一网打尽!关于mysql索引的基础与高级知识都在这里了
本文取材于《高性能MySQL第三版》的第5章,由于索引使用了较多的比较复杂的数据结构,限于篇幅,本文仅对这些数据结构进行简单介绍,如果不清楚的可以自行查资料学习
目录
当我们使用
select xx from table where id=x
的时候,不知道你有没有想过,MySql是如何进行查找操作的,今天我就关于这句话,来说说MySql的索引策略,
索引类型
b-Tree索引
-
介绍
大多数MySql引擎都支持b-Tree索引,b-Tree是一种类似二叉平衡树(BST)的数据结构,如图
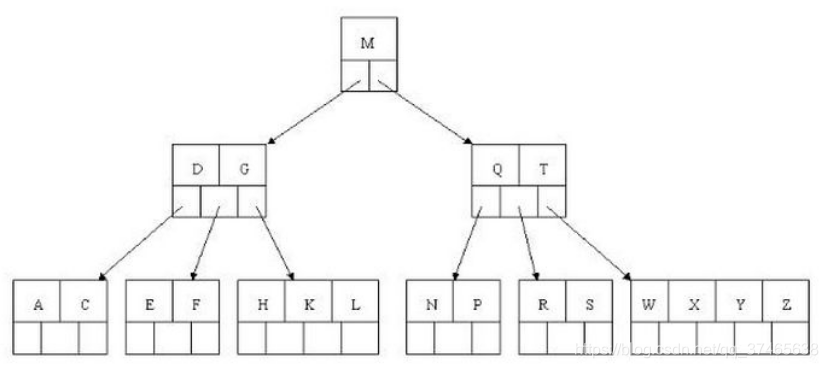
不过,他是一种多叉树,查找方式和BST并无二致,区别在于他的所有叶子节点在同一高度,非常整齐。从根到叶节点进行搜索
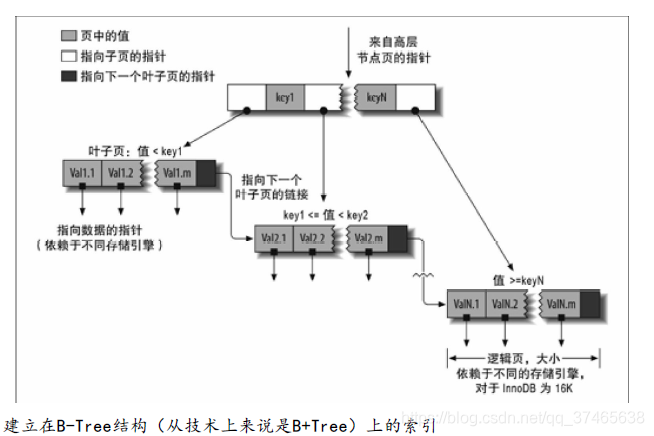
但是msyql中使用b+树,b+树和b树的关键区别是b树的路径记录了实际数据,但是b+树的路径没有关键值,只有索引,所有的数据由叶子节点指向,这样使得b+树每一层可以记录更多的索引,减小了层数,同时叶子节点相互连接,形成了链表,如图
接下来我们来实践下
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) );
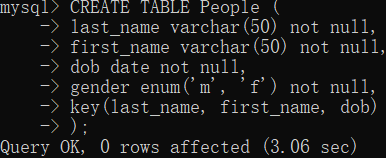
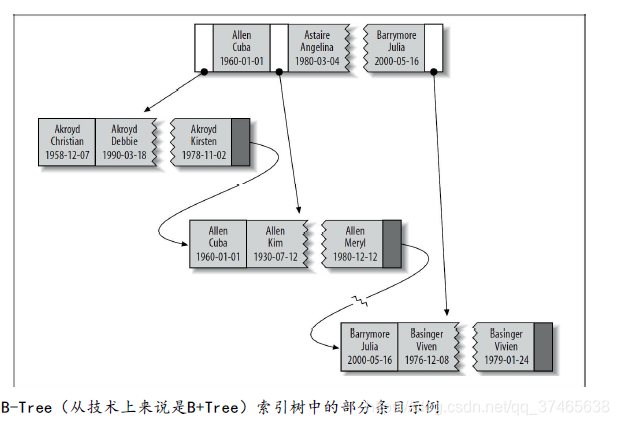
其中key(last_name, first_name, dob)表示将last_name, first_name, dob三列作为索引,根据最左优先,先排last_name,最后排dob,如下
在英语中,last_name第一个读,first_name第二个读,所以A字母开头的名先排,而Allen Cuba和Allen Kim的last_name一样,就比first_name,Cuba先排
-
限制
相信你发现了,虽然b树和b+树可以保证查询速度,但是他们的索引限定了只能从最左边开始查找,上面的例子也表明,只能先last_name,再first_name,最后dob,如果想查dob则不得不对前两个还要进行查找,无法跳过
哈希索引
-
介绍
哈希是大家的老朋友了,在java中的hashmap相信大家非常熟悉,简单介绍下
hash维护了一个槽slot,一般是一个数组,放置每个要保存的数据的哈希码(hashcode),hashcode的生成方式可自由选择,关键在于不同数据不能重复,一种常见的是ascii码累加形式
比如
"A"的hashcode就是97
“AB"的hashcode就是97+98*27
依次类推
我们来实践一下
CREATE TABLE testhash ( fname VARCHAR(50) NOT NULL, lname VARCHAR(50) NOT NULL, KEY USING HASH(fname) ) ENGINE=MEMORY;
进行插入
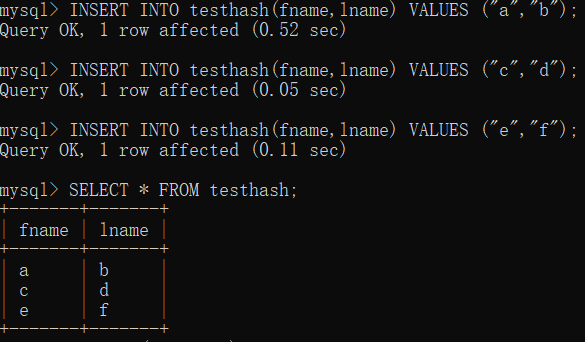
假设下面的索引hashcode为下
f(‘a’)= 2323
f(‘c’)= 8784
f(‘e’)= 7437则哈希索引的数据结构如下
