最新考研调剂信息全面获取!Python帮你一网打尽 - 知乎
https://zhuanlan.zhihu.com/p/110341064

CDA数据分析师 出品
今天我们聊聊如何获取考研调剂数据。上周考研分数已经出来了,最近多所院校官网也已经开始陆续发布调剂信息。要知道,在考研中调剂是非常重要的一环,复试与调剂也总是密不可分的,今天我们就带大家好好解读一下。
01
考研调剂
是怎么回事?
首先调剂指的是:
在研究生招生工作中,由于招生计划的限制,有些考生虽然达到分数线,但并不能被安排复试或复试后并不能被录取,对这些考生,招生单位将负责把其全部材料及时转至第二志愿单位,这个过程即称为考研调剂。
也就是说,那些没被自己心仪院校录取的考研生,想要考研上岸,这时候就需要去调剂,考研调剂中又有很多的注意事项,直接关乎着学生最后的考研成败。
所以说,有调剂意向的小伙伴,那就要抓紧开始准备了,毕竟越早联系就多一分机会。
02
调剂时
要特别注意的三点
在准备调剂时,以下这三点是十分重要的:
1. 调剂院校的往年录取分数
每个院校在考研中都有自己的录取分数线,而且每年基本都不会相差很大,因此,在找调剂院校的时候,一定要注意该院校的往年录取分数,看自己是否能达到这个标准。
2. 院校调剂的名额
每个院校的调剂名额都是有限的,这个自己一定要了解清楚,这直接关乎着自己的考研成败,如果院校的调剂名额少,自己初试分数又不是很高,这时候就要尽量避开。
3. 是否满足调剂院校的条件
每年接受考研调剂的院校也是有自己的硬性条件的,这时候自己一定要搞清楚,看自己是否适合,不然,很容易错失调剂的机会,就白白浪费了自己的备考时间。

03
用Python
爬取调剂信息
要想成功调剂,首先要把握调剂的第一手信息,能及时地获取到哪所高校的专业招生人数不足,而且符合你的条件,这是很有必要的。
那么今天,我们就来说一说怎么去获取调剂数据并进行分析。以帮助大家更好的了解考研调剂形势。
我们选取中国考研网站上公布调剂查询页面,用Python爬取调剂信息。截止到2月29日16:00,我们共分析整理了385所高校的调剂信息。
1、获取数据
我们选取中国考研网站上公布调剂查询页面,其页面效果大致如图所示:

首先对页面结构进行简单的分析,确定我们的数据抓取策略。
第一步:获取一页的信息
我们使用谷歌浏览器的开发者工具功能进行元素审查,通过对HTML进行审查,很容易可以可以发现所有的信息流的都是DIV标签包裹的,其共同特征都是class=”info-item font14” 。因此我们可以使用BeautifulSoup库的标签定位功能,先定位到class=”info-item font14” 的标签,再往下一层定位到class="school",class="name"等标签属性信息,从而获取页面所有信息。
如图所示,我们获取的信息主要有:
- 学校
- 专业
- 调剂信息标题
- 发布时间
- 主页URL
第二步:循环翻页
第一页的网页地址是页面地址:
http://www.chinakaoyan.com/tiaoji/schoollist/pagenum/1.shtml
通过对网页进行翻页,不难发现网页的构造是有规律的,变化的是pagenum后面的数字,因此我们可以循环的方式构建这个网页地址即可获得所有的网页地址,从而获取所有的页面信息。
代码实现:
# 导入包import numpy as np import pandas as pd import requestsfrom bs4 import BeautifulSoup from fake_useragent import UserAgentimport time import redef get_one_page(url):'''功能:给定URL地址,获取一页的信息''' # 随机UAheaders = {'user-agent': UserAgent.random}try: # 发起请求r = requests.get(url, headers=headers, timeout=5) except Exception:time.sleep(3) r = requests.get(url, headers=headers, timeout=5) # 解析网页bs = BeautifulSoup(r.text, 'lxml')
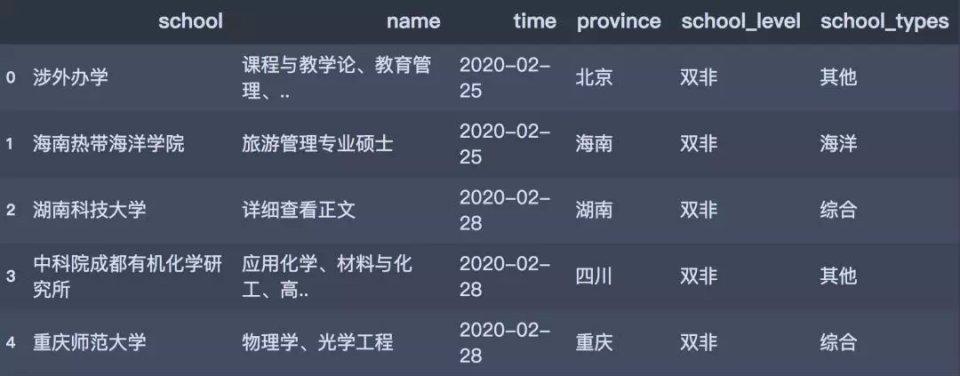
爬取出来的数据以数据框的形式存储,结果如下图所示:
df.head

