Pose2Seg: Detection Free Human Instance Segmentation论文解读
根据人体姿态的特性进行人体实例分割,将多人体姿态估计中的bottom up应用到人体分割领域。
相关信息:
论文链接:Pose2Seg: Detection Free Human Instance Segmentation
数据集:https://github.com/liruilong940607/OCHumanApi
代码:https://github.com/liruilong940607/Pose2Seg
背景
在CV领域关于“人” 的相关研究日益受到重视,如:人脸识别,行人检测追踪,异常行为检测等,这些在智能安防,无人驾驶等领域都有广阔的应用前景。而本文是在实例分割邻域提出对人体的实例分割。
目前大部分实例分割所采用的架构基本是基于proposal的(如Mask RCNN),其大致流程:首先对图片的目标进行检测,然后在生成的检测框的基础上进行实例分割,但是基于proposal 的实例分割架构存在三个根本缺陷:
- 两个物体可能共享同一个或者非常相似的边界框。在这种情况中,mask head 无法区分要从边界框中拾取的对象。主要原因在于:当图像中两个同类别的目标重叠时,大部分目标检测算法所采用的NMS算法,会只保留类别置信度最高的框,将其余的作为重复的无用框删除。
- 架构中没有任何能够阻止两个实例共享像素的东西存在。
- 实例的数量通常受限于网络能够处理的 proposal 的数量(通常为数百个)。而且分割的效果受目标检测识别和检测框定位双重误差影响。
本文作者发现人体姿态的特殊性会比proposal 更好地指导人体实例分割,解决人物重叠时的分割难题。
网络框架

网络框架主要由Affine-Align, Skeleton features和SegModule三部分组成。首先,将有人体姿态标注的图像作为输入,用基础网络(resnet50FPN)提取特征;接着通用Affine-Align operation基于人体动作将ROIs对齐为统一大小(本文中为64*64),同时为图中每个人体生成骨架特征;将上述两者concate之后传给SegModule对图中每个人体进行分割;最后,将Affine-Align operation中的所得仿射变换矩阵H对图中人物反转对齐,得到最终分割结果。
关键技术
1.Affine-Align Operation
Affine-Align的作用与Faster RCNN的ROI Pooling和Mask RCNN的ROI Align类似,都是将ROI对齐成特定大小。但是与它们不同的是,Affine-Align是基于人物的动作对齐,而不是边界框。通过人类动作蕴涵的信息,AffineAlign操作可以把奇怪的人类动作拉直,然后将重叠的人分开。具体流程如下:
(1)通过K-means聚类将数据集中的动作进行聚类,生成pose templates代表数据集的标准姿态。在本论文中K=3,pose templates中包括:半身图,全身前视图,全身后视图。

(2)最优化公式(1)计算出最佳的仿射变换矩阵H,使输入的姿势与templates尽可能接近。因为templates中有多个姿势,所以通过公式(2)找出得分最高的姿势,确定与之最接近的姿势。
为templates中的姿势,P为输入的单个实例姿势,H 为2*3的矩阵,具有5个变量:旋转,比例因子,x轴平移,y轴平移以及是否进行左右翻转
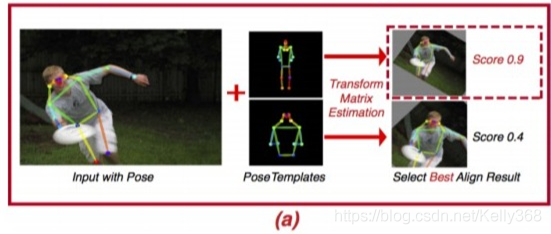
(3)最后将H应用于图像或特征图,并用双线性插值将其转换为固定的大小。

2.Skeleton Features
骨架特征的提取采用的是Realtime multi-person 2d pose estimation using part affinity fields中的方法,通过part confidence maps进行身体关节点检测,然后用PAFs进行关节点进行连接,最后将它们结合起来,得到图像中每个实例的骨架特征。

3.SegModule

SegModule始于一个7*7,步长为2的卷积层,接着是几个标准残差unit,以便为RoI实现足够大的感受野。之后,通过双线性上采样层来扩大分辨率,并且使用另一个残余单元以及1个1*1的卷积层来预测最终结果。其中10个残差单元的这种结构可以实现大约50个像素的感受野。
实验结果
该模型主要与Mask-RCNN进行比较。评估的数据集为:OCHuman(本论文所提出)和COCOPersons(排除人物过小的)。

1.在人物重叠情况上的表现
所有模型均在COCOPersons训练,并在OCHuman上进行测试。Pose2Seg框架比Mask R-CNN的性能高出近50%。


2 在一般情况下的表现
将Pose2Seg与Mask R-CNN和PersonLab进行比较,其中PersonLab也是基于人物姿势估计的实例分割框架。Mask R-CNN和Pose2Seg用COCOPersons训练,并在COCOPersons val上进行测试。PersonLab的实验结果来自他们的论文。

更直观的Mask R-CNN与Pose2seg的比较如下图,明显看出在处理人物重叠的情况上,Pose2Seg比Mask RCNN有更好的效果:

结论
基于人物的实例分割有广阔的应用场景,作者考虑到人的特性,将人体姿态评估应用到实例分割领域,在人物重叠的情况下有显著的表现。

- 车道线检测Towards End-to-End Lane Detection: an Instance Segmentation Approach论文解读
- 论文阅读 Human Pose Regression by Combining Indirect Part Detection and Contextual Information
- [置顶] 实例分割初探,Fully Convolutional Instance-aware Semantic Segmentation论文解读
- 论文解读-<Instance-aware Semantic Segmentation via Multi-task Network Cascades>
- PifPaf: Composite Fields for Human Pose Estimation - CVPR 2019 论文解读- (Based on: G-RMI and PersonLab)
- 论文笔记 《Rich feature hierarchies for accurate object detection and semantic segmentation》
- Towards End-to-End Lane Detection: an Instance Segmentation Approach
- [ICRA 2019]Multi-Task Template Matching for Object Detection, Segmentation and Pose Estimation Using Depth Images
- [深度学习论文笔记][Instance Segmentation] Instance-aware Semantic Segmentation via Multi-task Network Cascad
- 论文实践学习 - Multi-Context Attention for Human Pose Estimation
- 论文解读Focal Loss for Dense Object Detection
- 【论文】Detection and segmentation of moving objects in complex scenes
- 【论文阅读】Fused Text Segmentation Network for Multi-oriented Scene Text Detection
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
- Region-based Convolutional Networks for Accurate Object Detection and Segmentation----R-CNN论文笔记
- Fast single shot detection and pose estimation 论文笔记
- Rich feature hierarchies for accurate object detection and semantic segmentation论文笔记
- 论文阅读:Instance-aware Semantic Segmentation via Multi-task Network Cascades
- 论文实践学习 - Stacked Hourglass Networks for Human Pose Estimation
- Contour Detection and Hierarchical Image Segmentation 伯克利的一篇图像分割论文理解与学习