槽(Slot) 关键字(Key) 值(Value) 2323 a 指向第一行的指针 7437 e 指向第三行的指针 8784 c 指向第二行的指针 因为这是按hashcode从大到小排序,这里如果出现两个hashcode一样怎么办?
这是著名的解决哈希冲突的问题,有分离链接法,开放定址法,双散列法等方法可以自己探索
所以对于下面这行
SELECT lname FROM testhash WHERE fname='a';
Mysql将先计算a的hashcode为2323,并使用这个值在记录中找到指向第一行的指针,取出第一行的值,就算完成了一次查找
-
限制
hash结构查找快,在于他的散列,但是成也散列,败也散列,他无法对于数据排序,如果一个数据库只有哈希索引,那么他将无法进行order by操作
-
不支持比较查询,>,<,IN()都不行,也不支持范围查询
-
如果hashcode算法没选好,将会产生大量的冲突,不得不花费很多精力解决
空间数据索引 (R-Tree)
-
介绍
顾名思义,这是以空间换时间的操作,通过全文索引的方式,可以从全部维度来查找数据,搜索引擎就是这么干的
在MySql中,只有MyISAM引擎支持全文索引
MyISAM的全文索引作用对象是一个“全文集合”,这可能是某个数据表的一列,也可能是多个列。具体的,对数据表的某一条记录,MySQL会将需要索引的列全部拼接成一个字符串,然后进行索引。
MyISAM的全文索引是一类特殊的B-Tree索引,共有两层。第一层是所有关键字,然后对于每一个关键字的第二层,包含的是一组相关的“文档指针” -
限制
这种树的限制也是必然的,对于比较有规律的数据,用全文索引就太浪费了,比较适合搜索引擎使用
如何构造高性能索引
应该考虑的
实际上并没有什么万能之策,世界上的数据千奇百怪,每种数据的最好索引都是单独为其设置的,所以,在这里介绍构建高性能索的方法
逐步优化前缀索引
在b-Tree索引中,选择不同的顺序对搜索情况影响很大,除了顺序之外,对于单个的列作为前缀索引,到底设置多少长度也是一个需要考虑的问题,如图,左边是城市出现的次数,右边是城市
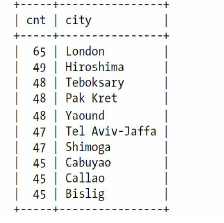
查找特定城市,到底要匹配多少个前缀字母呢?如果我们只匹配三个
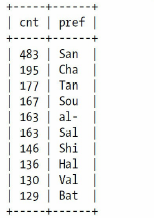
发现数量前3个字母相同的远远超过城市,毕竟London是最多的,也才出现了65次,但是前缀为San的出现了483次??显然,是因为前缀为San的城市太多了,经过比对,前7个字母作为前缀比较合适
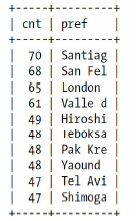
当然了,也有例外情况,但是这样足以一下子确定大致区间,具体哪座城市,再在区间中匹配即可
此外还可以后缀(比如电子邮件),中缀(比如年月日中按星座查询)查询等,也可以将城市的ascii码来匹配,思路一样
覆盖索引
简单来说,就是索引包含了我们要查询的值,这样我们就没必要去查表了,直接查索引即可
CREATE TABLE t ( id INT, name INT, age INT, sroce INT, address VARCHAR(20) )
就拿这个表来说,如果我们判定我们只通过id和name来查人,那么我们只需要使用b-tree作为数据结构,将id,name放在叶子节点处即可
这也叫索引覆盖查询,这种方法没有任何缺点!!!
