Python爬取豆瓣电影top250
我的目录
1.准备工作
1.1、安装Python
2.1建立jupyter环境
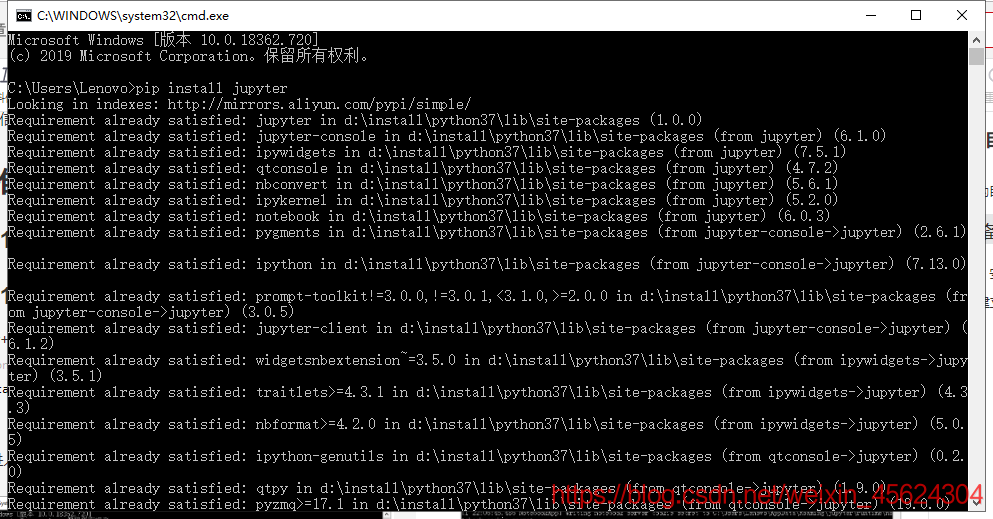
window+R,输入cmd,进入控制台
pip install jupyter
3.1进入编辑环境
新建一个文件夹,打开文件夹,进入控制台,输入jupyter notebook,即进入编辑环境。

进入编辑环境页面

2.分析网页
2.1 打开豆瓣电影top250网页

2.2 分析网页结构
查看每一页网页的url,分析它的规律

可以看出,从第二页开始,URL不同的都是’start='后面这个数,并且基数都为25。则可以分析出第一页为:https://movie.douban.com/top250?start=0&filter=
2.3 用for循环分析结果
也可用for循环来分析,结果如下:
for page in range(0,226,25): print (page)

2.4 用page函数表示这十页的URL链接
代码如下:
for page in range(0,226,25): url= 'https://movie.douban.com/top250?start=%s&filter='%page print (url)
结果如下:

3.爬取网页
3.1 请求HTML源代码
首先,安装requests,(win+R—输入cmd—pip install requests—enter),结果如下:

请求HTML以第一页为例:
import requests test_url='https://movie.douban.com/top250?start=0&filter='
注:此处单引号也可以改为双引号,目的是将test_url变为字符串。
3.2 到TOP250上对代码进行审查
右击—检查元素—network—All—刷新,打开如下:

3.3 请求网页及请求方法
首先点击第一个网址,再点击header,由图中可以知道请求网址及方法:

代码如下:
import requests test_url='https://movie.douban.com/top250?start=0&filter='requests.get(url=test_url)
结果如下:

若改为:
import requests test_url='https://movie.douban.com/top250?start=0&filter='requests.get(url=test_url).text
同样没有返回值。
则是因为浏览器识别出这个语句为爬虫程序,所以拒绝返回值给我们。
3.4 伪装浏览器
伪装浏览器主要是用来躲过浏览器识别,便于成功获取数据。
首先将代码审查中的用户代理复制到请求代码中,用于伪装。
用户代理为:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3724.8 Safari/537.36
代码表示如下:
import requests
test_url='https://movie.douban.com/top250?start=0&filter='
#设置浏览器代理,它是一个字典
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3724.8 Safari/537.36'
}
#请求源代码向服务器发出请求
requests.get(url=test_url,headers = headers).text
结果如下:

4.信息筛选
分析工具有:
xpath,re(正则表达式),BeautifulSoup,即BS4。
4.1 安装lxml库
win+R—输入cmd—pip install lxml—enter),结果如下:

4.2 过滤
代码如下:
from lxml import etree html_etree = etree.HTML(reponse) #reponse=requests.get(url=test_url,headers = headers).text print ( html_etree)
html_etree可任意命名,HTML必须为大写。
运行结果如下:

4.3 从网页上提取信息
以泰坦尼克号为例
代码如下:
from lxml import etree
html_etree = etree.HTML(reponse)
#reponse=requests.get(url=test_url,headers = headers).text
#过滤
html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li[6]/div/div[2]/div[1]/a/span[1]/text()'
结果如下:

4.4 提取整个网页的xpath路径
打开网页—检查—li
如图所示:
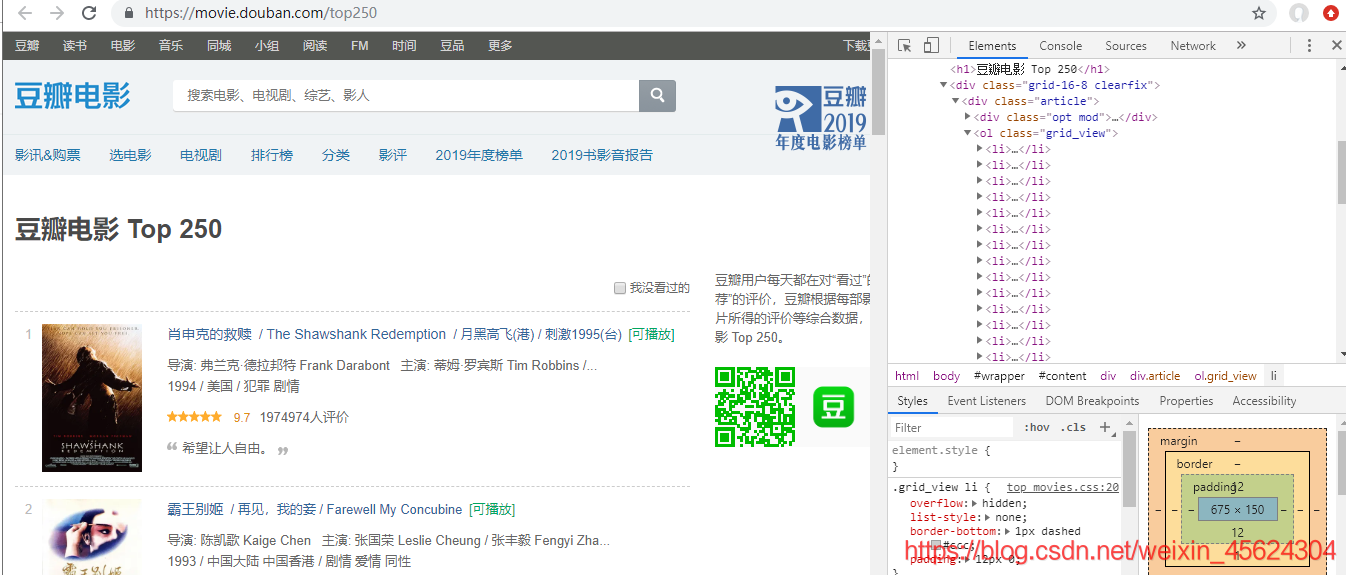
将每一个电影的xpath路径复制下来,可得:

用语句表达为:
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
结果如下:
共有25个返回值。

也可以用len()函数查看返回值的长度。
结果如下:

4.5 获取电影名
从电影名分析,可得,电影名的链接中只有/li[]中的数字不一样。如图:

则代码如下:
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
name=item.xpath('./div/div[2]/div[1]/a/span[1]/text()')
print (name)
name括号中的.表示li中的一大段路径。
结果如下:

上图显示为数组,则代码后加[0],输出纯文字,如图:

4.6 获取电影链接
过程和获取电影名同理,直接附上结果:
代码如下:
#过滤
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
name=item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
print (name)
#获取链接
dy_url = item.xpath ('./div/div[2]/div[1]/a/@href')[0]
print (dy_url)
结果如下:

4.7获取电影星级
过程和获取电影名同理,直接附上结果。
代码如下:
rating = item.xpath('./div/div[2]/div[2]/div/span[1]/@class')[0]
print (rating)
结果如下:

4.8 获取电影评分
过程和获取电影名同理,直接附上结果。
代码如下:
rating_num = item.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
print (rating_num)
结果如下:

4.9 获取电影人数
过程和获取电影名同理,直接附上结果。
代码如下:
content = item.xpath('./div/div[2]/div[2]/div/span[4]/text()')
print (content)
结果如下:

5.python输出方法
5.1用分隔符美化输出结果
代码如下:
content = item.xpath('./div/div[2]/div[2]/div/span[4]/text()')
print (content)print("~"*80)
结果如下:

注:print(""*80)表示用分隔,有80个符号。“”符号可以换。
5.2 可以同时print多个值
代码如下:
from lxml import etree
html_etree = etree.HTML(reponse)
#reponse=requests.get(url=test_url,headers = headers).text
#过滤
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
name=item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
#print (name)
#获取链接
dy_url = item.xpath ('./div/div[2]/div[1]/a/@href')[0]
#print (dy_url)
#评分
rating = item.xpath('./div/div[2]/div[2]/div/span[1]/@class')[0]
#print (rating)
rating_num = item.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
#print (rating_num)
#人数
content = item.xpath('./div/div[2]/div[2]/div/span[4]/text()')
print("——"*80)
print (name,dy_url,rating,rating_num,content)
结果如下:

6.将爬取的内容保存
6.1 保存的格式
TXT,HTML,Excel,CSV等。
6.2 爬取电影排名
代码如下:
from lxml import etree
html_etree = etree.HTML(reponse)
#reponse=requests.get(url=test_url,headers = headers).text
#过滤
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
#排名
rank=item.xpath('./div/div[1]/em/text()')[0]
#print (rank)
name=item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
#print (name)
#获取链接
dy_url = item.xpath ('./div/div[2]/div[1]/a/@href')[0]
#print (dy_url)
#评分
rating = item.xpath('./div/div[2]/div[2]/div/span[1]/@class')[0]
#print (rating)
rating_num = item.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
#print (rating_num)
#人数
content = item.xpath('./div/div[2]/div[2]/div/span[4]/text()')
print("——"*80)
print (rank,name,dy_url,rating,rating_num,content)
结果如下:

6.3 用正则表达式re匹配星级中的数字
首先导入re这个包,具体代码如下:
import re
test = "rating5-t"
re.findall('rating(.*?)-t',test)
注:需要提取的地方用(.*?)代替
提取评价人数,代码如下:
import re
num = "1974974人评价"
re.findall('(.*?)人评价',num)
结果如下:

综合如下:
rating = item.xpath('./div/div[2]/div[2]/div/span[1]/@class')[0]
rating = re.findall('rating(.*?)-t',rating)
print ("rating=",rating)
rating_num = item.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
#print (rating_num)
#人数
content = item.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]
print("——"*80)
print (rank,name,dy_url,rating,rating_num,content)
结果:

6.4 评分标准化
将电影评分正规化(区分星级)
代码如下:
rating = item.xpath('./div/div[2]/div[2]/div/span[1]/@class')[0]
rating = re.findall('rating(.*?)-t',rating)[0]
if len(rating)==2:
star = int(rating) / 10
else:
star=rating
print ("star=",star)
结果:

所有格式标准化
具体代码如下:
from lxml import etree
html_etree = etree.HTML(reponse)
#过滤
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
#排名
rank=item.xpath('./div/div[1]/em/text()')[0]
#print (rank)
name=item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
#print (name)
#获取链接
dy_url = item.xpath ('./div/div[2]/div[1]/a/@href')[0]
#print (dy_url)
#评分
rating = item.xpath('./div/div[2]/div[2]/div/span[1]/@class')[0]
rating = re.findall('rating(.*?)-t',rating)[0]
if len(rating)==2:
star = int(rating) / 10
else:
star=rating
rating_num = item.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
#print (rating_num)
#人数
content = item.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]
content= re.sub(r'\D',"",content)
print("——"*80)
print (rank,name,dy_url,rating,rating_num,content)
结果如下:

6.5 将爬取的内容保存到CSV中
首先导入CSV的包,具体代码如下:
import csv
fp = open("./豆瓣top250.csv", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #我要写入 .
#写入内容
writer. writerow(('排名','名称','链接', '星级','评分','评价人数'))
#关闭文件夹
fp.close ()
所有代码为:
from lxml import etree
import re ,csv
fp = open("./豆瓣top250.csv.", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #我要写入 .
#写入内容
writer. writerow(('排名','名称','链接', '星级','评分','评价人数'))
for page in range(0,226,25):
print("正在获取第%s页"%page)
url= 'https://movie.douban.com/top250?start=%s&filter='%page
#请求源代码向服务器发出请求
reponse=requests.get(url=test_url,headers = headers).text
html_etree = etree.HTML(reponse)
#过滤
li = html_etree.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in li:
#排名
rank=item.xpath('./div/div[1]/em/text()')[0]
#print (rank)
name=item.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
#print (name)
#获取链接
dy_url = item.xpath ('./div/div[2]/div[1]/a/@href')[0]
#print (dy_url)
#评分
rating = item.xpath('./div/div[2]/div[2]/div/span[1]/@class')[0]
rating = re.findall('rating(.*?)-t',rating)[0]
if len(rating)==2:
star = int(rating) / 10
else:
star=rating
rating_num = item.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
#print (rating_num)
#人数
content = item.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]
content= re.sub(r'\D',"",content)
print("——"*80)
print (rank,name,dy_url,rating,rating_num,content)
writer. writerow((rank,name,dy_url,rating,rating_num,content))
fp.close()
注:fp.close()不能放在for循环中。
运行结果为:

7.查看结果
最终保存的文件,会直接保存在我们一开始所创建的文件夹中,格式为CSV。

打开效果

爬取成功。
- 点赞 2
- 收藏
- 分享
- 文章举报
 要吃冰激凌。
发布了2 篇原创文章 · 获赞 2 · 访问量 121
私信
关注
要吃冰激凌。
发布了2 篇原创文章 · 获赞 2 · 访问量 121
私信
关注

- [python爬虫] BeautifulSoup和Selenium对比爬取豆瓣Top250电影信息
- Python爬虫小案例:豆瓣电影TOP250
- Python爬取豆瓣电影TOP250相关数据
- Python爬虫初学(1)豆瓣电影top250评论数
- Python爬取豆瓣电影TOP250,结果输出为Execl,保存海报图片。
- Python爬虫学习笔记(3) _豆瓣电影TOP250(3)采用sql存储的方法爬取豆瓣电影
- Python 爬虫:豆瓣电影Top250,包括电影导演、类型、年份、主演
- 利用python爬虫爬取豆瓣电影Top250
- Python爬虫入门——2. 4 利用正则表达式爬取豆瓣电影 Top 250
- python 爬虫 保存豆瓣TOP250电影海报及修改名称
- Python爬虫学习笔记(2) _豆瓣电影TOP250(2)爬取详细数据,保存为CSV文件【urllib、request、bs4、error、CSV】
- Python爬取豆瓣电影top250
- (7)Python爬虫——爬取豆瓣电影Top250
- Python爬虫获取豆瓣电影TOP250
- Python爬虫学习笔记(1)_豆瓣电影Top250(1)简单的图片爬取
- python爬取豆瓣电影top250
- Python 爬取豆瓣电影Top250(一)
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
- Python爬虫----抓取豆瓣电影Top250
- 再谈python爬取豆瓣电影TOP250