用Jupyter完成Iris数据集的 Fisher线性分类,并学习数据可视化技术
2020-06-03 06:21
148 查看
目录
一、iris数据集的fisher线性分类判断准确率
二、数据可视化
三、参考文献
一、iris数据集的fisher线性分类判断准确率
代码实现:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
df = pd.read_csv(r'http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header = None)
Iris1=df.values[0:50,0:4]
Iris2=df.values[50:100,0:4]
Iris3=df.values[100:150,0:4]
m1=np.mean(Iris1,axis=0)
m2=np.mean(Iris2,axis=0)
m3=np.mean(Iris3,axis=0)
s1=np.zeros((4,4))
s2=np.zeros((4,4))
s3=np.zeros((4,4))
for i in range(0,30,1):
a=Iris1[i,:]-m1
a=np.array([a])
b=a.T
s1=s1+np.dot(b,a)
for i in range(0,30,1):
c=Iris2[i,:]-m2
c=np.array([c])
d=c.T
s2=s2+np.dot(d,c)
#s2=s2+np.dot((Iris2[i,:]-m2).T,(Iris2[i,:]-m2))
for i in range(0,30,1):
a=Iris3[i,:]-m3
a=np.array([a])
b=a.T
s3=s3+np.dot(b,a)
sw12=s1+s2
sw13=s1+s3
sw23=s2+s3
#投影方向
a=np.array([m1-m2])
sw12=np.array(sw12,dtype='float')
sw13=np.array(sw13,dtype='float')
sw23=np.array(sw23,dtype='float')
#判别函数以及T
#需要先将m1-m2转化成矩阵才能进行求其转置矩阵
a=m1-m2
a=np.array([a])
a=a.T
b=m1-m3
b=np.array([b])
b=b.T
c=m2-m3
c=np.array([c])
c=c.T
w12=(np.dot(np.linalg.inv(sw12),a)).T
w13=(np.dot(np.linalg.inv(sw13),b)).T
w23=(np.dot(np.linalg.inv(sw23),c)).T
#print(m1+m2) #1x4维度 invsw12 4x4维度 m1-m2 4x1维度
T12=-0.5*(np.dot(np.dot((m1+m2),np.linalg.inv(sw12)),a))
T13=-0.5*(np.dot(np.dot((m1+m3),np.linalg.inv(sw13)),b))
T23=-0.5*(np.dot(np.dot((m2+m3),np.linalg.inv(sw23)),c))
kind1=0
kind2=0
kind3=0
newiris1=[]
newiris2=[]
newiris3=[]
for i in range(30,49):
x=Iris1[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
kind1=kind1+1
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
#print(newiris1)
for i in range(30,49):
x=Iris2[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
kind2=kind2+1
elif g13<0 and g23<0 :
newiris3.extend(x)
for i in range(30,50):
x=Iris3[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
kind3=kind3+1
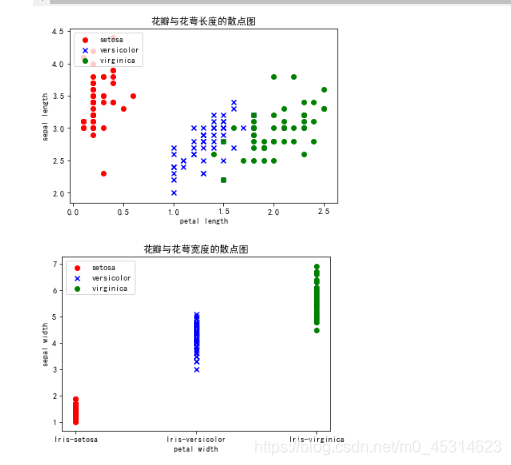
#花瓣与花萼的长度散点图
plt.scatter(df.values[:50, 3], df.values[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(df.values[50:100, 3], df.values[50: 100, 1], color='blue', marker='x', label='versicolor')
plt.scatter(df.values[100:150, 3], df.values[100: 150, 1], color='green', label='virginica')
plt.xlabel('petal length')
plt.ylabel('sepal length')
plt.title("花瓣与花萼长度的散点图")
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False
plt.legend(loc='upper left')
plt.show()
