基于Adaboost的短期择时模型研究 - 知乎
https://zhuanlan.zhihu.com/p/105062059
首发于 优矿金工 2020-01-21
A. 研究目的:本文利用优矿提供的行情数据、宏观行业数据、个股因子数据等,参考兴业证券《系统化资产配置系列之三:基于AdaBoost机器学习算法的市场短期择时策略》(原作者:于明明等)的方法,挑选了一批因子,并分别用CART决策树模型、AdaBoost等机器学习模型进行市场短期择时的研究,探究用机器学习模型来解决因子筛选时的非线性、相关性等一系列传统择时模型遇到的难点问题的效果,以及不同机器学习模型的表现差异。
B. 研究结论:
- 在不考虑手续费的理想条件下,利用CART决策树模型对通联全A指数在201410月到2019年12月中进行日度择时,纯做多时可获得10.2%的年化收益,日度胜率达到了57%,最大回撤为27.2%;纯做空时获得-1.8%的年化收益,日度胜率为47.8%,最大回撤为28.8%;而如果构造多空的择时模型,可获得8.3%的年化收益,胜率为52.3%,最大回撤为27.1%,对应纯持有全A指数的年化收益为8.9%,最大回撤为49%。CART择时模型在进行做多择时上表现相比做空预测更好,但并未明显超过基准;
- 进一步,利用adaboost模型对通联全A指数在201410月到2019年12月中进行日度择时,纯做多时可获得12%的年化收益,日度胜率达到了55.8%,最大回撤为23.4%;纯做空时获得4.9%的年化收益,日度胜率为47.6%,最大回撤为24.2%;而如果构造多空的择时模型,可获得22.7%的年化收益,胜率为52.8%,最大回撤为27.5%;
- 从收益、最大回撤等性能指标来看,adaboost模型无论是在做多择时还是做空择时上,都相比CART模型有更好的表现,远超过基准(持有不动)的表现
C. 文章结构:本文共分为4个部分,具体如下
- 一、指标数据的获取和计算。
- 二、利用CART决策树模型进行择时。
- 三、利用AdaBoost模型进行择时。
- 四、总结。
D. 时间说明
- 一、第一部分运行需要5分钟
- 二、第二部分运行需要10分钟
- 三、第三部分运行需要20分钟
- 四、第三部分运行需要1分钟
- 总耗时35分钟左右

第一部分:指标数据的获取和计算
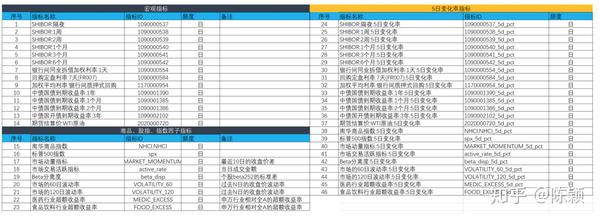
该部分总共计算了46个指标从 <data_start_date> 到 <data_end_date> 之间的每日值,具体内容为:
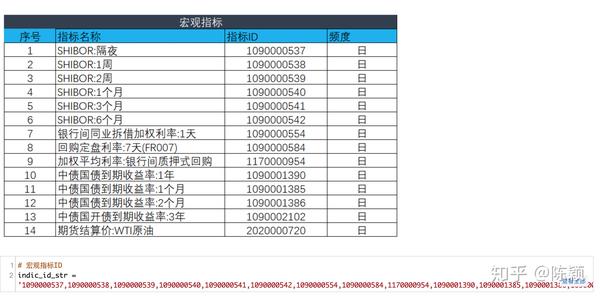
- 1.1 取14个宏观指标
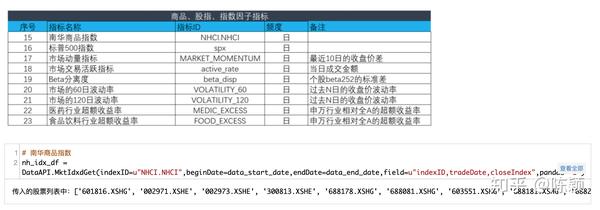
- 1.2 计算9个商品、股指、指数因子指标
- 1.3 计算23个指标的5日变化率指标
所有指标列表汇总如下:
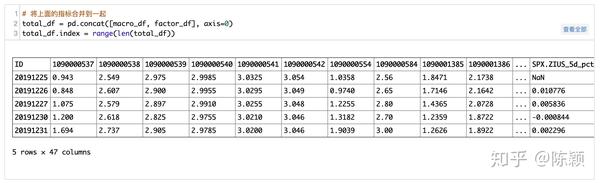
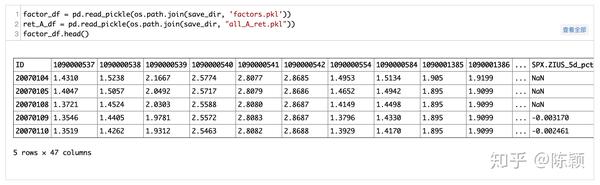
计算后的指标数据存储在<save_dir>/factor.pkl中,样式具体如下:

