Python办公自动化实践1:从多个excel表格中抽取数据汇总到1个sheet页中
问题:从当前目录或子目录中查询符合条件的excel表格,并从这些excel表格中抽取符合条件的行汇总到1个excel的sheet页中。
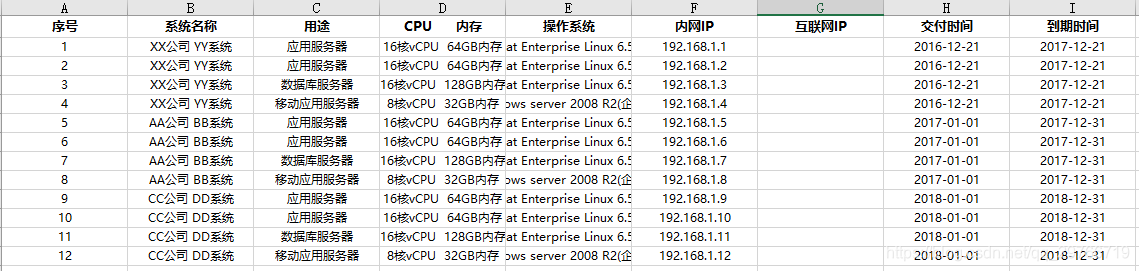
所有excel表格名字为:交付清单1、交付清单2,交付清单3……,格式也一样,样式如下:
 将类似多个excle表中,抽取序号中的N行(上图是1~4行)汇总到指定excel的sheet页中。
将类似多个excle表中,抽取序号中的N行(上图是1~4行)汇总到指定excel的sheet页中。
该表格在DataFrame中的显示方式如下:

一、希望得到的汇总表格为:
1、列头是:“系统名称、用途 、CPU 内存、操作系统、内网IP、 互联网IP 、交付时间 、到期时间”
注意:列头(columns header)是合并格。
2、删除掉A列,删除最后的空行
3、将交付时间,到期时间从datetime类型转变为字符串类型; #第三方模块datetime
4、将汇总表格中所有的单元格 字体,大小,字体是否据中等 全部调为一致;#第三方模块xlsxwriter
二、具体实现步骤如下:
1、查询符合条件的excel表; #第三方模块os
2、用pandas读取符合条件的表;
3、对读入后的excel表(dataframe)进行裁剪;
4、将多个excel表格汇总到单一excel的sheet页中;
5、将最终的sheet页再进行单元格格式调整,再重新输出新的sheet页;
该脚本涉及第三方模块有:pandas,os,datetime,xlsxwriter。
三、代码展现
1、查询符合条件的excel表
a、通过os.walk查询当前目录及子目录中的文件
b、在这些文件中筛选匹配“交付清单”的文件
c、将匹配文件和绝对路径“连接后”存放到列表中;
import numpy as np import pandas as pd import xlsxwriter import os from pandas import Series,DataFrame from datetime import date,timedelta,datetime path=r'D:\cloud_files' path_out=r'D:\cloud_files\vmachines_list.xlsx' substr='交付清单' file_list=[] for path_name,dirs,filename in os.walk(path): for files in filename: if files.find(substr)!=-1: file_list.append(os.path.join(path_name,files))
该段重点:
a、path_name 存放文件所在的绝对路径,filename 存放文件名;
b、files.find(substr) 匹配substr字符串的文件,若不匹配返回-1,
若匹配,返回该字符串在文件名中第一次匹配成功的位置。
c、os.path.join(path_name,files)将绝对路径与匹配的文件结合起来,再存放到file_list列表中。
file_list列表中的数据:
['D:\\cloud_files\\~$交付清单01.xlsx', 'D:\\cloud_files\\交付清单01.xlsx', 'D:\\cloud_files\\交付清单02.xlsx', 'D:\\cloud_files\\交付清单03.xlsx']
在交付清单01.xlsx 是打开的情况下,提交该段程序,将会出现~$交付清单01.xlsx。
表示该表被进程占用。
2、用pandas读取符合条件的表
a、通过pandas读取在file_list中的excel表格;
b、并将结果写入到vm_tmplist 临时列表中。
vm_tmplist=[] for item in file_list: if '~$' not in item: temp=pd.read_excel(item,sheet_name='交付清单',skiprows=2,usecols='B:J') vm_tmplist.append(temp)
该段重点:
a、跳过excel中的前两行,并定义B到J列区域;
3、对读入后的excel表(dataframe)进行裁剪
a、选择合适的列头;
b、删除掉A列,删除最后的空行
c、将交付时间,到期时间从datetime类型转变为字符串类型;
转换的原因是xlsxwriter不支持对时间类型,index,columns类型的单元格进行格式化。
官网原文:It isn’t possible to format any cells that already have a format
such as the index or headers or any cells that contain dates or datetimes .