#花瓣与花萼的宽度度散点图
plt.scatter(df.values[:50, 4], df.values[:50, 2], color='red', marker='o', label='setosa')
plt.scatter(df.values[50:100, 4], df.values[50: 100, 2], color='blue', marker='x', label='versicolor')
plt.scatter(df.values[100:150, 4], df.values[100: 150, 2], color='green', label='virginica')
plt.xlabel('petal width')
plt.ylabel('sepal width')
plt.title("花瓣与花萼宽度的散点图")
plt.legend(loc='upper left')
plt.show()
correct=(kind1+kind2+kind3)/60
print("样本类内离散度矩阵S1:",s1,'\n')
print("样本类内离散度矩阵S2:",s2,'\n')
print("样本类内离散度矩阵S3:",s3,'\n')
print('-----------------------------------------------------------------------------------------------')
print("总体类内离散度矩阵Sw12:",sw12,'\n')
print("总体类内离散度矩阵Sw13:",sw13,'\n')
print("总体类内离散度矩阵Sw23:",sw23,'\n')
print('-----------------------------------------------------------------------------------------------')
print('判断出来的综合正确率:',correct*100,'%')
运行结果:

二、数据可视化
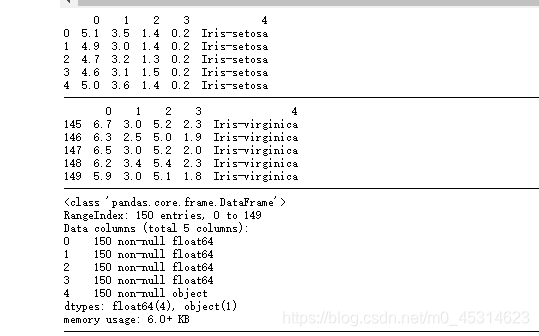
数据显示
import pandas as pd
df_Iris = pd.read_csv(r'http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header = None)
#前五行数据
print(df_Iris.head())
print('-----------------------------------------------------------------------------------------------')
#后五行数据
print(df_Iris.tail())
print('-----------------------------------------------------------------------------------------------')
#查看数据整体信息
df_Iris.info()
print('-----------------------------------------------------------------------------------------------')
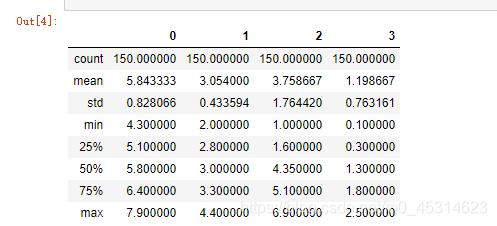
统计性描述:
#描述性统计 df_Iris.describe()
三、参考文献
https://blog.csdn.net/qq_45213986/article/details/105952217

相关文章推荐
- 一文综述数据科学家必备的10大统计技术:线性回归、分类、无监督学习...
- jupyter下的Iris数据集Fisher分类及可视化
- 数据挖掘-K-近邻分类器-Iris数据集分析-使用K-近邻分类器进行分类预测(四)
- 【python数据挖掘课程】十九.鸢尾花数据集可视化、线性回归、决策树花样分析
- 斯坦福李飞飞-深度学习与计算机视觉 数据驱动的图像分类方式:K最近邻与线性分类器
- 大数据学习笔记之八 大数据的技术分类
- [学习笔记]人工智能-神经网络对数据进行分类-可视化
- 斯坦福CS231n计算机视觉学习笔记【二】图像分类数据驱动、K最近邻算法、线性分类
- 用数据可视化直观理解数据--iris数据集为例
- 十大统计技术,包括线性回归、分类、重采样、降维、无监督学习等。
- 从线性回归到无监督学习,数据科学家需要掌握的十大统计技术
- 学习笔记(03):深度学习之图像识别 核心技术与案例实战-分类数据
- ML之DT:利用DT(DTC)实现对iris(鸢尾花)数据集进行分类并可视化DT结构
- 数据挖掘-K-近邻分类器-Iris数据集分析-根据花瓣长宽分类-以散点图显示(二)
- 数据挖掘-oneR算法-Iris数据集分析-使用oneR算法进行分类预测(五)
- 神经网络与深度学习 使用Python实现基于梯度下降算法的神经网络和自制仿MNIST数据集的手写数字分类可视化程序 web版本
- 用数据可视化直观理解数据--iris数据集为例
- 干货丨从线性回归到无监督学习,数据科学家需要掌握的十大统计技术
- 数据挖掘-K-近邻分类器-Iris数据集分析-PCA降维处理后显示分类情况(三)
- (DecisionTreeClassifier)决策树可视化实例-鸢尾花数据分类 学习笔记