java集合详解
1.java集合是什么?
java集合实际上是一种经常被运用到的java类库,其中提供了已经实现的的数据结构,省去了程序员再次编写数据结构的事情.在Leetcode中经常会被用到,有很重要的作用.

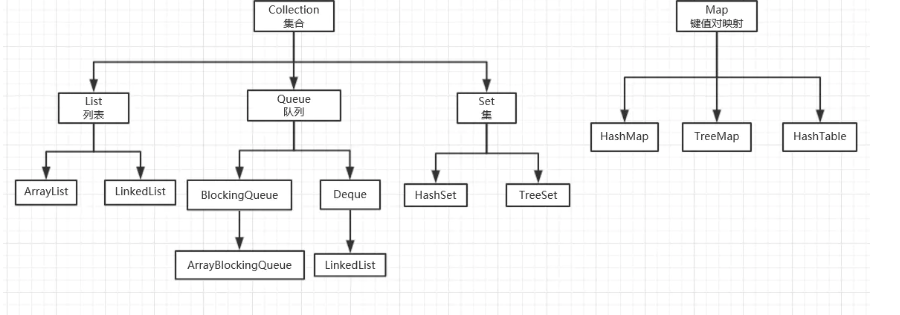
集合体系
我们发现,无论是Set和List都是继承于
Collection接口,实现
Collection之中的方法,而他们又衍生出了
HashSet,
LinkedList等等我们经常使用的数据结构.
但是真相并不是如此的简单.
对于
Collection接口的实现,其实是由
AbstractCollection类完成的.
此类提供了
Collection接口的骨干实现,从而最大限度地减少了实现此接口所需的工作。
Collection中需要实现的的方法:
boolean add(E o) 确保此 collection 包含指定的元素(可选操作)。 boolean addAll(Collection<? extends E> c) 将指定 collection 中的所有元素都添加到此 collection 中(可选操作)。 void clear() 移除此 collection 中的所有元素(可选操作)。 boolean contains(Object o) 如果此 collection 包含指定的元素,则返回 true。 boolean containsAll(Collection<?> c) 如果此 collection 包含指定 collection 中的所有元素,则返回 true。 boolean equals(Object o) 比较此 collection 与指定对象是否相等。 int hashCode() 返回此 collection 的哈希码值。 boolean isEmpty() 如果此 collection 不包含元素,则返回 true。 Iterator<E> iterator() 返回在此 collection 的元素上进行迭代的迭代器。 boolean remove(Object o) 从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。 boolean removeAll(Collection<?> c) 移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。 boolean retainAll(Collection<?> c) 仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。 int size() 返回此 collection 中的元素数。 Object[] toArray() 返回包含此 collection 中所有元素的数组。 <T> T[] toArray(T[] a) 返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同。
AbstractCollection类实现的方法:
boolean add(E o) 确保此 collection 包含指定的元素(可选操作)。 boolean addAll(Collection<? extends E> c) 将指定 collection 中的所有元素添加到此 collection 中(可选操作)。 void clear() 从此 collection 中移除所有元素(可选操作)。 boolean contains(Object o) 如果此 collection 包含指定的元素,则返回 true。 boolean containsAll(Collection<?> c) 如果此 collection 包含指定 collection 中的所有元素,则返回 true。 boolean isEmpty() 如果此 collection 不包含元素,则返回 true。 abstract Iterator<E> iterator() 返回在此 collection 中的元素上进行迭代的迭代器。 boolean remove(Object o) 从此 collection 中移除指定元素的单个实例(如果存在)(可选操作)。 boolean removeAll(Collection<?> c) 从此 collection 中移除包含在指定 collection 中的所有元素(可选操作)。 boolean retainAll(Collection<?> c) 仅在此 collection 中保留指定 collection 中所包含的元素(可选操作)。 abstract int size() 返回此 collection 中的元素数。 Object[] toArray() 返回包含此 collection 中所有元素的数组。 <T> T[] toArray(T[] a) 返回包含此 collection 中所有元素的数组;返回数组的运行时类型是指定数组的类型。 String toString() 返
出了一个
hashcode方法,
AbstractCollection类实现了几乎所有的功能.
而
AbstractCollection类又有三个不同的子类
AbstractList,
AbstractQueue,
AbstractSet.我们从名字就可以知道,这就是三种不同的数据结构.于是这样基本就可以分析出来.
集合类的构建框架如下.
