JDK1.8之后HashMap在元素超过8的时候转红黑树结构
2020-06-06 04:29
507 查看
HashMap在初始时依然使用的是数组+链表的结构,
链表的复杂度为O(n),红黑树的复杂度为O(log(n))
从这方面看可以直接使用红黑树来存储,但是并没有这么做,源码中已给出解释:
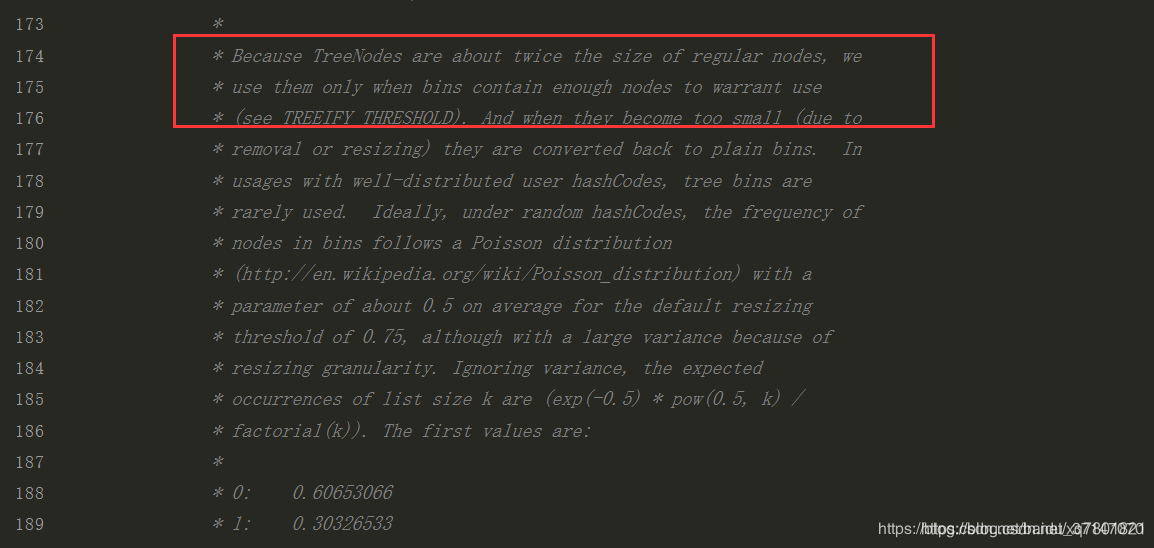
因为树形结构会比常规的节点结构占用多一倍的空间,只用当节点足够多的时候,才会转换为树形结构
另外,为什么会在链表长度等于8的时候才去转换成红黑?
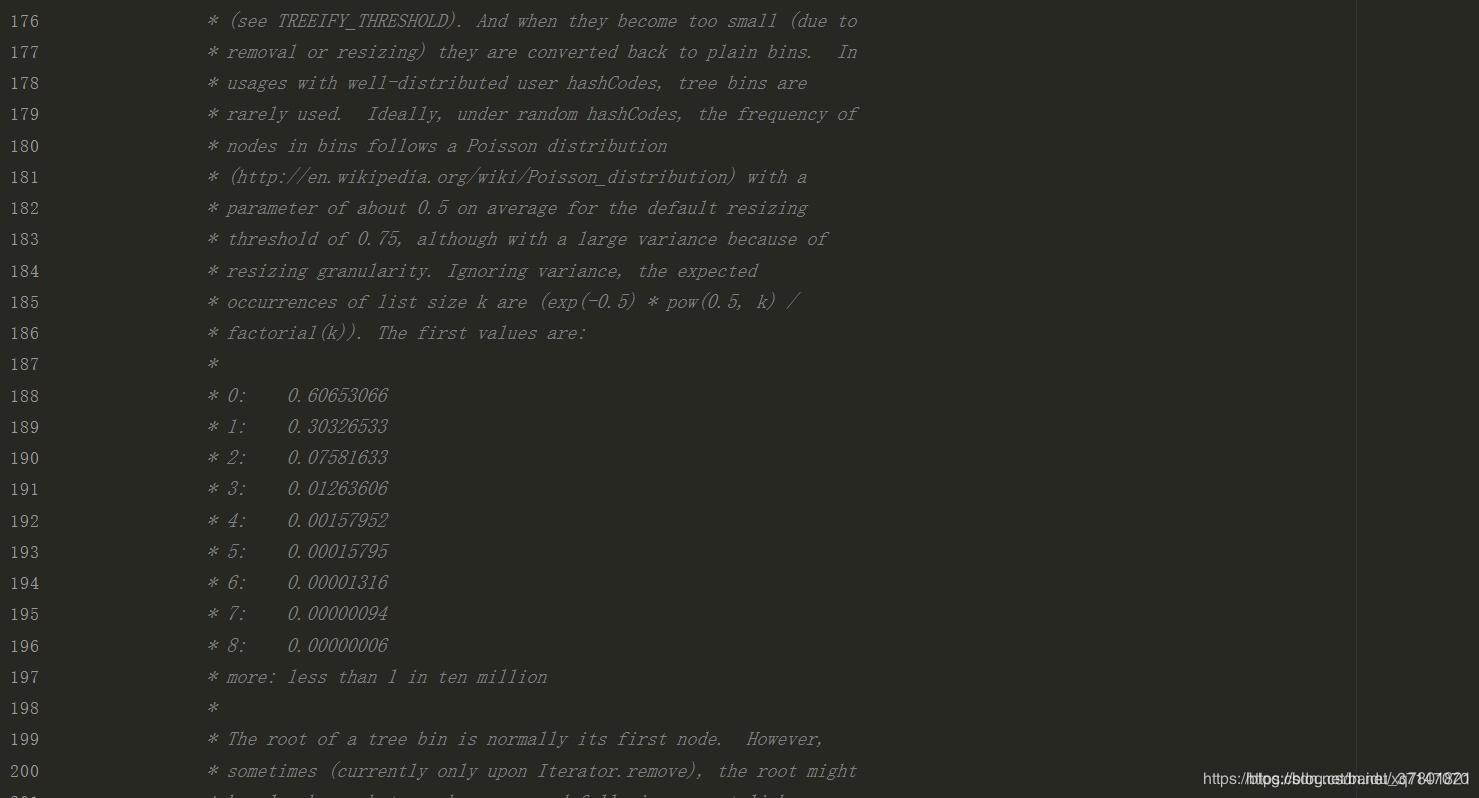
源码上描述:使用分布良好的HashCode,节点的分布类似于泊松分布
泊松分布详解见:https://www.geek-share.com/detail/2742982392.html
链表长度为8的概率已经接近千分之一,此时链表的性能已经很差,所以在这种比较罕见和极端的情况下,
才会把链表转变为红黑树,转变为红黑树也是消耗性能的,是一个权衡的措施。
但是并不是达到了这一个条件就可以转变为红黑树,需要看源代码,有三段Map添加元素的代码 put->putVal->treeifyBin(调用关系):
put()
[code]
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
putVal()
[code] final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
// hash table 对象
Node<K, V>[] tab;
// 下标i对应的Node对象
Node<K, V> p;
// hash table的长度
int n;
// key在hash table中存放的索引下标
int i;
// 获取hash table的长度
if ((tab = table) == null || (n = tab.length) == 0) {
n = (tab = resize()).length;
}
// i = (n - 1) & hash 根据hash值计算key在hash table中的位置
// 那么根据这行代码可以得到个结论:如果key为null(此时对应的hash为0),那么一定是在下标为0的位置