截止到2020.2.29日,发布调剂数据一共有385条。
从主页URL中可以获取学校对应的省份信息,这一步代码和上述过程类似。将学校的属性信息进行基本的清洗,得到数据如下:
df.head

然后将学校的属性信息与调剂信息合并,得到用于数据分析所用的宽表信息如下:
# 合并信息df_all = pd.merge(df, df_info, on='school', how='left') # 选取分析字段df_all = df_all[['school','name','time','province','school_level','school_types']] df_all.head
2、数据可视化
接着使用pyecharts库对数据进行以下几个方面的可视化分析:
- 调剂信息发布热度
- 学校层次分析
- 学校类型分析
- 学校地域分析
- 专业/技能/领域分析
调剂信息发布热度

图中可以看到,调剂信息发布最多的是2月21日,也就是考研成绩公布的这几天。
代码实现:
# 发布时间对应的发布频次pub_time = df_all.time.value_counts pub_time = pub_time.sort_indexfrom pyecharts.charts import Linefrom pyecharts import options as opts# 时间走势图line1 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))line1.add_xaxis(pub_time.index.tolist) line1.add_yaxis('发布热度', pub_time.values.tolist, areastyle_opts=opts.AreaStyleOpts(opacity=0.5), label_opts=opts.LabelOpts(is_show=False)) line1.set_global_opts(title_opts=opts.TitleOpts(title="调剂信息发布时间走势图"), toolbox_opts=opts.ToolboxOpts, visualmap_opts=opts.VisualMapOpts)
学校层次分析

可以看到,调剂学校中双非院校居多,占比高达88.94%。211院校为5.65%,985院校为5.41%。近年来很多双非院校的进步也是很大的,发展态势良好,在调剂时根据院校的具体实力,考生还是可以选择的。
代码实现:
# 学校层次level_perc = df_all.school_level.value_counts / df_all.school_level.value_counts.sumlevel_perc = np.round(level_perc*100,2)# 导入所需包from pyecharts.charts import Piefrom pyecharts.globals import ThemeType# 绘制柱形图pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px')) pie1.add("", [*zip(level_perc.index, level_perc.values)], radius=["40%","75%"]) pie1.set_global_opts(title_opts=opts.TitleOpts(title='学校层次分布'), legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),toolbox_opts=opts.ToolboxOpts) pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%")) pie1.render
学校类型分析