但是,显然有适用范围限制,对数据的规律性要求较高,尤其是对于hash索引这种不以b-tree为基础数据结构的,无法使用。不过可以对数据进行优化,使其满足使用覆盖索引的条件即可
压缩索引
这种方式准确来说叫“前缀压缩索引”
就是在前缀索引的基础上对前缀进行压缩处理,比如对于city的查找我们认为7个字母的前缀比较合适,但是这7个字母的排列是由规律的,比如什么San,Lon就出现得多,kkk就基本不会出现,假设就排了256中可能,那么理论上我们使用log2(256)=8位bit就能表示完所有前缀,也就是只需要一个字节!
或许你已经想到了,具体压缩方法可以参考哈夫曼编码
但是这样会导致某些操作变慢,所以这是以时间换空间的操作,对于数据量过大的数据库,可以考虑使用,压缩算法好的话,甚至可以压缩90%,速度也不会慢太多
应该小心的
谨慎选择:多列单独的索引
顾名思义,在多个列上分别建立索引
代码执行如下
CREATE TABLE t ( id INT, name INT, age INT, KEY(c1), KEY(c2), KEY(c3) );
这样非常灵活,既可以按id查询,也可以按姓名查询,但是,这样将会导致很严重的性能问题
我们知道,一山不容二虎,总指挥只能有一个
-
如果服务器对多列单独的索引进行AND操作,那么为什么不直接构建一个合并的多列索引?
-
如果服务器对多列单独的索引进行OR操作,那么将会有大量CPU资源消耗在重复的搜索,还有缓存和排序
-
优化器不会把上面的成本计算在内,因为他们关心的是读取的成本,而不是查询的成本
聚簇索引
什么是聚簇索引?一图胜千言
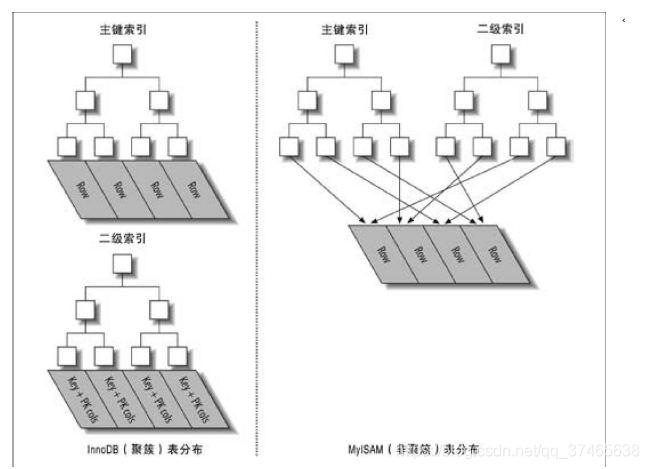
简单来说,聚簇索引中的叶子节点包含了行的全部数据,主键索引有一份,二级索引也有一份
这样子,有以下优点
- 相关数据可以集中在一起,物理上也放一起,可以快速存取
- 配合B-Tree使用,查询速度更快
当然,这显然是利用空间换时间的方法,缺点也很明显
- 比较适用于I/O密集型应用,假如数据已经读取到内存了,聚簇索引不仅速度不快,还加载了太多的数据
- 插入速度依赖于顺序,最好只通过主键插入数据到表
- 数据存放僵化,不方便迁移和更新
这样可能还有点抽象,我们来看一个表
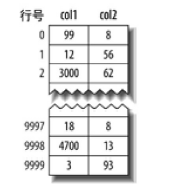
对于col1,我们按列值从小到大排序,也就是说 假设9999行的3最小,0行的99居中,9998行的4700最大
那么在MyISAM(非聚簇索引)的b-tree索引中,他是这样的
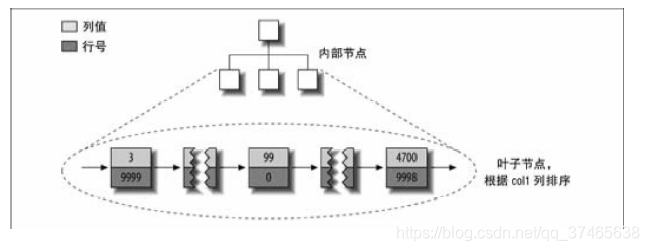
而在InnoDB(聚簇索引)的b-tree中,他是这样的
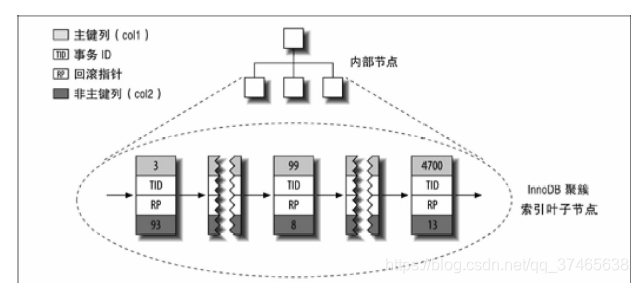
看到了吗,这里多了TID和RP队列和所有的剩余列(这里的剩余列指col2),少了行号。
非聚簇索引告诉你你想要的值col,再给你个行号,其他东西你顺着这个行号找吧
聚簇索引则把所有的东西都给你了,放在叶节点中
所以看你这个数据是否是I/O密集型,选择聚簇还是非聚簇
冗余,重复索引和未使用的索引
两种索引有些区别
冗余索引:创建了(A,B)为索引,再创建A为索引,此时A就是冗余索引
重复索引:完全相同的索引
所以,当你要添加索引的时候,必须先确保既不是重复索引,也不是冗余索引,而且
