kubernetes 部署Prometheus
2020-04-02 19:31
441 查看
kubernetes 部署Prometheus
标签(空格分隔): kubernetes系列
一: 组件说明
二: Prometheus的部署
- 三: HPA 资源限制
一: 组件说明
1.1 相关地址信息
Prometheus github 地址:https://github.com/coreos/kube-prometheus
1.2 组件说明
1.MetricServer:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如 kubectl,hpa,scheduler等。 2.PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。 3.NodeExporter:用于各node的关键度量指标状态数据。 4.KubeStateMetrics:收集kubernetes集群内资源对象数据,制定告警规则。 5.Prometheus:采用pull方式收集apiserver,scheduler,controller-manager,kubelet组件数据,通过http协议传输。 6.Grafana:是可视化数据统计和监控平台。
二: Prometheus的部署
mkdir Prometheus cd Prometheus git clone https://github.com/coreos/kube-prometheus.git

cd /root/kube-prometheus/manifests 修改 grafana-service.yaml 文件,使用 nodeport 方式访问 grafana: vim grafana-service.yaml --- apiVersion: v1 kind: Service metadata: labels: app: grafana name: grafana namespace: monitoring spec: type: NodePort ports: - name: http port: 3000 targetPort: http nodePort: 30100 selector: app: grafana --- 修改 prometheus-service.yaml,改为 nodepode vim prometheus-service.yaml ----- apiVersion: v1 kind: Service metadata: labels: prometheus: k8s name: prometheus-k8s namespace: monitoring spec: type: NodePort ports: - name: web port: 9090 targetPort: web nodePort: 30200 selector: app: prometheus prometheus: k8s sessionAffinity: ClientIP ---- 修改 alertmanager-service.yaml,改为 nodeport vim alertmanager-service.yaml --- apiVersion: v1 kind: Service metadata: labels: alertmanager: main name: alertmanager-main namespace: monitoring spec: type: NodePort ports: - name: web port: 9093 targetPort: web nodePort: 30300 selector: alertmanager: main app: alertmanager sessionAffinity: ClientIP ---
导入镜像处理(节点全部导入) 上传 load-images.sh prometheus.tar.gz 到 /root tar -zxvf prometheus.tar.gz chmod +x load-images.sh ./load-images.sh
kubectl apply -f kube-prometheus/manifests/ 连续执行两次: 第一次会报错 kubectl apply -f kube-prometheus/manifests/
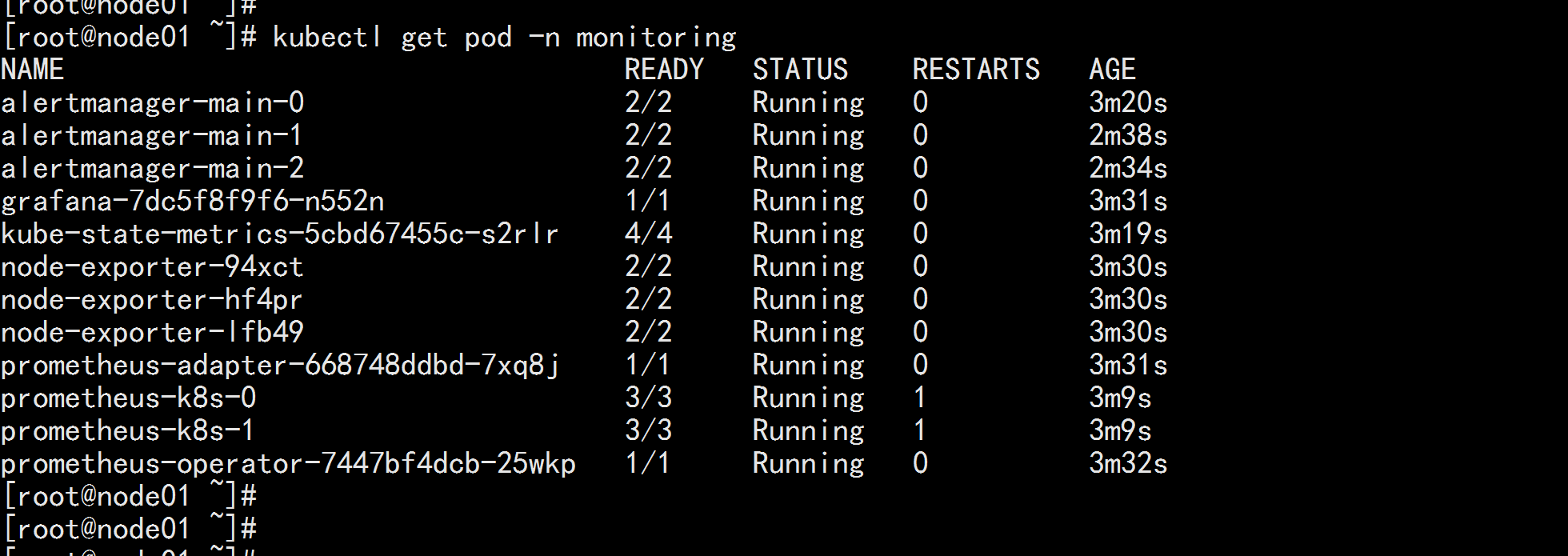
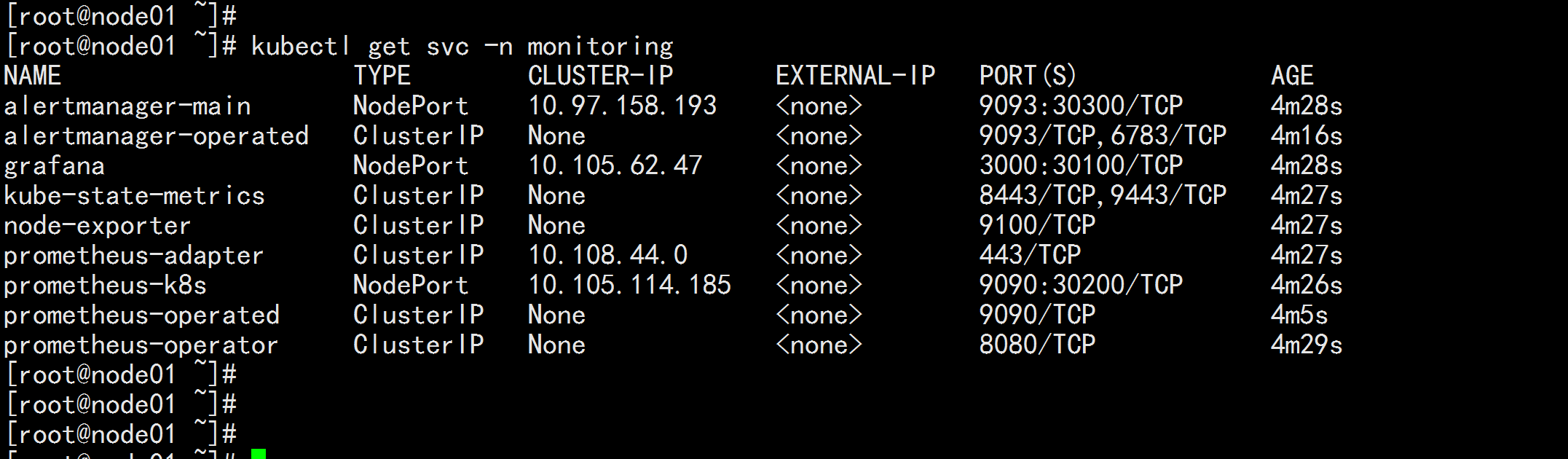
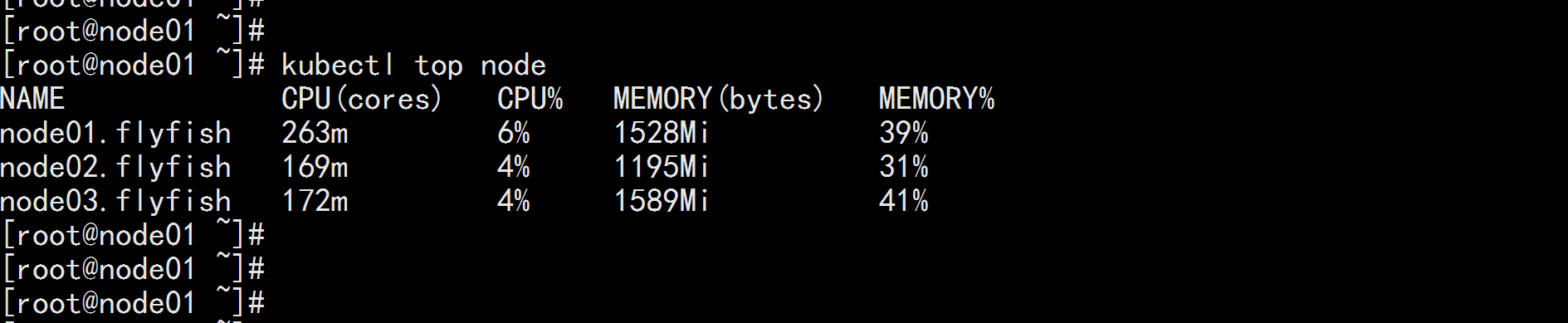
kubectl get pod -n monitoring kubectl get svc -n monitoring kubectl top node
