【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——Python 中的广播、关于 python中numpy 向量的说明
文章目录
- 2.15 Python 中的广播(Broadcasting in Python)
- 2.16 关于 python _ numpy 向量的说明(A note on python or numpy vectors)
2.15 Python 中的广播(Broadcasting in Python)
这是一个不同食物(每100g)中不同营养成分的卡路里含量表格,表格为3行4列,列表示不同的食物种类,从左至右依次为苹果,牛肉,鸡蛋,土豆。行表示不同的营养成分,从上到下依次为碳水化合物,蛋白质,脂肪。
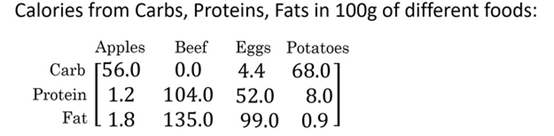
那么,我们现在想要计算不同食物中不同营养成分中的卡路里百分比。
现在计算苹果中的碳水化合物卡路里百分比含量,首先计算苹果(100g)中三种营养成分卡路里总和56+1.2+1.8 = 59,然后用56/59 = 94.9%算出结果。
可以看出苹果中的卡路里大部分来自于碳水化合物,而牛肉则不同。
对于其他食物,计算方法类似。首先,按列求和,计算每种食物中(100g)三种营养成分总和,然后分别用不用营养成分的卡路里数量除以总和,计算百分比。
那么,能否不使用for循环完成这样的一个计算过程呢?
假设上图的表格是一个3行4列的矩阵A,记为 A_(3×4),接下来我们要使用Python的numpy库完成这样的计算。我们打算使用两行代码完成,第一行代码对每一列进行求和,第二行代码分别计算每种食物每种营养成分的百分比。
在jupyter notebook中输入如下代码,按shift+Enter运行,输出如下。

下面使用如下代码计算每列的和,可以看到输出是每种食物(100g)的卡路里总和。

其中sum的参数axis=0表示求和运算按列执行,之后会详细解释。
接下来计算百分比,这条指令将 3×4的矩阵A除以一个1×4的矩阵,得到了一个 3×4的结果矩阵,这个结果矩阵就是我们要求的百分比含量。
 算是沿着哪个轴执行,在numpy中,0轴是垂直的,也就是列,而1轴是水平的,也就是行。
算是沿着哪个轴执行,在numpy中,0轴是垂直的,也就是列,而1轴是水平的,也就是行。
而第二个A/cal.reshape(1,4)指令则调用了numpy中的广播机制。这里使用 3×4的矩阵A除以 1×4的矩阵cal。技术上来讲,其实并不需要再将矩阵cal reshape(重塑)成 1×4,因为矩阵cal本身已经是 1×4了。但是当我们写代码时不确定矩阵维度的时候,通常会对矩阵进行重塑来确保得到我们想要的列向量或行向量。重塑操作reshape是一个常量时间的操作,时间复杂度是O(1),它的调用代价极低。
那么一个 3×4 的矩阵是怎么和 1×4的矩阵做除法的呢?让我们来看一些更多的广播的例子。
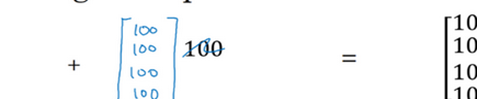
在numpy中,当一个 4×1的列向量与一个常数做加法时,实际上会将常数扩展为一个 4×1的列向量,然后两者做逐元素加法。结果就是右边的这个向量。这种广播机制对于行向量和列向量均可以使用。
再看下一个例子。

用一个 2×3的矩阵和一个 1×3 的矩阵相加,其泛化形式是 m×n 的矩阵和 1×n的矩阵相加。在执行加法操作时,其实是将 1×n 的矩阵复制成为 m×n 的矩阵,然后两者做逐元素加法得到结果。针对这个具体例子,相当于在矩阵的第一列加100,第二列加200,第三列加300。这就是在前一张幻灯片中计算卡路里百分比的广播机制,只不过这里是除法操作(广播机制与执行的运算种类无关)。
下面是最后一个例子
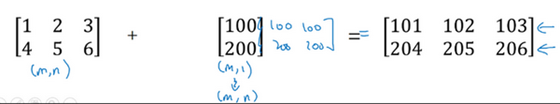
这里相当于是一个 m×n 的矩阵加上一个 m×1 的矩阵。在进行运算时,会先将 m×1 矩阵水平复制 n 次,变成一个 m×n 的矩阵,然后再执行逐元素加法。
广播机制的一般原则如下:

这里我先说一下我本人对numpy广播机制的理解,再解释上面这张幻灯片。
首先是numpy广播机制

现在解释上图中的例子

最后,对于Matlab/Octave 有类似功能的函数bsxfun。
总结一下broadcasting,可以看看下面的图:

2.16 关于 python _ numpy 向量的说明(A note on python or numpy vectors)
本节主要讲Python中的numpy一维数组的特性,以及与行向量或列向量的区别。并介绍了老师在实际应用中的一些小技巧,去避免在coding中由于这些特性而导致的bug。
Python的特性允许你使用广播(broadcasting)功能,这是Python的numpy程序语言库中最灵活的地方。而我认为这是程序语言的优点,也是缺点。优点的原因在于它们创造出语言的表达性,Python语言巨大的灵活性使得你仅仅通过一行代码就能做很多事情。但是这也是缺点,由于广播巨大的灵活性,有时候你对于广播的特点以及广播的工作原理这些细节不熟悉的话,你可能会产生很细微或者看起来很奇怪的bug。例如,如果你将一个列向量添加到一个行向量中,你会以为它报出维度不匹配或类型错误之类的错误,但是实际上你会得到一个行向量和列向量的求和。
在Python的这些奇怪的影响之中,其实是有一个内在的逻辑关系的。但是如果对Python不熟悉的话,我就曾经见过的一些学生非常生硬、非常艰难地去寻找bug。所以我在这里想做的就是分享给你们一些技巧,这些技巧对我非常有用,它们能消除或者简化我的代码中所有看起来很奇怪的bug。同时我也希望通过这些技巧,你也能更容易地写没有bug的Python和numpy代码。
为了演示Python-numpy的一个容易被忽略的效果,特别是怎样在Python-numpy中构造向量,让我来做一个快速示范。首先设置a=np.random.randn(5),这样会生成存储在数组 a 中的5个高斯随机数变量。之后输出 a,从屏幕上可以得知,此时 a 的shape(形状)是一个(5,)的结构。这在Python中被称作一个一维数组。它既不是一个行向量也不是一个列向量,这也导致它有一些不是很直观的效果。举个例子,如果我输出一个转置阵,最终结果它会和a看起来一样,所以a和a的转置阵最终结果看起来一样。而如果我输出a和a的转置阵的内积,你可能会想:a乘以a的转置返回给你的可能会是一个矩阵。但是如果我这样做,你只会得到一个数。

所以我建议当你编写神经网络时,不要在它的shape是(5,)还是(n,)或者一维数组时使用数据结构。相反,如果你设置 a 为(5,1),那么这就将置于5行1列向量中。在先前的操作里 a 和 a 的转置看起来一样,而现在这样的 a 变成一个新的 a 的转置,并且它是一个行向量。请注意一个细微的差别,在这种数据结构中,当我们输出 a 的转置时有两对方括号,而之前只有一对方括号,所以这就是1行5列的矩阵和一维数组的差别。

如果你输出 a 和 a 的转置的乘积,然后会返回给你一个向量的外积,是吧?所以这两个向量的外积返回给你的是一个矩阵。
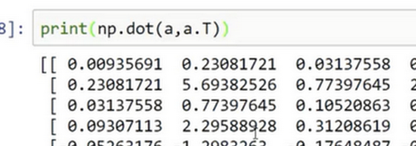

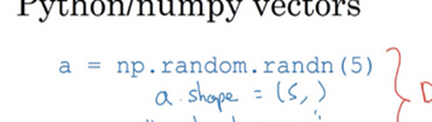


我有时候看见学生因为一维数组不直观的影响,难以定位bug而告终。通过在原先的代码里清除一维数组,我的代码变得更加简洁。而且实际上就我在代码中表现的事情而言,我从来不使用一维数组。因此,要去简化你的代码,而且不要使用一维数组。总是使用 n×1 维矩阵(基本上是列向量),或者 1×n 维矩阵(基本上是行向量),这样你可以减少很多assert语句来节省核矩阵和数组的维数的时间。另外,为了确保你的矩阵或向量所需要的维数时,不要羞于 reshape 操作。
总之,我希望这些建议能帮助你解决一个Python中的bug,从而使你更容易地完成练习。
- 点赞
- 收藏
- 分享
- 文章举报
 汪雯琦
发布了854 篇原创文章 · 获赞 1192 · 访问量 15万+
私信
关注
汪雯琦
发布了854 篇原创文章 · 获赞 1192 · 访问量 15万+
私信
关注

- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——logistic 损失函数的解释(Explanation of logistic
- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)—— Jupyter/iPython Notebooks快速入门(Quick tou
- 神经网络编程基础(Basics Of Neural Network Programming)
- Coursera 深度学习 deep learning.ai 吴恩达 神经网络和深度学习 第一课 第二周 编程作业 Python Basics with Numpy
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第二周课后习题 Neural Network Basics Quiz, 10 questions
- Coursera deep learning 吴恩达 神经网络和深度学习 第二周 编程作业 Logistic Regression with a Neural Network mindset
- 【吴恩达深度学习专栏】浅层神经网络(Shallow neural networks)——神经网络的表示(Neural Network Representation)
- 【吴恩达深度学习专栏】浅层神经网络(Shallow neural networks)——神经网络概述(Neural Network Overview)
- 【吴恩达深度学习专栏】浅层神经网络(Shallow neural networks)——计算一个神经网络的输出(Computing a Neural Network's output)
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第二周课后习题 Python Basics with numpy (optional)
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第一周课后习题 Neural Network Basics
- Coursera deep learning 吴恩达 神经网络和深度学习 第四周 编程作业 Building your Deep Neural Network
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第二周课后习题 Logistic Regression with a Neural Network mindset
- 神经网络与深度学习第二周-1- Python Basics With Numpy
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第四周课后习题 Deep Neural Network - Application v3
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第四周课后习题 Building your Deep Neural Network - Step by Step v5
- 深度学习与神经网络-吴恩达(Part1Week3)-单隐层神经网络编程实现(python)
- 深度学习与神经网络-吴恩达(Part1Week4)-深度神经网络编程实现(python)-基础篇
- 【吴恩达深度学习专栏】浅层神经网络(Shallow neural networks)——激活函数的导数(Derivatives of activation functions)
- Building your Deep Neural Network - Step by Step v5吴恩达神经网络和深度学习第四周作业解答