def trim_frame(df):
df.columns=np.concatenate([df.columns[:3],df.iloc[0,3:5],df.columns[5:]])
df=df.dropna(subset=['系统名称'])
df=df.loc[(df['序号'].isin(range(1,10,1)))]
df['交付时间']=pd.to_datetime(df['交付时间'],errors='coerce').dt.strftime('%Y-%m-%d')
df['到期时间']=pd.to_datetime(df['到期时间'],errors='coerce').dt.strftime('%Y-%m-%d')
return df
for value in vm_tmplist:
df=trim_frame(value)
vm_trimlist.append(df)
本段重点:
a、将前三列(0,1,2)的columns(列名)与第0行的第3、4列及columns第5列至最后一列合并;
通过numpy.concatenate函数合并
b、将“系统名称”列中空格(NaN)所在的行去掉;
c、选取“序号”列中数字为1~10所在的行;
d、将“交付时间”,“到期时间”两列datetime类型数据转换为string。
e、将“修剪好的”表存入vm_trimlist列表中;
4、将多个excel表格汇总到单一excel的sheet页中
a、调用xlsxwriter引擎;
b、从vm_list列表中选取“修剪好”的数据,按顺序写入到“虚机清单”sheet页中;
c、保存写好后的数据.writer.save()
def trimDfs_to_Excel(df_list, sheets, path_out): writer = pd.ExcelWriter(path_out,engine='xlsxwriter') row = 0 for dataframe in df_list: dataframe.to_excel(writer,sheet_name=sheets,startrow=row,startcol=0,index=False) row = row + len(dataframe.index) + 1 writer.save() trimDfs_to_Excel(vm_trimlist,'虚机清单',path_out)
本段重点:
a、从vm_trimlist中读取数据(注:df_list是形参)
b、定义row=0,开始写的行startrow=row。
第2张表写入时,启始位置是第1张表的长度len(dataframe.index) 加1(第一行是从0开始的,所以加1,避免第2张表第一行冲掉第一张表最后一行)
c、to_excel(index=False)是防止将索引(index)写入excel表内。
5、将最终的sheet页再进行单元格格式调整,重新输出新的sheet页;
a、重新读取输出的表;
b、读取后,将该表删掉;因为xlsxwriter不能对原表进行修改;
c、对单元格及列头(columns header)进行格式化;
d、重新输出新表
def formatExcel(df,path):
df=df.loc[df['序号'].isin(range(1,10,1))]
os.remove(path)
df.reset_index(drop=True,inplace=True)
for i in df.index:
df['序号'].at[i]=i+1
writer = pd.ExcelWriter(path,engine='xlsxwriter')
df.to_excel(writer,sheet_name='虚机清单',index=False)
workbook=writer.book
worksheet=writer.sheets['虚机清单']
fmt_cell={'bold':False,'font_name':'微软雅黑','font_size':9,'align':'center','valign':'vcenter','border':0,'num_format':'#,##0'}
fmt_header={'bold':True,'font_name':'微软雅黑','font_size':10,'align':'center','valign':'vcenter','border':0}
cell_format=workbook.add_format(fmt_cell)
header_format=workbook.add_format(fmt_header)
worksheet.set_column('A:I',15,cell_format)
for colx,value in enumerate(df.columns.values):
worksheet.write(0,colx,value,header_format)
writer.save()
formatExcel(pd.read_excel(path_out),path_out)
print ('Done!')
该段重点:
a、对序号列重新赋值新的数字,df[‘序号’].at[i]=i+1;
b、定义单元格(cell)格式;
c、定义列头的格式,通过worksheet.write的方式;
生成的新表:

- 作者推荐:用 Python 替代Excel 表格,轻而易举实现办公自动化
- [办公自动化] 再读《让EXCEL飞》(从excel导入access数据时,union联合查询,数据源中没有包含可见的表格)
- 用Python代码连接并控制Excel表格,从此办公自动化,解放你双手
- python数据分析&自动化办公实战(二):批量输入输出excel文件
- 【python办公自动化(6期)】6.python打开及读取Excel表格内容
- 基于python实现自动化办公学习笔记(CSV、word、Excel、PPT)
- 在python中使用openpyxl和xlrd创建一个新Excel并把原表格数据复制到新表中
- python读取mongoDB数据并存入本地excel表格
- python初学者学习笔记(三)读取excel表格数据
- python openpyxl 读取Excel,超简单案例python openpyxl 获取表格数据
- [办公自动化]如何让excel图表标签中显示最新值数据
- python 中Arduino串口传输数据到电脑并保存至excel表格
- [转] Windows下使用Python读取Excel表格数据
- Python获取excel表格数据例子
- Selenium2+python自动化之读取Excel数据(xlrd)
- 用python抓取表格数据并导出到excel文件中
- 【python办公自动化(6期)】9.向Excel文件中插入图片、生成柱状图、折线图和饼图
- 用python实现多嵌套json数据存入excel表格——以美食数据为例
- 【python办公自动化(6期)】8.批量处理调整Excel内容