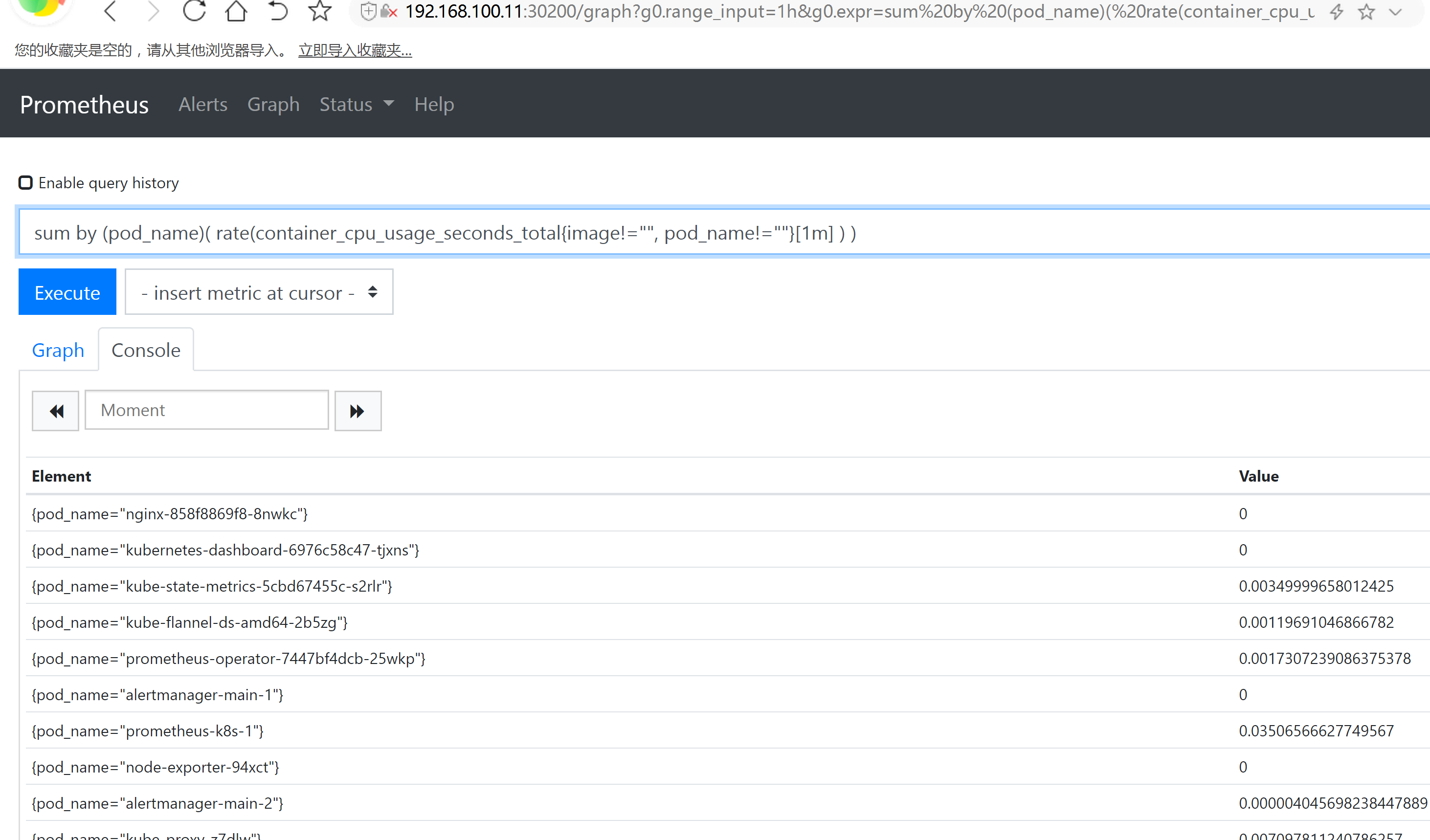
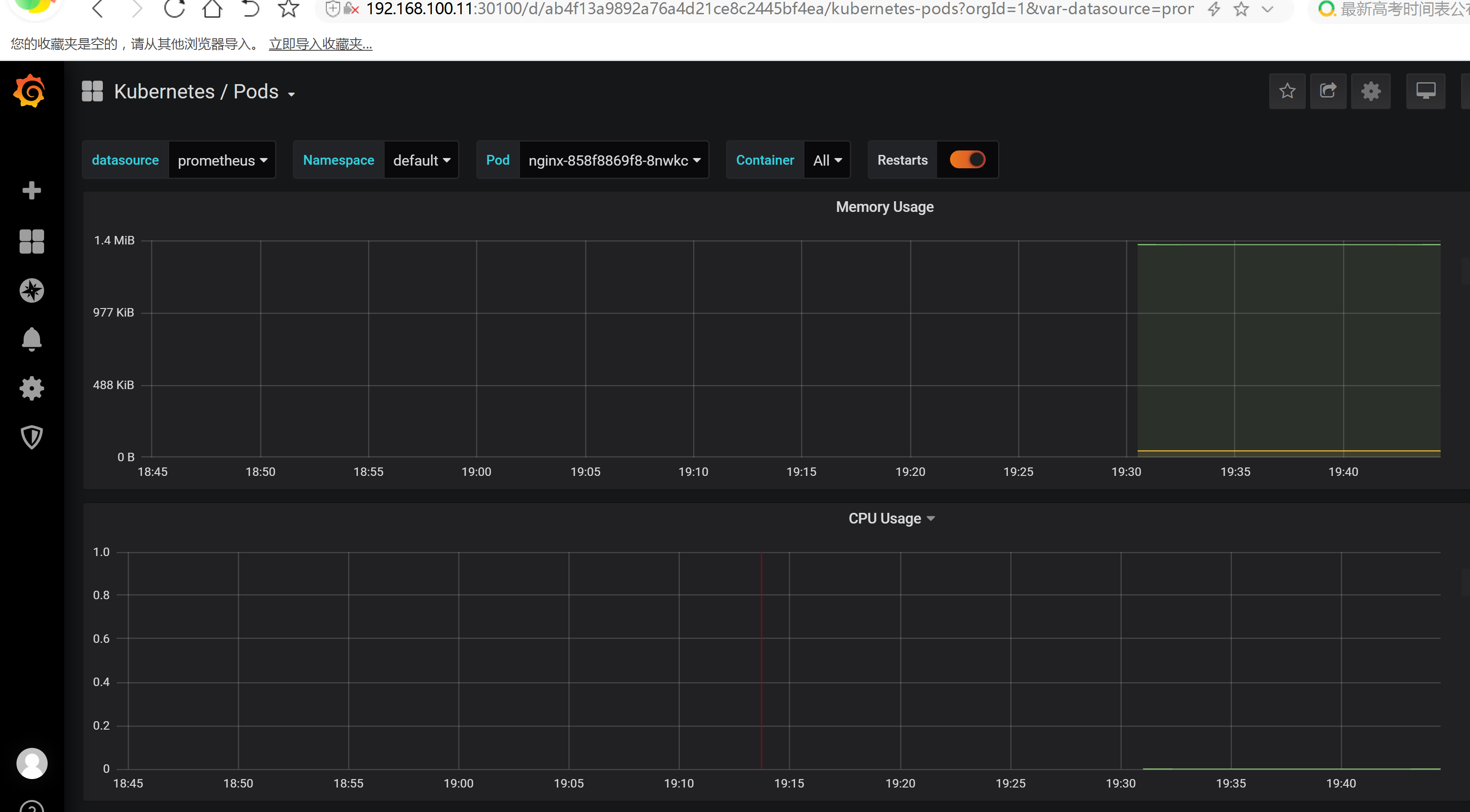
prometheus 对应的 nodeport 端口为 30200,访问 http://MasterIP:30200 http://192.168.100.11:30200/graph
prometheus 的 WEB 界面上提供了基本的查询 K8S 集群中每个 POD 的 CPU 使用情况,查询条件如下:
sum by (pod_name)( rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m] ) )
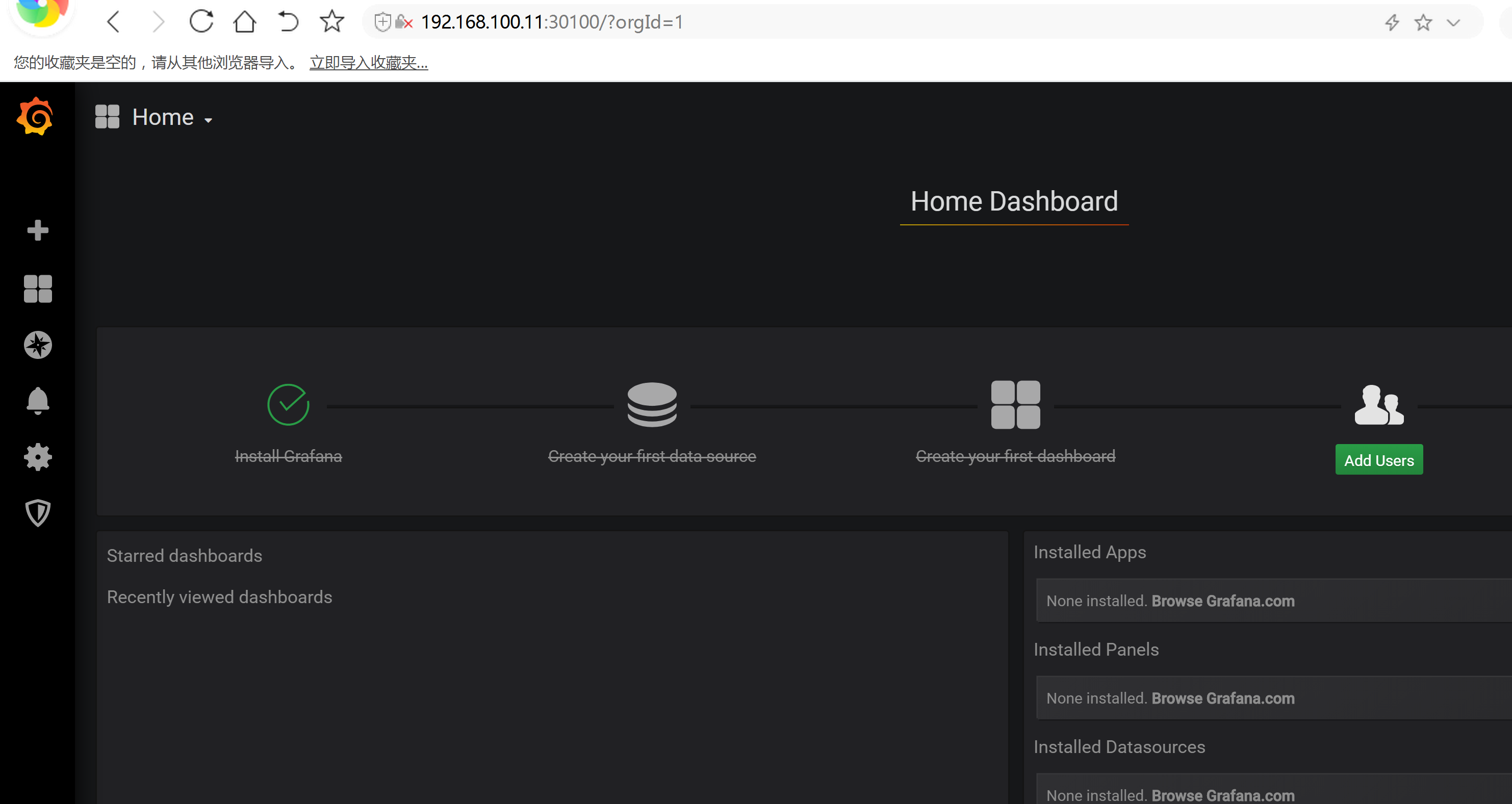
查看 grafana 服务暴露的端口号: kubectl get service -n monitoring | grep grafana grafana NodePort 10.107.56.143 <none> 3000:30100/TCP 20h

默认的用户名与 密码 都是admin 然后从新修改密码即可
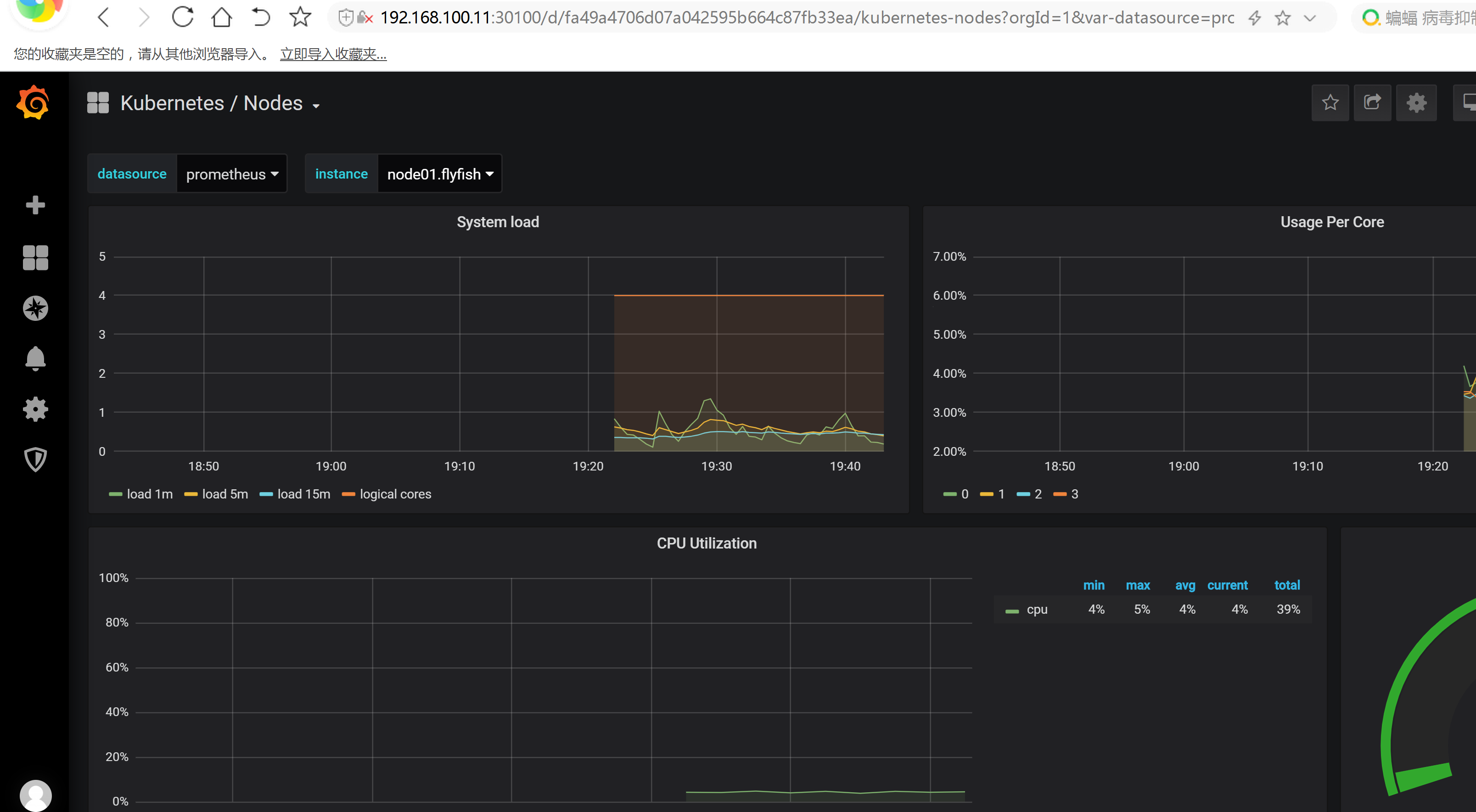
三:HPA 的资源限制
上传hpa-example.tar 然后导入 (所有节点) docker load -i hpa-example.tar
3.1 Horizontal Pod Autoscaling