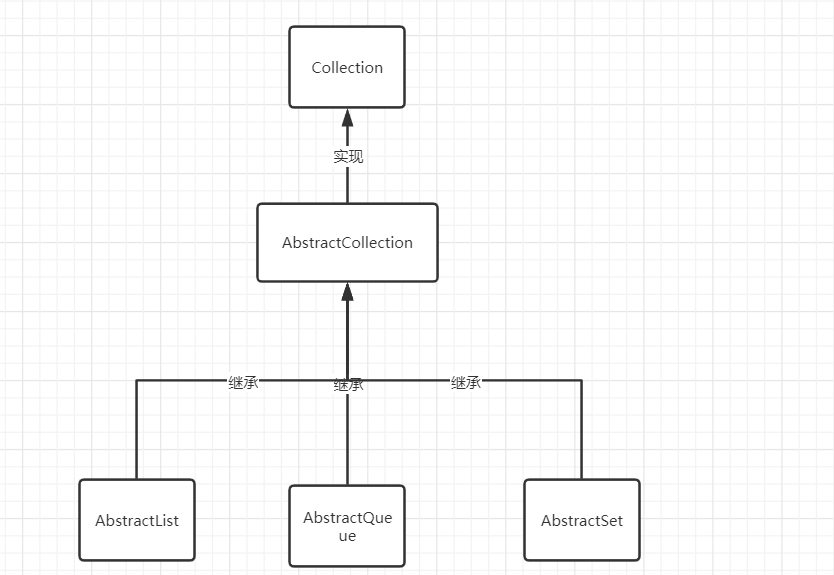
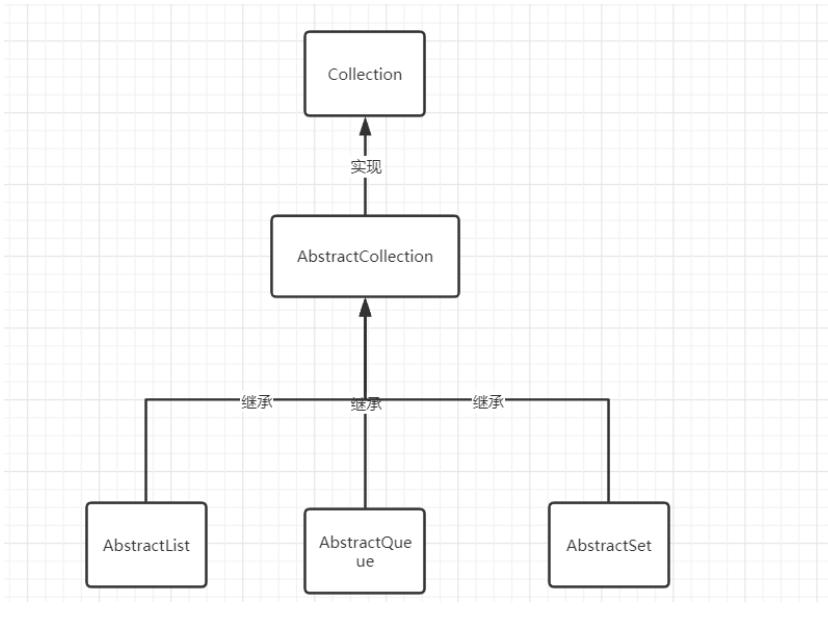
所有的集合都是依靠这种方式构建的,用一个抽象类实现接口,然后再用集合类去实现这些抽象类,来完成构建集合的目的.

这是完整的构建图.
这其实是为了大家有一个思想,就是在Collection实现的方法,在继承实现他的各个集合中也都会实现.
如下是本文的目录:
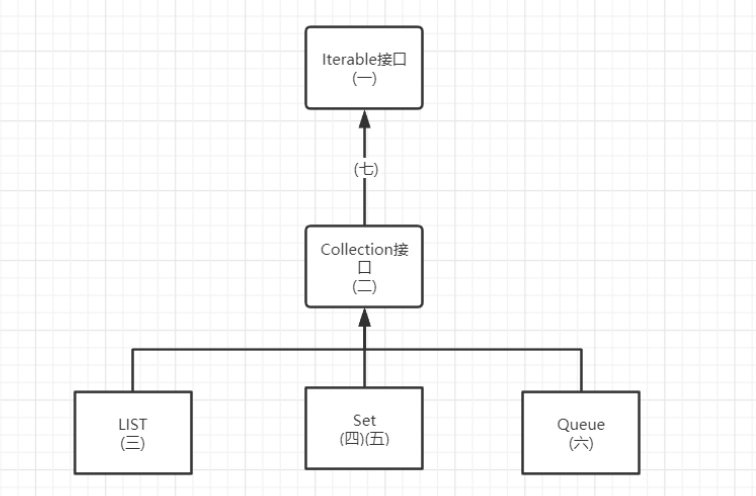
(一) Iterator接口--迭代器
{
boolean hasNext() 如果仍有元素可以迭代,则返回 true。
E next() 返回迭代的下一个元素。
void remove() 删除
default void forEach 实现了迭代器接口的类才可以使用forEach
}
这几个方法有着很重要的意义:
所有实现
Collection
接口(也就是大部分集合)都可以使用forEach功能.通过反复调用
next()
方法可以访问集合内的每一个元素.java迭代器查找的唯一操作就是依靠调用next,而在执行查找任务的同时,迭代器的位置也在改变.
