续集:【多线程实现】python使用tkinter库实现自定义的词云图和top10词频统计
2020-06-01 04:36
344 查看
上一篇已经介绍了整体实现过程,这一篇主要是介绍多线程的知识点。
https://blog.csdn.net/dhjabc_1/article/details/105387870
Python提供了 _thread 和 threading 两个线程模块,_thread 是低级模块,threading 对 _thread 进行了封装,提高了 _thread 原有功能的易用性以及扩展了新功能,通常我们只需要使用 threading 模块。
[code]import threading
def run(n):
print('运行线程',n)
for i in range(5): # 创建5个线程
t = threading.Thread(target=run, args=(i,)) # 线程运行的函数和参数
t.setDaemon(True) # 设置为守护线程(在主线程线程结束后自动退出,默认为False即主线程线程结束后子线程仍在执行)
t.start() # 启动线程
相关参数如下:
start 线程准备就绪,等待CPU调度
setName 为线程设置名称
getName 获取线程名称
setDaemon 设置为后台线程或前台线程(默认)
如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止
join 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
run 线程被cpu调度后自动执行线程对象的run方法
这种方式,无法实现获取函数的返回值,如果需要获取返回值,那么就需要使用继承的方式实现,本案例通过继承的方式实现。
[code]import threading class base_run(threading.Thread): def __init__(self, arg1,arg2,arg3): super(base_run, self).__init__() self.arg1 = arg1 #原始文件 self.arg2 = arg2 #图像文件 self.arg3 = arg3 #输出词云文件 self.result = [] self.flag = True def run(self): self.result,self.flag = base(self.arg1,self.arg2,self.arg3) print(self.result) print(self.flag) def get_result(self): return self.result def get_flag(self): return self.flag
实现整体的词频统计和词云图生成的核心代码:
[code]def base(source_file,source_image,result_image):
try:
fn = open(source_file, encoding="utf-8") # 打开文件
text = fn.read() # 读出整个文件
# print(text)
fn.close() # 关闭文件
except:
try:
fn = open(source_file, encoding="gbk") # 打开文件
text = fn.read() # 读出整个文件
# print(text)
fn.close() # 关闭文件
except:
print('无法打开文件')
# 文本预处理
# 定义正则表达式匹配模式,将符合模式的字符去除
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"|、|,|。| |”|“|;')
text = re.sub(pattern, '', text)
# 进行词频统计
text_list = jieba.cut(text, cut_all=False)
