Redis(开发与运维):54---缓存设计之(缓存穿透问题及优化)
2020-06-04 15:08
441 查看
一、什么是缓存穿透
- 缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层,下图整个过程分为如下3步: 1)缓存层不命中
- 2)存储层不命中,不将空结果写回缓存
- 3)返回空结果
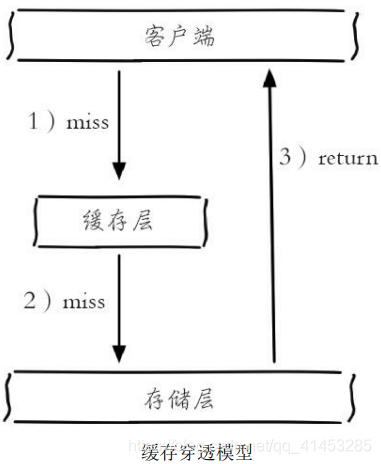
- 缓存穿透带来的问题: ①缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义
- ②缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题
- 第一,自身业务代码或者数据出现问题
- 缓存空对象
二、缓存空对象
- 概念:当第2步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源
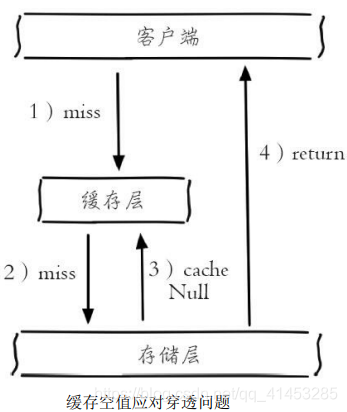
- 缓存空对象会有两个问题: 第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除
- 第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。 例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象
[code]String get(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue))
{
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
}
else {
//缓存非空
return cacheValue;
}
}
三、布隆过滤器
- 如下图所示,在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截
- 例如:一个推荐系统有4亿个用户id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层 中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可 以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户id不 存在,那么就不会访问存储层,在一定程度保护了存储层

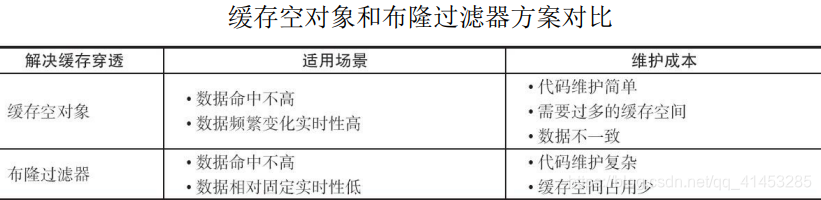
- 这种方法适用于数据命中不高、数据相对固定、实时性低(通常是数据 集较大)的应用场景,代码维护较为复杂,但是缓存空间占用少
- 备注信息: 关于布隆过滤器的介绍可以参阅:https://www.geek-share.com/detail/2801738474.html
- 可以参考:https://en.wikipedia.org/wiki/Bloom_filter可以利用Redis的Bitmaps实现布隆过滤器,GitHub上已经开源了类似的方案,读者可以进行参考:https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
四、两种方案对比
- 前面介绍了缓存穿透问题的两种解决方法(实际上这个问题是一个开放问题,有很多解决方法),下图从适用场景和维护成本两个方面 对两种方案进行分析

相关文章推荐
- Redis(开发与运维):55---缓存设计之(无底洞问题及优化)
- Redis(开发与运维):56---缓存设计之(雪崩问题及优化)
- JAVAWEB开发之Hibernate详解(三)——Hibernate的检索方式、抓取策略以及利用二级缓存进行优化、解决数据库事务并发问题
- Redis缓存相关问题(雪崩、穿透、击穿、并发)
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
- Redis缓存穿透、缓存雪崩、redis并发问题分析
- Redis 缓存穿透、缓存雪崩、热点Key问题分析和解决方案
- Spring Boot 集成Redis学习与缓存穿透问题
- ASP.NET设计中的性能优化问题,.net开发,
- Redis缓存穿透、缓存雪崩、redis并发问题分析
- Redis关于缓存雪崩和缓存穿透等问题
- 【Redis】缓存常见问题解决思路(缓存穿透、缓存雪崩、缓存击穿)
- redis那点事6: 缓存问题篇 (缓存雪崩, 缓存击穿, 缓存穿透等)
- Redis【缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级等问题】
- Redis总结(五)缓存雪崩和缓存穿透等问题
- JAVAWEB开发之Hibernate详解(三)——Hibernate的检索方式、抓取策略以及利用二级缓存进行优化、解决数据库事务并发问题
- Redis(开发与运维):58---开发运维的陷阱之(Linux配置优化:内存分配控制(overcommit、swappiness)、THP、OOM killer、NTP、TCP backlog
- 运维角度浅谈MySQL数据库优化一个成熟的数据库架构并不是一开始设计就具备高可用、高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善。这篇博文主要谈MySQL数据库发展周期中所面临的问题及优化方
- SpringCloud整合Redis高并发下缓存穿透问题
- Redis缓存穿透、缓存雪崩、redis并发问题分析