Iterator迭代器remove方法会删除上次调用next方法返回的元素.这也意味之remove方法和next有着很强的依赖性.如果在调用remove之前没有调用next是不合法的.
这个接口衍生出了,java集合的迭代器.
java集合的迭代器使用
下面是迭代器的一个小栗子:
class test {
public static void run() {
List<Integer> list = new LinkedList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
Iterator<Integer> iterator = list.iterator();//依靠这个方法生成一个java集合迭代器<--在Colletion接口中的方法,被所有集合实现.
// iterator.remove();报错java.lang.IllegalStateException
iterator.next();
iterator.remove();//不报错,删掉了1
System.out.println(list);//AbstractCollection类中实现的toString让list可以直接被打印出来
while (iterator.hasNext()) {//迭代器,hasNext()集合是否为空
Integer a = iterator.next();//可以用next访问每一个元素
System.out.println(a);//2,3 ,3
}
for (int a : list) {//也可以使用foreach
System.out.println(a);//2,3,3
}
}
public static void main(String[] args) {
run();
}
}
当然你也会有点好奇,为什么
remove方法前面必须跟着一个next方法.其实这个只能这么解释.
迭代器的next方法的运行方式并不是类似于数组的运行方式.
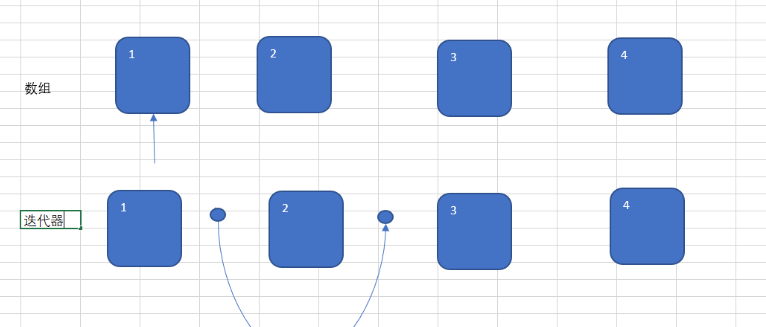
当然,这张图主要是让你理解一下.
数组的指针指向要操作的元素上面,而迭代器却是将要操作的元素放在运动轨迹中间.
本质来讲,迭代器的指针并不是指在元素上,而是指在元素和元素中间.
假设现在调用remove().被删除的就是2号元素.(被迭代器那个圆弧笼盖在其中的那个元素).如果再次调用,就会报错,因为圆弧之中的2号元素已经消失,那里是空的,无法删除.
(二) Collection接口
这个对象是一个被
LIst,
Set,
Queue的超类, 这个接口中的方法,构成了集合中主要的方法和内容.剩下的集合往往都是对这个接口的扩充.
方法如下:
boolean add(E o) 确保此 collection 包含指定的元素(可选操作)。 boolean addAll(Collection<? extends E> c) 将指定 collection 中的所有元素添加到此 collection 中(可选操作)。 void clear() 从此 collection 中移除所有元素(可选操作)。 boolean contains(Object o) 如果此 collection 包含指定的元素,则返回 true。 boolean containsAll(Collection<?> c) 如果此 collection 包含指定 collection 中的所有元素,则返回 true。 boolean isEmpty() 如果此 collection 不包含元素,则返回 true。 abstract Iterator<E> iterator() 返回在此 collection 中的元素上进行迭代的迭代器。 boolean remove(Object o) 从此 collection 中移除指定元素的单个实例(如果存在)(可选操作)。 boolean removeAll(Collection<?> c) 从此 collection 中移除包含在指定 collection 中的所有元素(可选操作)。 boolean retainAll(Collection<?> c) 仅在此 collection 中保留指定 collection 中所包含的元素(可选操作)。 abstract int size() 返回此 collection 中的元素数。 Object[] toArray() 返回包含此 collection 中所有元素的数组。 <T> T[] toArray(T[] a) 返回包含此 collection 中所有元素的数组;返回数组的运行时类型是指定数组的类型。 String toString() <--很重要 返
其实我们并不一定要把这些方法都记住
我们只要记住Collection对象实现了这些种类的方法就可以了(可以现查API,不是..
