- FGSM(Fast Gradient Sign Method)生成对抗样本(32)---《深度学习》
- 对抗样本生成算法之C&W算法
- 综述论文:对抗攻击的12种攻击方法和15种防御方法(转)
- 用Caffe生成对抗样本
- Adversarial Sample misleading the Model(生成对抗样本迷惑模型)
- 对抗样本生成算法之FGSM算法
- 生成对抗网络(GAN)相比传统训练方法有什么优势?(一)
- 几张贴纸就让神经网络看不懂道路标志,伯克利为真实环境生成对抗样本
- 手把手教你使用TensorFlow生成对抗样本 | 附源码
- 基于Boost方法的人脸检测(2):样本生成(切割图像、resize图像、灰度化图像、保存图片)
- 要让GAN生成想要的样本,可控生成对抗网络可能会成为你的好帮手
- LeNet生成对抗样本
- 使用TensorFlow生成对抗样本
- 产生和防御对抗样本的新方法 | 分享总结
- 利用SQL存储过程生成程序编号的一种方法
- 页面生成树形查询的后台实现方法