Horizontal Pod Autoscaling 可以根据 CPU 利用率自动伸缩一个 Replication Controller、Deployment 或者Replica Set 中的 Pod 数量 kubectl run php-apache --image=gcr.io/google_containers/hpa-example --requests=cpu=200m --expose --port=80

kubectl get deploy kubectl edit deploy php-apache ---- 修改: imagePullPolicy: Always 改为 imagePullPolicy: IfNotPresent ---- kubectl get pod

创建 HPA 控制器 kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10 kubectl top pod

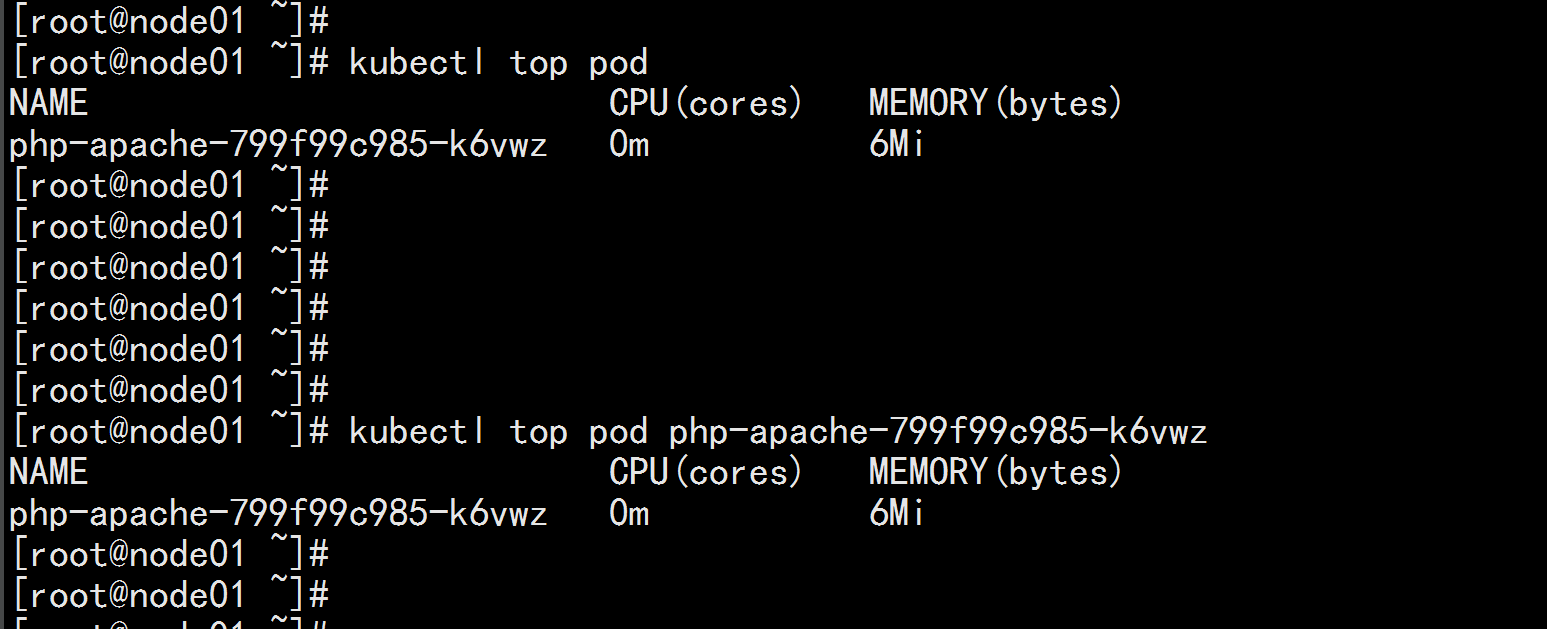

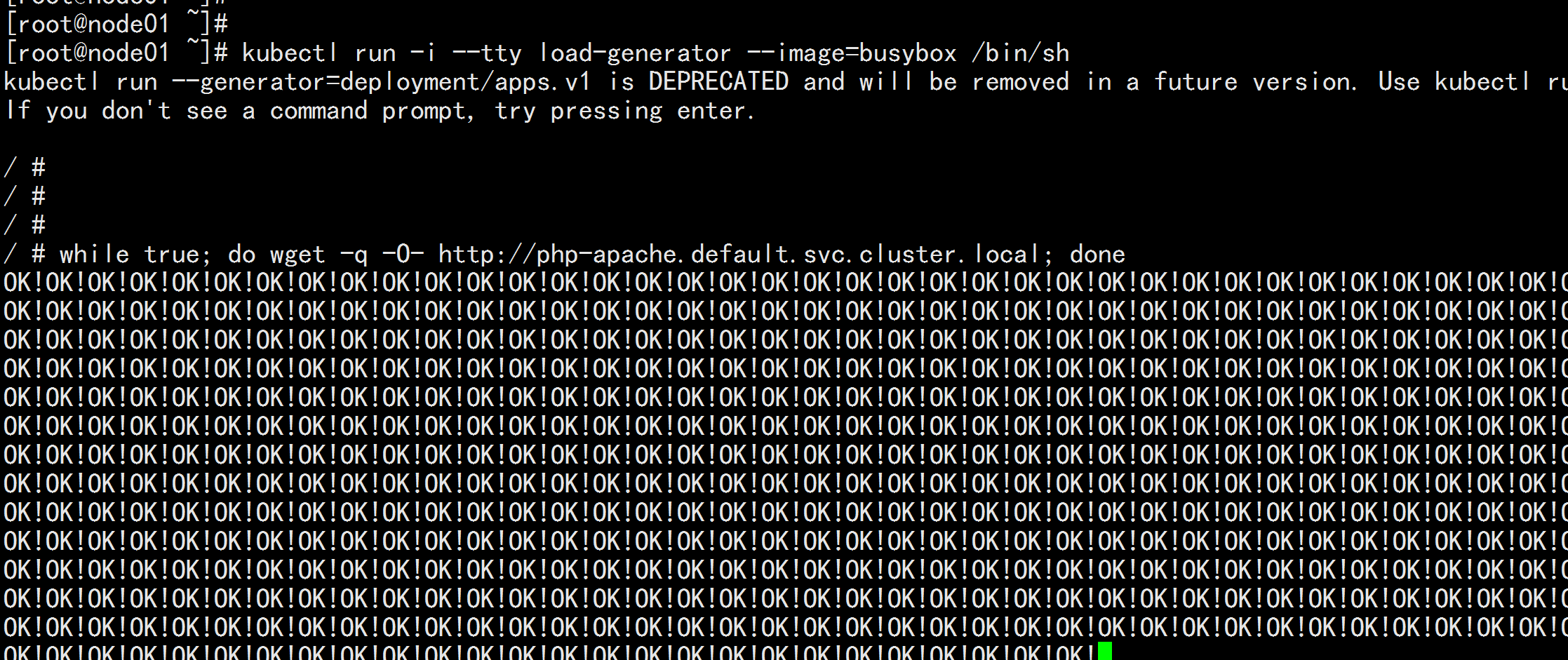
增加负载,查看负载节点数目 kubectl run -i --tty load-generator --image=busybox /bin/sh while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
pod 开始扩展 kubectl get hpa kubectl get pod
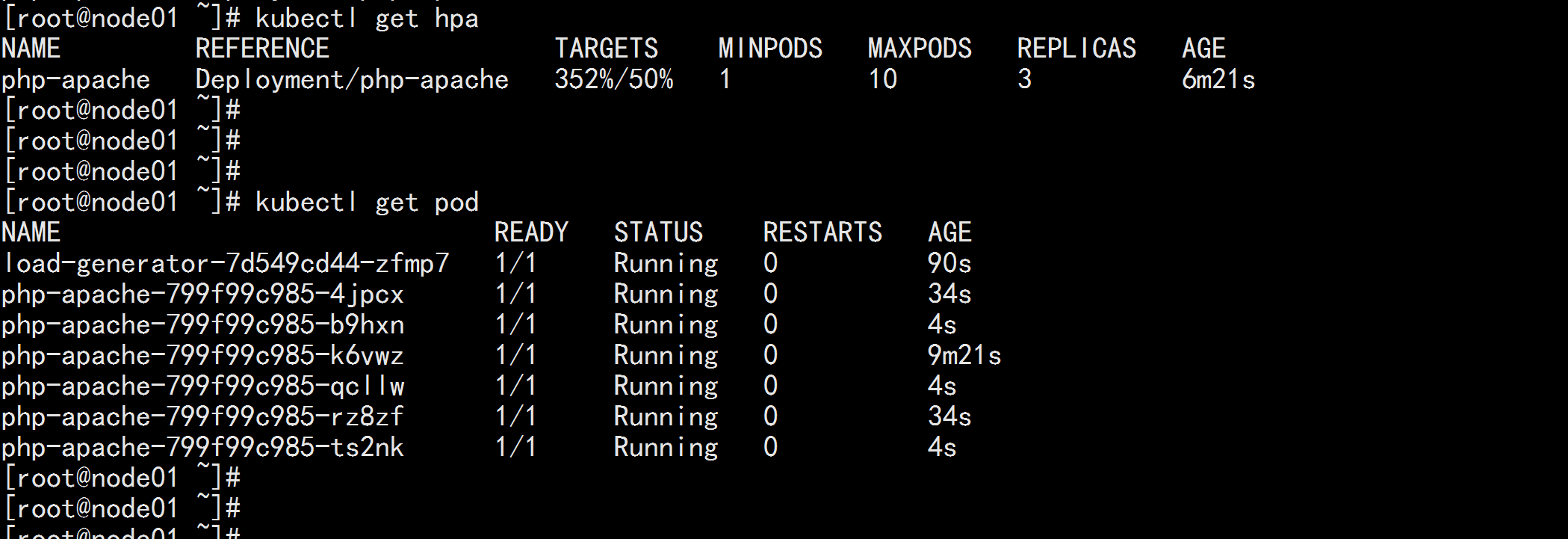
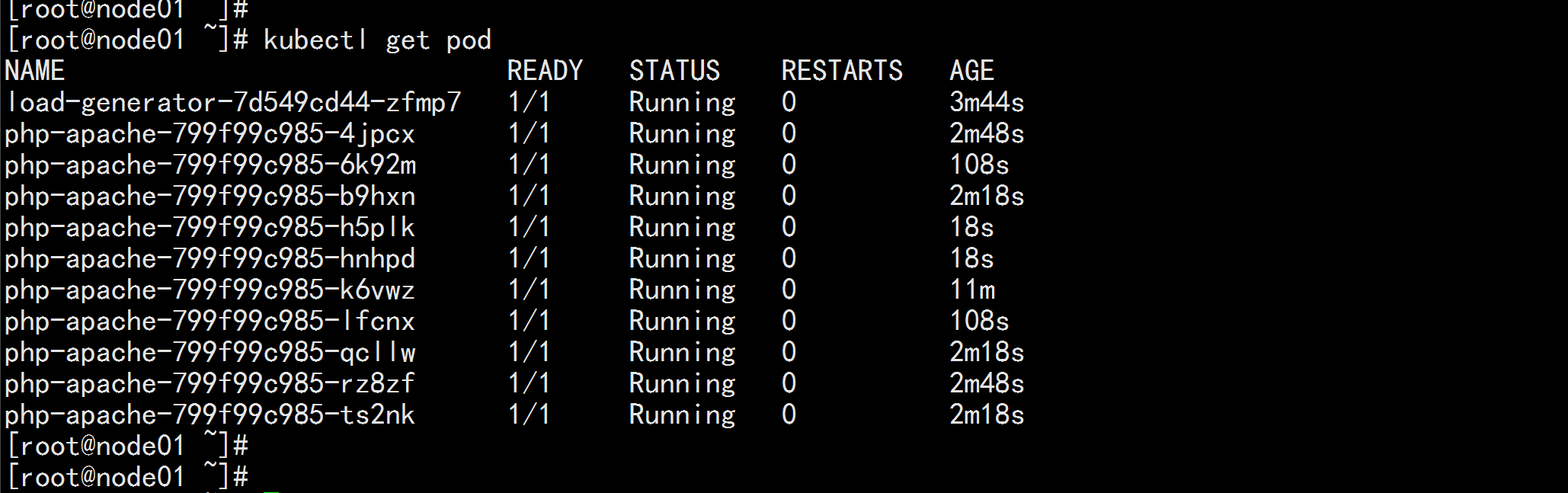