但是确实,这些方法记住了有很大的用处.
添加元素(两种) 添加一个元素,添加一个集合 删除元素(三种) 删除一个元素,删出一个集合,只保留一个集合 判断大小 变成数组 是否为空 清空
java集合的泛型使用
到这里我们还要讲解一个问题,就是除了
Map的集合类型(看看上面的继承表,map是单独一个分支)都可以传入Collection为参数的函数里面去.
public class Test {
public static void display(Collection<?> a){
System.out.println(a);
}
public static void main(String[] args) {
List<Integer> list=new LinkedList<>();//链表
list.add(1);
list.add(2);
list.add(4);
list.add(3);
display(list);//[1, 2, 4, 3]
Set<Integer> set=new TreeSet<>();//树集
set.addAll(list);
//在这里之所以两者输出不同,是因为树集有着一个自动排序的功能.其原因在于对于treeset内部结构的实现和LinkedList有所不同
display(set);//[1, 2, 3, 4]
}
}
java集合中使用泛型的好处
为什么在java集合中经常使用泛型.除了为了防止输入错误的数据,更重要的是如果用了泛型也会让操作更加的方便,省去了强制转化的过程.
以下两个是准备
public class AppleAndOrangeWithOutGenerics {
@SuppressWarnings("unchecked")//这个只能抑制警告信息,用它就不会有警告
public static void main(String args[]) {
/**
* 不用泛型
*/
// ArrayList apples=new ArrayList();
// for (int i = 0; i <3 ; i++) {
// apples.add(new Apple());
//在ArrayList无论放进去之前是什么,再放进去之后都会变成Object类型,
// apples.add(new Orange());
//会报一个小小的warning,因为没有使用泛型.<-只有删掉这个句子执行才不报错
// }
// for (int j = 0; j <apples.size() ; j++) {
// System.out.println(((Apple)apples.get(j)).id());
//如果没有泛型的拦截,输入Orange类型根本不会被发现.非常的危险
// }
/**
* 使用泛型
*/
ArrayList<Apple> apples = new ArrayList();
for (int i = 0; i < 3; i++) {
apples.add(new Apple());
// apples.add(new Orange());//在这里直接就报错了,让这种错误在编译期就被发现
}
for (int j = 0; j < apples.size(); j++) {
//用了反省之后连强制转换都不需要了
System.out.println(( apples.get(j)).id());//如果没有泛型的拦截,输入Orange类型根本不会被发现.非常的危险
}
}
}
所以使用泛型有很大的好处.
(三) List
List是一个有序集合,元素会增加到容器中特定的位置,可以采用两种方式访问元素:使用迭代器访问或者使用一个整数索引访问.后一种方式称为随机访问.
为此List接口多定义了一些方法,来实现这一点
void add(int index,E element);//这个和上面不同,带了index. void remove(int index); E get(int index); E set(int index,E element);
我们知道实现LIST接口的类中有一个类叫做
AbstractList,他的两个子类分别是LinkedList和ArrayList这两种.那么问题是链表可不可以使用这个add方法.
答案是可以的.实际上链表使用随机访问,只不过是慢了点而已.如果有可能,还是使用迭代器为好.
LIST主要有两种类.一个是LinkedList一个是ArrayList.
LinkedList
我们就从一个程序看一看LinkedList到底怎么用.
/**
* LinkedLIST也像ArrayList一扬实现了基本的List接口,但是他执行一些操作效率更高,比如插入.
* LIST为空就会抛出NoSuchElement-Exception
* Created by 22643 on 2020/4/17.
*/
public class LinkedListFeatures {
public static void main(String[] args) {
LinkedList<Pet> pets=new LinkedList<Pet>(Pets.arrayList(5));//后面括号中的意思是生成五个Pets对象
System.out.println("pets = [" + pets + "]");
System.out.println("pets.getFirst() "+pets.getFirst());//取第一个
System.out.println("pets.element "+pets.element());//也是取第一个,跟first完全相同.
