【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——m 个样本的梯度下降(Gradient Descent on m Example
2.10 m 个样本的梯度下降(Gradient Descent on m Examples)
在之前的视频中,你已经看到如何计算导数,以及应用梯度下降在逻辑回归的一个训练样本上。现在我们想要把它应用在m个训练样本上。


但之前我们已经演示了如何计算这项,即之前幻灯中演示的如何对单个训练样本进行计算。所以你真正需要做的是计算这些微分,如我们在之前的训练样本上做的。并且求平均,这会给你全局梯度值,你能够把它直接应用到梯度下降算法中。
所以这里有很多细节,但让我们把这些装进一个具体的算法。同时你需要一起应用的就是逻辑回归和梯度下降。
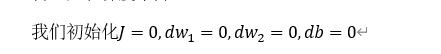
代码流程:
J=0;dw1=0;dw2=0;db=0; for i = 1 to m z(i) = wx(i)+b; a(i) = sigmoid(z(i)); J += -[y(i)log(a(i))+(1-y(i))log(1-a(i)); dz(i) = a(i)-y(i); dw1 += x1(i)dz(i); dw2 += x2(i)dz(i); db += dz(i); J/= m; dw1/= m; dw2/= m; db/= m; w=w-alpha*dw b=b-alpha*db
幻灯片上只应用了一步梯度下降。因此你需要重复以上内容很多次,以应用多次梯度下降。看起来这些细节似乎很复杂,但目前不要担心太多。希望你明白,当你继续尝试并应用这些在编程作业里,所有这些会变的更加清楚。
但这种计算中有两个缺点,也就是说应用此方法在逻辑回归上你需要编写两个for循环。第一个for循环是一个小循环遍历m个训练样本,第二个for循环是一个遍历所有特征的for循环。这个例子中我们只有2个特征,所以n等于2并且n_x 等于2。 但如果你有更多特征,你开始编写你的因此dw_1,dw_2,你有相似的计算从dw_3一直下去到dw_n。所以看来你需要一个for循环遍历所有n个特征。
当你应用深度学习算法,你会发现在代码中显式地使用for循环使你的算法很低效,同时在深度学习领域会有越来越大的数据集。所以能够应用你的算法且没有显式的for循环会是重要的,并且会帮助你适用于更大的数据集。所以这里有一些叫做向量化技术,它可以允许你的代码摆脱这些显式的for循环。
我想在先于深度学习的时代,也就是深度学习兴起之前,向量化是很棒的。可以使你有时候加速你的运算,但有时候也未必能够。但是在深度学习时代向量化,摆脱for循环已经变得相当重要。因为我们越来越多地训练非常大的数据集,因此你真的需要你的代码变得非常高效。所以在接下来的几个视频中,我们会谈到向量化,以及如何应用向量化而连一个for循环都不使用。所以学习了这些,我希望你有关于如何应用逻辑回归,或是用于逻辑回归的梯度下降,事情会变得更加清晰。当你进行编程练习,但在真正做编程练习之前让我们先谈谈向量化。然后你可以应用全部这些东西,应用一个梯度下降的迭代而不使用任何for循环。
- 点赞
- 收藏
- 分享
- 文章举报
 汪雯琦
发布了854 篇原创文章 · 获赞 1192 · 访问量 15万+
私信
关注
汪雯琦
发布了854 篇原创文章 · 获赞 1192 · 访问量 15万+
私信
关注

- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——向量化逻辑回归(Vectorizing Logistic Regression)
- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——向量化(Vectorization)及更多例子
- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——Python 中的广播、关于 python中numpy 向量的说明
- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)——logistic 损失函数的解释(Explanation of logistic
- 【吴恩达深度学习专栏】神经网络的编程基础(Basics of Neural Network programming)—— Jupyter/iPython Notebooks快速入门(Quick tou
- 神经网络编程基础(Basics Of Neural Network Programming)
- 【吴恩达深度学习专栏】浅层神经网络(Shallow neural networks)——神经网络的梯度下降(Gradient descent for neural networks)
- 【吴恩达深度学习专栏】浅层神经网络(Shallow neural networks)——计算一个神经网络的输出(Computing a Neural Network's output)
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第一周课后习题 Neural Network Basics
- 【吴恩达深度学习专栏】浅层神经网络(Shallow neural networks)——神经网络的表示(Neural Network Representation)
- Coursera deep learning 吴恩达 神经网络和深度学习 第二周 编程作业 Logistic Regression with a Neural Network mindset
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第二周课后习题 Neural Network Basics Quiz, 10 questions
- Coursera deep learning 吴恩达 神经网络和深度学习 第四周 编程作业 Building your Deep Neural Network
- 【吴恩达深度学习专栏】浅层神经网络(Shallow neural networks)——神经网络概述(Neural Network Overview)
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第四周课后习题 Deep Neural Network - Application v3
- Building your Deep Neural Network - Step by Step v5吴恩达神经网络和深度学习第四周作业解答
- 【吴恩达深度学习专栏】浅层神经网络(Shallow neural networks)——激活函数的导数(Derivatives of activation functions)
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第四周课后习题 Building your Deep Neural Network - Step by Step v5
- 神经网络和深度学习-第二周神经网络基础-第四节:梯度下降法
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第二周课后习题 Logistic Regression with a Neural Network mindset