if ((p = tab[i = (n - 1) & hash]) == null) {
// 如果下标i的位置是null(尚未有元素),那么直接放入
tab[i] = newNode(hash, key, value, null);
} else {
Node<K, V> e;
K k;
if (p.hash == hash
&& ((k = p.key) == key || (key != null && key.equals(k)))) {
// 如果p的key和输入的key相等
e = p;
} else if (p instanceof TreeNode) {
// 此处已经是个红黑树了,继续往红黑树里增加新元素
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
} else {
// 如果是个传统的列表对象
for (int binCount = 0; ; ++binCount) {
// 此if的目的是找到位置i上的链表/红黑树的最后一个Node元素
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// TREEIFY_THRESHOLD = 8
if (binCount >= TREEIFY_THRESHOLD - 1) {
// 转换为红黑树(如果hash table的长度不到MIN_TREEIFY_CAPACITY即64,那么只是做扩容处理,并不会转换为红黑树)
treeifyBin(tab, hash);
}// -1 for 1st
break;
}
// 如果链表上已有相同key的Node,那么直接返回此Node
if (e.hash == hash && ((k = e.key) == key || (key != null &&key.equals(k)))) {
break;
}
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) {
e.value = value;
}
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
treeifyBin()
[code]
/**
* 如果hash table的长度大于64,则将指定位置上的所有节点转换为TreeNode;
* 否则只对hash table进行扩容.