//如果列表为空如上两个内容返回NoSuchElement-Exception
System.out.println("pets.peek()"+pets.peek());//peek跟上面两个一扬,只是在列表为空的时候返回null
System.out.println(pets.removeFirst());
System.out.println(pets.remove());//这两个完全一样,都是移除并返回列表头,列表空的时候返回NoSuchElement-Exception
System.out.println(pets.poll());//稍有差异,列表为空的时候返回null
pets.addFirst(new Rat());//addFirst将一个元素插入头部,addLast是插到尾部
System.out.println(pets);
pets.add(new Rat());//将一个元素插入尾部
System.out.println(pets);
pets.offer(new Rat());//与上面一扬,将一个元素插入尾部
System.out.println(pets);
pets.set(2,new Rat());//将替换为指定的元素
System.out.println(pets);
}
}
实际上LinkedList有非常多的方法,因为LinkedList是被用来实现多中数据结构的.不但可以实现队列,甚至还有可以实现栈的相关方法.
我们对此进行分类:
栈相关的操作方法:
E poll() 找到并移除此列表的头(第一个元素)。 peek() 找到但不移除此列表的头(第一个元素)。 void addFirst(E o) 加入开头可以当作add用
队列操作方法:(LinkedList实现了Queue的接口,所以说可以操作用来构建队列)
注意队列是FIFO(先进先出)队列,所以按照实现,从普通队列是从队列的尾部插入,从头部移除,.
所以方法如下:
E element() 首元素 boolean offer(E o)将指定队列插入桶 E peek() 检索,但是不移除队列的头 E pool()检索并移除此队列的头,为空返回null. E remove()检索并移除此队列的头
一般来讲集合中的方法在移除方法都会有一个为空的时候返回null的方法,和一个为空的时候返回null的方法.类似于pool()和remove()
我们一会到Queue的时候还会将这些再将一次.
ArrayList
我们也从一个程序来看这个
public class ListFeatures {
public static void main(String[] args) {
Random rand=new Random(47);//相同的种子会产生相同的随机序列。
List<String> list=new ArrayList<>();
list.add("demo3");
list.add("demo2");
list.add("demo1");//加入方法
System.out.println("插入元素前list集合"+list);//可以直接输出
/**
* /void add(int index, E element)在指定位置插入元素,后面的元素都往后移一个元素
*/
list.add(2,"demo5");
System.out.println("插入元素前list集合"+list);
List<String> listtotal=new ArrayList<>();
List<String> list1=new ArrayList<>();
List<String> list2=new ArrayList<>();
list1.add("newdemo1");
list1.add("newdemo2");
list1.add("newdemo2");
/**
* boolean addAll(int index, Collection<? extends E> c)
* 在指定的位置中插入c集合全部的元素,如果集合发生改变,则返回true,否则返回false。
* 意思就是当插入的集合c没有元素,那么就返回false,如果集合c有元素,插入成功,那么就返回true。
*/
boolean b=listtotal.addAll(list1);
boolean c=listtotal.addAll(2,list2);
System.out.println(b);
System.out.println(c);//插入2号位置,list2是空的
System.out.println(list1);
/**
* E get(int index)
* 返回list集合中指定索引位置的元素
*/
System.out.println(list1.get(1));//list的下标是从0开始的
/**
* int indexOf(Object o)
* 返回list集合中第一次出现o对象的索引位置,如果list集合中没有o对象,那么就返回-1
*/
System.out.println(list1.indexOf("demo"));
System.out.println(list1.indexOf("newdemo2"));
//如果在list中有相同的数,也没有问题.
//但是如果是对象,因为每个对象都是独一无二的.所以说如果传入一个新的对象,indexof和remove都是无法完成任务的
//要是删除,可以先找到其位置,然后在进行删除.
//Pet p=pets.get(2);
//pets.remove(p);
/**
* 查看contains查看参数是否在list中
*/
System.out.println(list1.contains("newdemo2"));//true
/**
* remove移除一个对象
* 返回true和false
*/
//只删除其中的一个
System.out.println(list1.remove("newdemo2"));//[newdemo1, newdemo2]
System.out.println(list1);
List<String> pets=list1.subList(0,1);//让你从较大的一个list中创建一个片段
//containall一个list在不在另一个list中
System.out.println(pets+"在list中嘛"+list1.containsAll(pets));//[newdemo1]在list中嘛true
//因为sublist的背后就是初始化列表,所以对于sublist的修改会直接反映到原数组上面
pets.add("new add demo");
System.out.println(list1);//[newdemo1, new add demo, newdemo2]
Collections.sort(pets);
System.out.println(
pets
);//new add demo, newdemo1
System.out.println(list1.containsAll(pets));//true-----变换位置不会影响是否在list1中被找到.
list1.removeAll(pets);//移除在参数list中的全部数据
/**
* list1[newdemo1, new add demo, newdemo2]
* pets[new add demo, newdemo1]
*/
System.out.println(list1);//[newdemo2]
System.out.println(list1.isEmpty());//是否为空
System.out.println(list1.toArray());//将list变为数组
//list的addAll方法有一个重载的.可以让他在中间加入
}
}
这个比较适合非顺序存储.