# 定义去除词典
stop_words = [u'的',u'多',u'把', u',', u'和', u'是', u'随着', u'对于', u'对', u'等', u'能', u'都', u'。',
u' ', u'、', u'中', u'在', u'了', u'通常', u'如果', u'我们', u'需要'] # 自定义去除词库
new_text_list = []
for word in text_list: # 循环读出每个分词
if word not in stop_words: # 如果不在去除词库中
new_text_list.append(word) # 分词追加到列表
# print(word)
# 按照去重词库更新词频统计
text_list = collections.Counter(new_text_list) # 对分词做词频统计
word_counts_top10 = text_list.most_common(10) # 获取前10最高频的词
mask = np.array(Image.open(source_image)) # 定义词频背景
# mask = ImageColorGenerator(back_img)
w_cloud = WordCloud(
font_path="c:\windows\Fonts\simhei.ttf",
background_color='white',
width=1000,
height=600,
mask=mask).generate_from_frequencies(text_list)
# 输出成图片:
w_cloud.to_file(result_image)
return word_counts_top10,False
最终该多线程的核心代码为:(保存的文件名为:base_final.py)
[code]import jieba
import collections
import re # 正则表达式库
from wordcloud import ImageColorGenerator
from wordcloud import WordCloud
from PIL import Image # 图像处理库
import numpy as np # numpy数据处理库
import threading
class base_run(threading.Thread):
def __init__(self, arg1,arg2,arg3):
super(base_run, self).__init__()
self.arg1 = arg1 #原始文件
self.arg2 = arg2 #图像文件
self.arg3 = arg3 #输出词云文件
self.result = []
self.flag = True
def run(self):
self.result,self.flag = base(self.arg1,self.arg2,self.arg3)
print(self.result)
print(self.flag)
def get_result(self):
return self.result
def get_flag(self):
return self.flag
def base(source_file,source_image,result_image):
try:
fn = open(source_file, encoding="utf-8") # 打开文件
text = fn.read() # 读出整个文件
# print(text)
fn.close() # 关闭文件
except:
try:
fn = open(source_file, encoding="gbk") # 打开文件
text = fn.read() # 读出整个文件
# print(text)
fn.close() # 关闭文件
except:
print('无法打开文件')
# 文本预处理
# 定义正则表达式匹配模式,将符合模式的字符去除
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"|、|,|。| |”|“|;')