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// MIN_TREEIFY_CAPACITY = 64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY){
// 扩容
resize();
}else if ((e = tab[index = (n - 1) & hash]) != null) {
// 转换为红黑树节点
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);//转换为红黑树
}
}
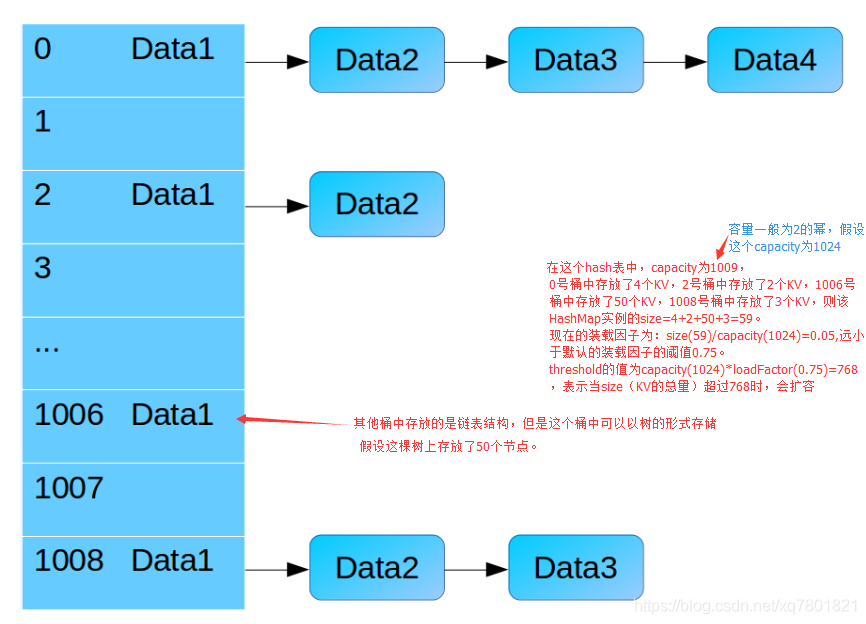
从上面三段代码详解可知
就是当前hash table的长度也就是HashMap的capacity(不是size)不能小于64.小于64就只是做个扩容.
对于capacity和size的解释如下
本文章来源:https://blog.csdn.net/baidu_37147070/article/details/98785367
https://blog.csdn.net/it_qingfengzhuimeng/article/details/100041994

相关文章推荐
- HashMap 在 JDK 1.8 后新增的红黑树结构
- HashMap 在 JDK 1.8 后新增的红黑树结构
- Java 集合深入理解(17):HashMap 在 JDK 1.8 后新增的红黑树结构
- HashMap 在 JDK 1.8 后新增的红黑树结构
- Java 集合深入理解(17):HashMap 在 JDK 1.8 后新增的红黑树结构
- HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)
- HashMap 和 ConcurrentHashMap 源码解析(JDK1.8)(红黑树部分没有解析)
- jdk1.8的hashmap真的是大于8就转换成红黑树,小于6就变成链表吗?????
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
- 浅谈HashMap的底层原理(JDK1.8之前与JDK1.8之后)
- 为什么HashMap链表长度超过8会转成红黑树结构
- 【Java源码】集合类-JDK1.8 哈希表-红黑树-HashMap总结
- jdk1.8对于HashMap碰撞处理的优化-引入红黑树
- jdk8之HashMap resize方法详解(深入讲解为什么1.8中扩容后的元素新位置为原位置+原数组长度)
- JDK1.8后的HashMap底层结构变化
- Jdk1.8中的HashMap实现原理
- source配置文件不生效 原创 2016年03月14日 18:43:55 3558 问题背景: 升级jdk 1.8之后,启动时报版本编译问题,查看$JAVA_HOME,$JRE_HOME
- 深入理解Java HashMap(JDK1.8)
- jdk 1.8 hashmap resize 源码阅读
- HashMap学习笔记,比较JDK1.7/1.8的区别