(四)(五)Set
Set实际上也是一种映射关系的集合和Map比较像.但是它实现的依然是Collection的接口.
而且Set中的方法和Collection的方法几乎完全一样.
唯一的区别在于add方法不允许增加重复的元素.在调用equal时,如果两个Set中的元素都相等,无论两者的顺序如何,这两个Set都会相等.
set的特性
Set不保存重复的元素. Set就是Collection,只是行为不同. HashSet使用了散列,它打印的时候,输出的元素不会正常排列 TreeSet使用了储存在红黑树结构中,,所以输出的元素会正常排列
当然Set最主要的工作就是判断存在性,目的是看一个元素到底存不存在这个集合之中.
下面放上两个Set的例子:
SortedSet(TreeSet)
public class SortedSetOfInteger {
public static void main(String[] args) {
Random random=new Random(47);
SortedSet<Integer> intset=new TreeSet<>();
for (int i = 0; i <100 ; i++) {
intset.add(random.nextInt(30));
}
System.out.println(intset);//set特性只能输入相同的数,别看输入了100个数,但是实际上只有30个进去了.
//这个有序了.这就是treeset的功劳,因为内部的实现时红黑树,所以来说.这就简单了一些
}
}
HashSet
public class SetOfInteger {
public static void main(String[] args) {
Random rand=new Random(47);
Set<Integer> intset=new HashSet<>();//创建一个HashSet
for (int i = 0; i <100 ; i++) {
intset.add(rand.nextInt(30));
}
System.out.println(intset);//set特性只能输入相同的数,别看输入了100个数,但是实际上只有30个进去了.
}
}
这里要讲一下HashSet。HashSet不在意元素的顺序,根据属性可以快速的访问所需要的对象。散列表为每个对象计算一个整数,成为散列码...散列码是实例产生的一个整数。
散列表(HashSet)散列表用链表数组实现。每个列表称为通。想要查找表中对象的位置就计算它的散列码。然后与通的总数取余,得到的数就是保存这个元素的通的索引。
但是桶总有被沾满的一刻。
为了应对这种情况,需要用新对象与桶中所有对象比较,看是否存在。
为了控制性能就要能定义初始桶数,设置为要插入元素的75%-150%,最好为素数。
这个时候就要执行再散列,让这个散列表获得更多的内容。
再散列:
需要创建一个桶数更多的表,并将全部元素插入这个新表中。装填因子绝对什么时候在执行,如果装填因子为0.75那么就是在表中75%的位置被沾满时,表会给如双倍的桶数自动散列。
Queue
队列是数据结构中比较重要的一种类型,它支持 FIFO,尾部添加、头部删除(先进队列的元素先出队列),跟我们生活中的排队类似。
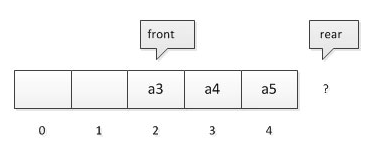
但是在集合中的Queue并没有单独的实现类,而是用LinkedList实现的。其实你只要看一眼LinkedList的方法就知道,他完全可以实现队列的操作。
add()尾部添加 removeFirst()删除头部元素 peek()查看头部元素
Queue主要有两种不同的类型.
分别是优先级队列和Deque队列
PriorityQueue
优先级队列中元素可以按照任意的顺序插入,却按照目标排序的顺序进行检索,也就是无论什么时候调用remove移除的都是当前最小的元素。
优先级使用了一种堆,一个可以自我调节的二叉树,对树进行执行添加和删除。它可以让最小的元素移动到跟,而不必花时间对其排序。
当然,你也可以自己对其进行排序.