kubernetes 回收的速度比较慢(非常慢) 这是因为并发的问题,一单有 大流量过来,如果回收的速度比较快,很容易将某一个pod给压死
3.2 k8s 的资源限制
资源限制 - Pod Kubernetes 对资源的限制实际上是通过 cgroup 来控制的,cgroup 是容器的一组用来控制内核如何运行进程的 相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup 默认情况下,Pod 运行没有 CPU 和内存的限额。 这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一 样,消耗足够多的 CPU 和内存 。一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过 resources 的 requests 和 limits 来实现 --- spec: containers: - image: xxxx imagePullPolicy: Always name: auth ports: - containerPort: 8080 protocol: TCP resources: limits: cpu: "4" memory: 2Gi requests: cpu: 250m memory: 250Mi ---- requests 要分分配的资源,limits 为最高请求的资源值。可以简单理解为初始值和最大值
资源限制 - 名称空间 1、计算资源配额 apiVersion: v1 kind: ResourceQuota metadata: name: compute-resources namespace: spark-cluster spec: hard: pods: "20" requests.cpu: "20" requests.memory: 100Gi limits.cpu: "40" limits.memory: 200Gi
2. 配置对象数量配额限制 apiVersion: v1 kind: ResourceQuota metadata: name: object-counts namespace: spark-cluster spec: hard: configmaps: "10" persistentvolumeclaims: "4" replicationcontrollers: "20" secrets: "10" services: "10" services.loadbalancers: "2"
3. 配置 CPU 和 内存 LimitRange apiVersion: v1 kind: LimitRange metadata: name: mem-limit-range spec: limits: - default: memory: 50Gi cpu: 5 defaultRequest: memory: 1Gi cpu: 1 type: Container ---- default 即 limit 的值 defaultRequest 即 request 的值

相关文章推荐
- Kubernetes 系列(六):Kubernetes部署Prometheus监控