1.1 取14个宏观指标
1.2 计算商品、股指、指数因子指标
1.3 计算指标的过去5日变化率
对上面计算的指标,每个都计算一个5日变化率的值,得到23个新的指标,计算公式和指标明细如下:
5日变化率指标=[value(t)−value(t−5)]/value(t−5),其中,value(t)为指标在t日的值

第二部分:利用CART决策树模型进行择时
该部分实现了CART决策树的择时模型,具体包括以下部分内容:
- 2.1 CART决策树理论介绍
- 2.2 模型训练和预测机制说明
- 2.3 CART决策树的实现代码
- 2.4 CART决策树的择时效果
2.1 CART决策树理论介绍
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树状结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布,其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。建立决策树在决定先用哪些指标进行分叉时,有很多种算法,CART是其中最著名的算法之一,其算法逻辑如下所示:

参考资料:
- https://zhuanlan.zhihu.com/p/32053821
- 李航,《统计学习方法》
2.2 模型训练和预测机制说明
参考 兴业证券《系统化资产配置系列之三:基于AdaBoost机器学习算法的市场短期择时策略》 中的方法,利用CART模型对通联全A指数进行日度择时,在每个月月底进行一次模型更新,意味着在每个月的月初到月末中,CART决策树模型是不变的,每天不同的输入产生对下一个交易日的不同预测结果,具体为:

- 在每个月(T月)的最后一个交易日M日,利用M-1日及之前的所有历史数据,训练得到一个新的决策树模型Model(T+1)
- 对于T+1月中的每一个交易日,将当日的指标值(特征值)输入到Model(T+1)中,得到对下一个交易日的涨跌预测
- 为了保证有足够多的历史数据进行训练,从20141027日开始预测,每个训练模型至少用到了20070601到20141027之间的数据进行训练
- 指标值中的缺失值统一用100000代替,这样既保留了缺失这一个特征状态,也不影响模型的正常运算
2.3 CART决策树的实现代码
CART决策树的超参数有很多个,其中最重要的是不纯度的度量方法(信息熵或者是基尼系数),以及所允许的最大决策树深度,为了得到更好的效果,下文使用了GridSearchCV来搜寻最佳的超参数,具体为:

- 所有参数中,选择在5层训练集的交叉验证中,得分函数值(准确率)最高的一组
- 事先定义了超参数的取值范围, 不纯度的度量方法取值为[信息熵, 基尼系数]之一,而最大的决策树深度为[5, 15, 20, 25, 30]之一
2.4 CART决策树的择时效果
遍历20141028到20191231的每一个交易日,对下一个交易日的涨跌进行预测,并将结果存储在predict_df中,其样式如下所示