小栗子:
import java.text.DecimalFormat;
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Queue;
/**
* @Author:sks
* @Description:
* @Date:Created in 10:39 2018/1/11
* @Modified by:
**/
//二维平面上一个点
class point {
//坐标x
double x;
//坐标y
double y;
public point(double x, double y){
this.x = x;
this.y = y;
}
}
//排序函数
class PointComparator {
private point pointOne;
private point pointTwo;
public double distance;
public PointComparator(point pointOne,point pointTwo)
{
this.pointOne = pointOne;
this.pointTwo = pointTwo;
computeDistance();
}
//计算两点之间距离
private void computeDistance() {
double val = Math.pow((this.pointOne.x - this.pointTwo.x),2) +
Math.pow((this.pointOne.y - this.pointTwo.y),2);
this.distance = Math.sqrt(val);
}
}
public class PriorityQueuep_test {
public static void main(String args[]){
Comparator<PointComparator> OrderDistance = new Comparator<PointComparator>(){
public int compare(PointComparator one, PointComparator two) {
if (one.distance < two.distance)
return 1;
else if (one.distance > two.distance)
return -1;
else
return 0;
}
};
//定义一个优先队列,用来排序任意两点之间的距离,从大到小排
Queue<PointComparator> FsQueue = new PriorityQueue<PointComparator>(10,OrderDistance);
for (int i=0;i<6;i++){
java.util.Random r= new java.util.Random(10);
point one =new point(i*2+1,i*3+2);
point two =new point(i*5+2,i*6+3);
PointComparator nodecomp = new PointComparator(one,two);
DecimalFormat df = new DecimalFormat("#.##");
FsQueue.add(nodecomp);
}
DecimalFormat df = new DecimalFormat("#.###");
for (int i = 0;i<6;i++){
System.out.println(df.format(FsQueue.poll().distance));
}
}
}
Deque
deque也有些复杂,它可以用ArrayDeque实现,也可以用LinkedList实现.
线性集合,支持两端的元素插入和移除。Deque是
double ended queue的简称,习惯上称之为双端队列。大多数Deque 实现对它们可能包含的元素的数量没有固定的限制,但是该接口支持容量限制的deques以及没有固定大小限制的deque。作者:我是吸血鬼 链接:https://www.jianshu.com/p/d78a7c982edb 来源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
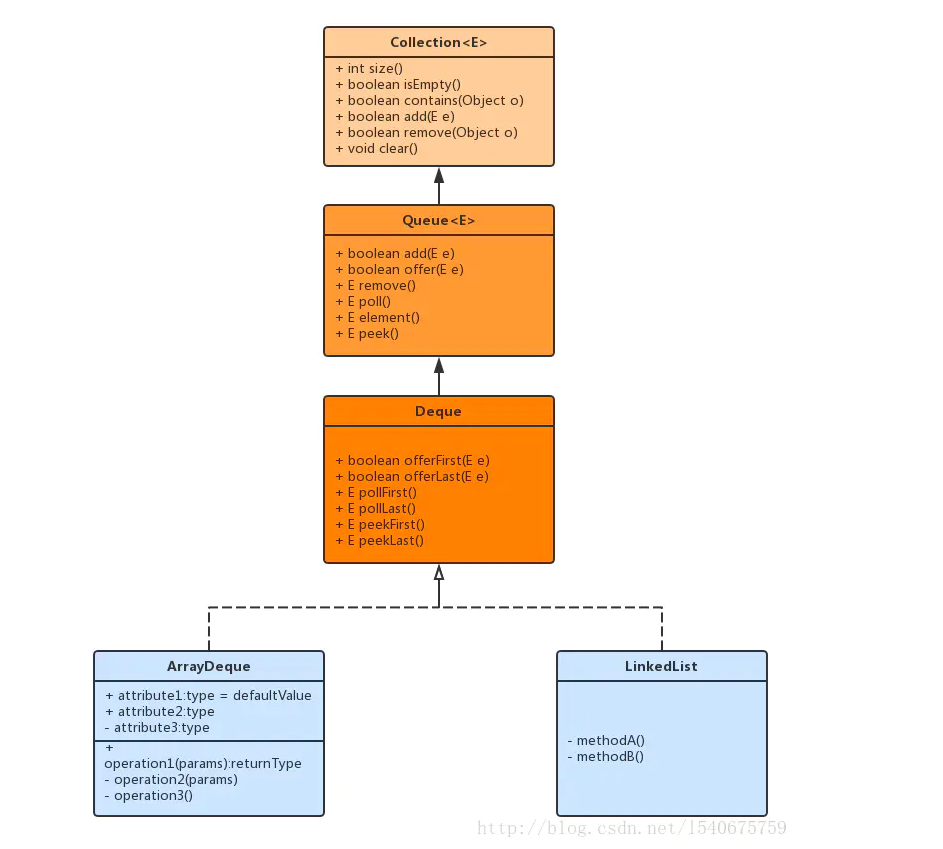
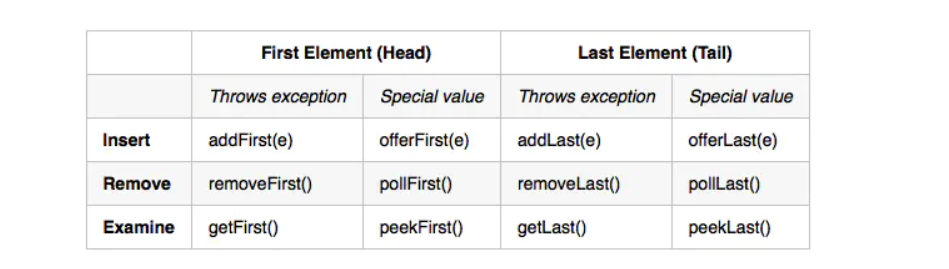
因为本身也是LinkedList实现的,所以其本身的方法和LinkedList差不了多少.