- kubernetes上用helm部署loki prometheus grafana
- Kubernetes 1.6 部署prometheus和grafana(数据持久)
- Kubernetes集群部署史上最详细(二)Prometheus监控Kubernetes集群
- 一文读懂如何在 Kubernetes 上轻松实现自动化部署 Prometheus
- kubernetes实战(二十):k8s一键部署高可用Prometheus并实现邮件告警
- 使用Helm部署Prometheus和Grafana监控Kubernetes
- Kubernetes 实战教学,手把手教您用 Helm 在 K8s 平台上部署 Prometheus
- Kubernetes 部署 Nebula 图数据库集群
- kubernetes-helm部署及本地repo搭建
- kubernetes集群-----二进制部署详解(二)
- 在centos7上部署kubernetes
- 落地案例|使用 Kubernetes 重新部署全球最大的教育公司
- 在Kubernetes上部署和伸缩Jenkins
- Prometheus全方位监控K8S集群,部署太简单了!
- 【kubernetes/k8s 部署】minikube 与 kubernetes 搭建
- Kubernetes集群的安装部署
- 阿里云容器服务-高可用Kubernetes部署指南
- kubernetes实战(十三):k8s使用helm持久化部署harbor集成openLDAP登录
- 用Kubernetes部署超级账本Fabric的区块链即服务(3)