根据模型择时结果,画出策略收益图
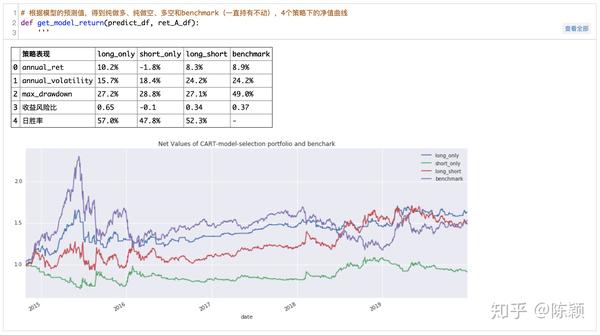
从上面的结果可以看出,CART决策树在进行做多预测时,有不错的表现,纯做多时可获得10.2%的年化收益,日度胜率达到了57%,最大回撤为27.2%;纯做空时获得-1.8%的年化收益,日度胜率为47.8%,最大回撤为28.8%;而如果构造多空的择时模型,可获得8.3%的年化收益,胜率为52.3%,最大回撤为27.1%,对应纯持有全A指数的年化收益为8.9%,最大回撤为49%。CART择时模型在进行做多择时上表现相比做空预测更好,但并未明显超过基准,如果考虑实际操作时的手续费,用该择时模型并不能取得超额收益,原因可能有以下几个方面:
- 模型训练时候发生了过拟合,在样本内表现很好,但是样本外预测的泛化能力很差,这种情况可以通过分析样本内外的准确率等指标进行简单判断;
- 所选用的指标本身效果不行
- 机器学习模型并不适用等
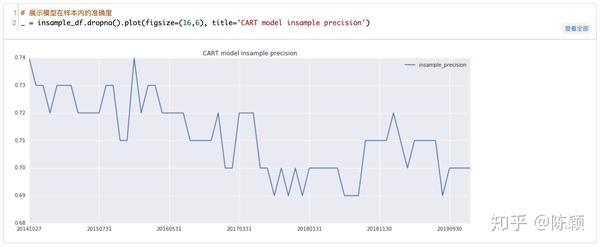
下图展示了所用的CART模型在样本内的准确率,大概在71%左右,而根据上面的结果可知,在样本外预测准确率在50%左右,总体来看样本外的准确率有所下降,但是下降的并不是非常的极端,因此出了原因1,原因2和3也是需要进行深入研究的,有兴趣的读者可以将决策树图画出来进行详细的分析
第三部分:利用AdaBoost模型进行择时
该部分实现了CART决策树的择时模型,具体包括以下部分内容:
- 3.1 AdaBoost模型理论介绍
- 3.2 模型训练和预测机制说明
- 3.3 AdaBoost模型的实现代码
- 3.4 AdaBoost模型的择时效果
3.1 AdaBoost模型理论介绍
Adaboost全称为adaptive boosting,是提升模型(Boosting)的一种变形,提升方法是指:分类问题中,通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类器的性能。模型的示意图如下所示:

其中的基分类器一般选择CART模型,明显可以看出AdaBoost是一个包含了多个基分类器的集成模型,在进行训练时候,不同基分类器的目标不一样,后一个的分类器主要针对前一个分类器的缺点(训练集中误差较大样本)进行性能弥补,表现方式为相对于前一个分类器,后一个分类器训练时,前者误差较大的样本权重会更大,最后把多个分类器的结果等权在一起考虑得到了最终的预测结果,关于AdaBoost过程的详细理论推导,处于篇幅原因本文不进行详细描述,可以参考下面的学习资料:
3.2 模型训练和预测机制说明
该部分的模型训练和预测机制同2.2一样,如下所示:
在每个月(T月)的最后一个交易日M日,利用M-1日及之前的所有历史数据,训练得到一个新的AdaBoost模型Model(T+1)
- 对于T+1月中的每一个交易日,将当日的指标值(特征值)输入到Model(T+1)中,得到对下一个交易日的涨跌预测
- 为了保证有足够多的历史数据进行训练,从20141027日开始预测,每个训练模型至少用到了20070601到20141027之间的数据进行训练
- 指标值中的缺失值统一用100000代替,这样既保留了缺失这一个特征状态,也不影响模型的正常运算
3.3 AdaBoost模型的实现代码
AdaBoost模型同样有很多个超参数,除了基分类器中的不纯度的度量方法,基分类器的个数也是很重要的参数,此外基分类器的最大深度理论上也是很重要的参数,但是参考研报中的做法,设定好最大深度为1,因此不需要进行调仓。在使用了GridSearchCV进行调优超参数时,对于AdaBoost中基分类器的参数用"__"表示