小栗子:
public class Main {
public static void main(String[] args) {
Deque<String> deque = new LinkedList<>();
deque.offerLast("A"); // A
deque.offerLast("B"); // B -> A
deque.offerFirst("C"); // B -> A -> C
System.out.println(deque.pollFirst()); // C, 剩下B -> A
System.out.println(deque.pollLast()); // B
System.out.println(deque.pollFirst()); // A
System.out.println(deque.pollFirst()); // null
}
}
Stack
stack的名字大家都知道,就是栈.一个先进后出的数据结构,这里我并不认为应该使用java集合中提供的栈集合.
而是应该使用LinkedList来构建集合: 一个小任务:
用LinkedList实现栈
public class Stack<T> {
private LinkedList<T> storage=new LinkedList<>();//用LinkedList作为栈的核心
public void push(T v){ storage.addFirst(v);}//
public T peek(){ return storage.getFirst();}
public T pop(){return storage.removeFirst();}
public boolean empty(){return storage.isEmpty();}
public String toString(){return storage.toString();}
}
这样做有一个好处,就是这样的栈可以有更多种的方法,可以采用更多种的方式.无疑这样的栈会更好一些.
所以我推荐大家用栈的时候,用LinkedList来实现.
MAP
讲了Collection接口实现的各种集合,我们就要讲讲非Collection的集合.这意味着你在Collection中记住的方法在这个里面完全用不到了.
我们知道一些键的信息,想要知道与之对应的元素.映射结构就是为此设计的,映射用来存放键值对,如提供了键就能查到值.
和Set一样,HashMap要比TreeMap要快上一些,但是TreeMap有序.这与Set很相似,毕竟Set其实也是映射结构.
每当往映射加入对象是,必须同时提供一个键.
键是唯一的,不能对同一个键放两个值.如果对同一个键调用两次put方法,第二次调用会取代第一个.
要想处理所有的键和值,那就应该使用foreach
列子如下:
public class MapOfList {
public static Map<Person, List<? extends Pet>> people=new HashMap<>();
static {
people.put(new Person("dawn"), Arrays.asList(new Cymric("Molly"),new Mutt("Spot")));
//就写一个了,有点懒了.
}
public static void main(String[] args) {
System.out.println(people.keySet());//返回的是键组成的set
System.out.println(people.values());//返回的时值组成的set
for (Person person:people.keySet()
) {
System.out.println(person+"has :");
for (Pet pet:people.get(person)
) {
System.out.println(pet);
}
}
}
}
下面还有一个HashMap使用的例子
public class PetMap {
public static void main(String[] args) {
Map<String, Pet> petMap=new HashMap<String, Pet>();
petMap.put("My Cat",new Cat("MALL"));
petMap.put("My Dog",new Dog("DOGGY"));
petMap.put("My Haster",new Hamster("Bosco"));
System.out.println(petMap);
Pet dog=petMap.get("My Dog");
System.out.println(dog);
System.out.println(petMap.containsKey("My Dog"));//
System.out.println(petMap.containsValue(dog));//
}
}

- Java集合接口详解
- Map、Set、Iterator迭代详解与Java平台的集合框架
- 详解JAVA高质量代码之数组与集合
- jdk命令集合详解(有关其他的java/bin中的*.exe讲解)
- java如何对map进行排序详解(map集合的使用)
- java集合(2)- java中HashMap详解
- java之集合Collection详解之2
- Map、Set、Iterator迭代详解与Java平台的集合框架
- Java集合的排序和HashCode方法详解
- java_集合体系之:LinkedList详解、源码及示例——04
- Java 集合详解
- JAVA常用集合框架用法详解——基础篇
- Java 集合类图 详解
- java之集合Collection 详解之4
- Java 集合体系详解——Set体系无序不重复集合
- Map、Set、Iterator迭代详解与Java平台的集合框架
- java中集合常用类及其详解
- Java集合的排序和HashCode方法详解
- Java学习系列(七)Java面向对象之集合框架详解(上)
- java_集合体系之Vector详解、源码及示例——05