应该尽量扩展原有的索引,而不是创建新的索引,可参考上面的“多列单独的索引”
未使用的索引:有些索引是无法用到的,完全是累赘,可以通过一些工具删除
索引和锁
为了避免脏读幻读不可重复读,参考这里:
每次读的时候数据库都会锁定相应的地方,优秀的锁一定是读什么锁什么,而差的往往会只读一行,却把整个表都锁住,所以,在保证正确的前提下,尽量减少锁的粒度和数量
InnoDB只有在访问行的时候才会对其加锁,而索引能够减少InnoDB访问的行数,从而减少锁的数量。但这只有当InnoDB在存储引擎层能够过滤掉所有不需要的行时才有效。如果索引无法过滤掉无效的行,那么在InnoDB检索到数据并返回给服务器层以后,MySQL服务器才能应用WHERE子句(19)。这时已经无法避免锁定行了:InnoDB已经锁住了这些行,到适当的时候才释放。
InnoDB在二级索引上使用共享(读)锁,但访问主键索引需要排他(写)锁。这消除了使用覆盖索引的可能性,并且使得SELECT FOR UPDATE比LOCK IN SHARE MODE或非锁定查询要慢很多。
总结
除了上面这些,同一章中还有维护索引和表,索引案例学习等大量内容,总的来说,索引是一个非常复杂的话题
为了保证其速度,存储空间,正确性,对表的影响都是可以接受的,设计索引的人员使用了很多种方法,设计了很多的数据结构。上面的这些方法或许终将被抛弃,但是下面的这些原则是不会变的
-
单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引用以提升效率。
-
按顺序访问范围数据是很快的,这有两个原因。第一,顺序I/O不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUP BY查询也无须再做排序和将行按组进行聚合计算了。
-
索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访问是很慢的。
写在最后,作者是一个喜欢读书的人,尤其是社科和历史,觉得好的话可以关注一下【小松与蘑菇】公众号,编程是手段,生活幸福是目的,大家加油
 原创文章 126获赞 414访问量 12万+
关注
私信
原创文章 126获赞 414访问量 12万+
关注
私信

- mysql索引和性能优化(mysql基础知识3)
- MySQL高级知识与优化(四):优化索引、优化SQL语句
- 关于mysql基础知识的介绍
- MySql学习day04 索引 index 视图 view MySql扩充 MySql编程的基础知识 流程控制语句 系统函数
- 关于mysql基础知识的介绍
- 关于索引的基础知识
- MySQL高级知识-查询与索引优化分析
- MySQL中索引的基础知识
- MySQL高级知识-查询与索引优化分析
- 关于mysql的基础知识
- 来了解一下Mysql索引的相关知识:基础概念、性能影响、索引类型、创建原则、注意事项
- mysql 索引,死锁 配置 等 基础理论知识整理
- 索引面试题分析(MySQL高级知识七)
- Mysql基础知识:索引
- 再学Mysql高级(学习笔记) 一 概念.索引
- SQL Server 索引基础知识(2)----聚集索引,非聚集索引
- 关于oracle和mysql 主键自增的小知识
- 关于列表(ListCtrl)控件的界面基础知识
- 关于C#基础知识回顾--反射(三)
- MySQL基础教程28-高级查询-数据源