3.4 AdaBoost模型的择时效果

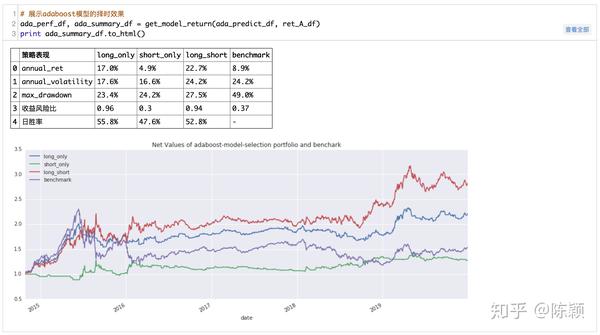
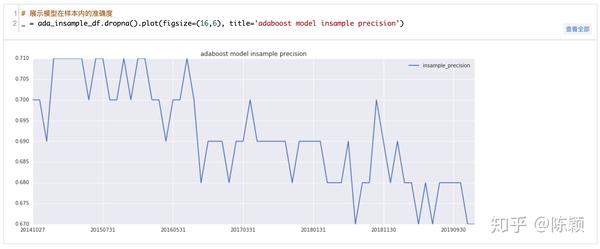
从上面的结果可以看出,纯做多时可获得12%的年化收益,日度胜率达到了55.8%,最大回撤为23.4%;纯做空时获得4.9%的年化收益,日度胜率为47.6%,最大回撤为24.2%;而如果构造多空的择时模型,可获得22.7%的年化收益,胜率为52.8%,最大回撤为27.5%,远超过CART模型的表现以及计准的表现,说明AdaBoost在进行短期择时上可以取得很好的效果。下图进一步分析了模型在样本内和样本外的准确性,可以看出在样本内的准确度为69%左右,上面的回测结果显示样本外的胜率为52%,样本外的准确性相比样本内下降的水平同第二章的CART接近,因此也说明CART表现不好,本身模型适用情况的关系更大。
第四部分:总结
经过上面的实证分析,CART模型在进行短周期预测时的效果并不好,但是AdaBoost择时模型可以取得2倍于基准(一直持有)的年化收益率,最大回撤也更低(23.4% VS 49%),收益风险比也从基准的0.37提高到0.96,效果非常明显,是一个很不错的择时模型,当然上述结论只是基于46个指标通过回测得到的,在投入实盘之前还应该进行选用指标的敏感性分析、不同时间区间的测试分析以进一步验证模型的鲁棒性,有兴趣的读者可以自己进行深入研究,本文起一个抛砖引玉的作用不再进行详细的论述。

- 基于Hadoop MapReduce模型的数据分析平台研究设计
- 《基于几何成像模型的鱼眼镜头图像校正算法和技术研究》实现
- 基于retinex的模型夜间增强算法研究与改进效果
- 基于ERP的企业信息化结构模型与信息集成研究
- 《基于深度学习的线上农产品销量预测模型研究》阅读笔记
- 研读《高可用多节点集群技术的研究和实现》-----基于投票的心跳模型
- 基于布林带的股票量化择时策略研究
- 基于堆叠卷积长短期神经网络【CNNLSTM】模型的时序数据预测分析
- 基于Ruby API的Sketchup模型导出研究与实现
- 基于相关反馈技术的检索结果排序模型研究 - 中国优秀硕士学位论文全文数据库
- BIM研究-基于HTML5/WebGL技术的BIM模型轻量化Web浏览解决方案
- 算法-基于MACD的Adaboost股价涨跌预测模型
- 基于 IPO 经济理论模型对目前 ICO 的理论研究和分析
- 直播实录 | 基于生成模型的事件流研究 + NIPS 2017 论文解读
- 基于LDA模型的文本聚类研究
- "基于ARMA预测模型的电路故障研究"小结
- 基于几何成像模型的鱼眼镜头图像校正算法和技术研究的实现与改进
- 基于0-1整数规划的“玫瑰有约”模型--进一步利用matlab深入研究
- 基于UML的嵌入式硬件系统模型研究
- 第二十一篇:基于WDM模型的AVStream驱动架构研究