text = re.sub(pattern, '', text)
# 进行词频统计
text_list = jieba.cut(text, cut_all=False)
# 定义去除词典
stop_words = [u'的',u'多',u'把', u',', u'和', u'是', u'随着', u'对于', u'对', u'等', u'能', u'都', u'。',
u' ', u'、', u'中', u'在', u'了', u'通常', u'如果', u'我们', u'需要'] # 自定义去除词库
new_text_list = []
for word in text_list: # 循环读出每个分词
if word not in stop_words: # 如果不在去除词库中
new_text_list.append(word) # 分词追加到列表
# print(word)
# 按照去重词库更新词频统计
text_list = collections.Counter(new_text_list) # 对分词做词频统计
word_counts_top10 = text_list.most_common(10) # 获取前10最高频的词
mask = np.array(Image.open(source_image)) # 定义词频背景
# mask = ImageColorGenerator(back_img)
w_cloud = WordCloud(
font_path="c:\windows\Fonts\simhei.ttf",
background_color='white',
width=1000,
height=600,
mask=mask).generate_from_frequencies(text_list)
# 输出成图片:
w_cloud.to_file(result_image)
return word_counts_top10,False
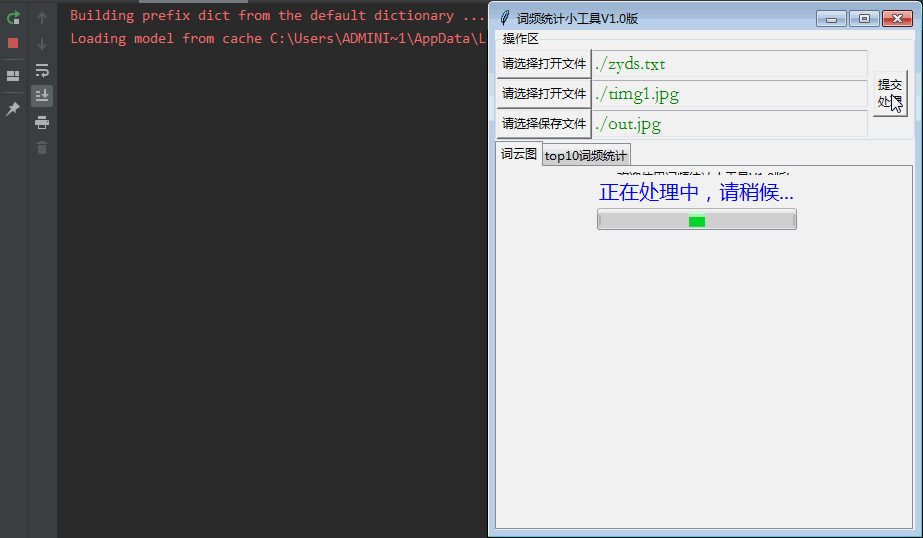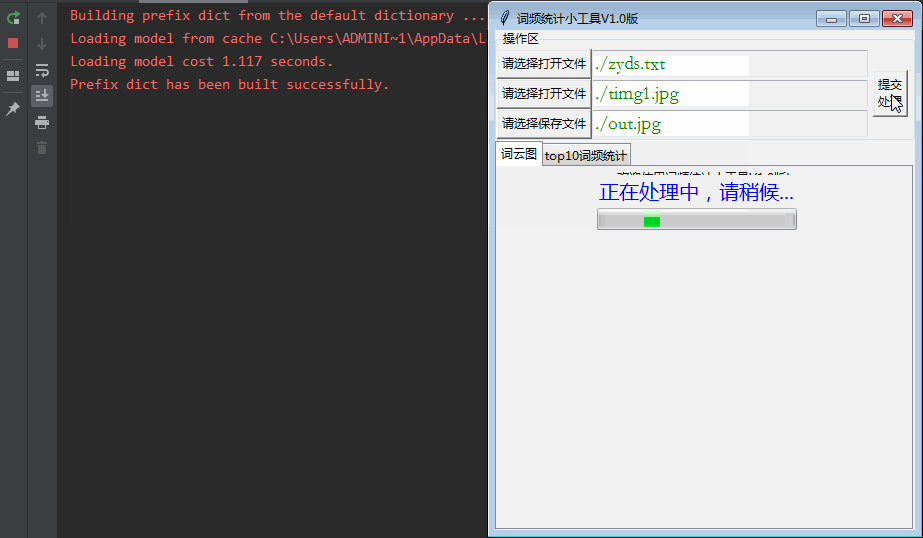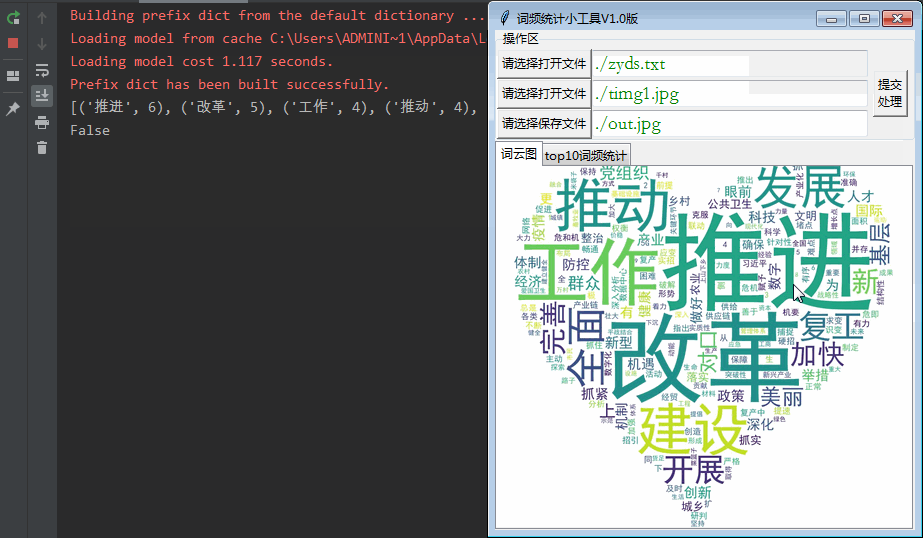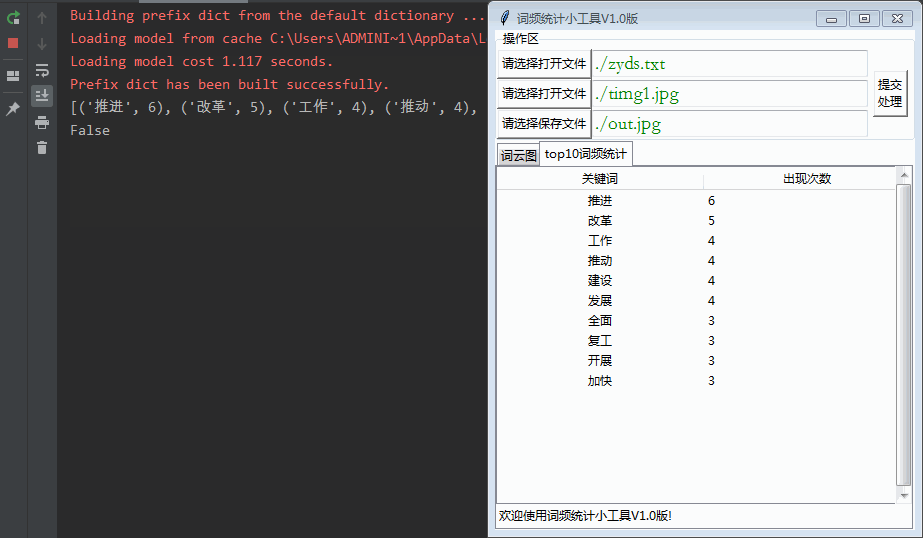
最终输出效果如下:

相关文章推荐
- Python字典使用--词频统计的GUI实现
- 使用Python+NLTK实现英文单词词频统计
- 使用Python+NLTK实现英文单词词频统计
- 使用Actor模型对词频统计程序进行多线程优化
- python3使用tkinter实现ui界面简单实例
- python里使用string.Template实现自定义转义字符和正则表达式替换
- 使用Python之paramiko模块和threading实现多线程登录多台Linux服务器
- Python:使用threading模块实现多线程(转)
- Hadoop 2.2.0词频统计(实现自定义的Partitioner和Combiner)
- python实现爬虫统计学校BBS男女比例(二)多线程爬虫
- 使用Python实现子区域数据分类统计
- 使用Python实现子区域数据分类统计
- [置顶] Python生成词云图,TIIDF方法文本挖掘: 词频统计,词云图
- Python多线程 - 使用threading模块实现多线程的 3 种方式
- pyqt5 使用 QTimer, QThread, pyqtSignal 实现自动执行,多线程,自定义信号触发。
- 词频统计的C++实现(使用stl--map)
- python3.3使用tkinter实现猜数字游戏代码
- 使用Python SocketServer快速实现多线程网络服务器
- Python 3.4.3 使用threading模块进行多线程编码实现
- Python使用Hadoop进行词频统计