从图中可以看到,调剂院校中主要是理工、综合类型院校居多,分别占比42.59%和27.06%。其次是工科占比11.29%。而弄农林、师范、医药等院校的占比都特别小,调剂信息很少。在搜集高校调剂信息的时候,考生也就更有侧重点了。
代码实现:
# 学校类型type_perc = df_all.school_types.value_counts / df_all.school_types.value_counts.sumtype_perc = np.round(type_perc*100,2)# 导入所需包from pyecharts.charts import Pie# 绘制柱形图pie2 = Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND, width='1350px', height='750px')) pie2.add("", [*zip(type_perc.index, type_perc.values)], radius=["40%","75%"]) pie2.set_global_opts(title_opts=opts.TitleOpts(title='学校类型分布'), legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),toolbox_opts=opts.ToolboxOpts) pie2.set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%")) pie2.render
学校地域分析

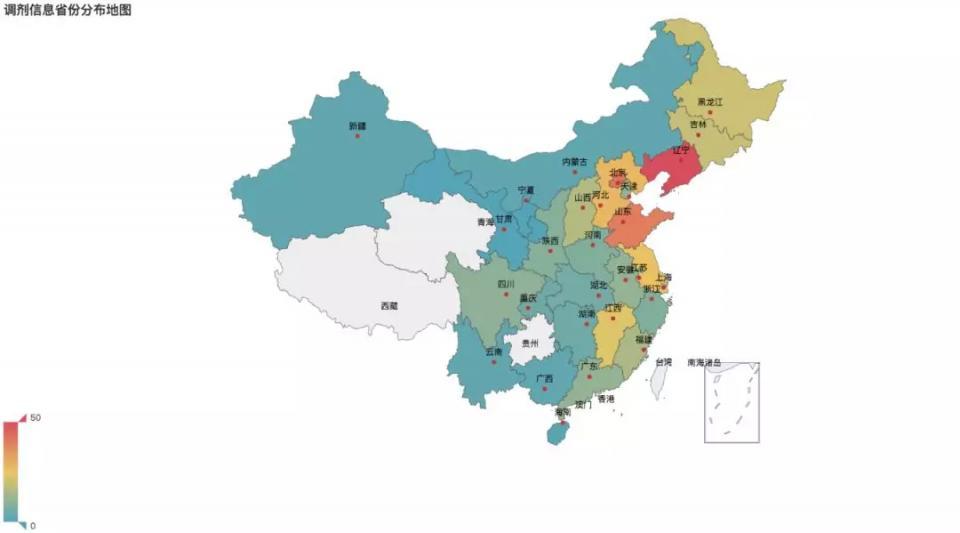
可以看到调剂机会遍布全国,其中占比前三的省市分别是辽宁、北京、山东。沿海城市的调剂机会也很多。只要把握好机遇,考生们一定可以去自己理想的城市读书的。
代码实现:
province_num = df_all.province.value_counts province_num = province_num.sort_valuesfrom pyecharts.charts import Bar# 条形图bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px')) bar1.add_xaxis(province_num.index.tolist)bar1.add_yaxis("省份", province_num.values.tolist) bar1.set_global_opts(title_opts=opts.TitleOpts(title="调剂信息发布数省份分布"), toolbox_opts=opts.ToolboxOpts,visualmap_opts=opts.VisualMapOpts(max_=40)) bar1.set_series_opts(label_opts=opts.LabelOpts(position='right')) # 标签bar1.reversal_axis bar1.render
from pyecharts.charts import Mapc = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))c.add('',[list(z) for z in zip(province_num.index.tolist, province_num.values.tolist)], 'china')c.set_global_opts(title_opts=opts.TitleOpts('调剂信息省份分布地图'), toolbox_opts=opts.ToolboxOpts(is_show=True), visualmap_opts=opts.VisualMapOpts(max_=50)) c.render
专业/技能/领域分析

可以看到工程、材料、化学等理科专业在调剂中还是比较吃香的。
代码实现:
content = df_all.name.str.catkey_words = get_words_num(content) key_words = key_words[:50]from pyecharts.charts import WordCloudfrom pyecharts.globals import SymbolType, ThemeTypeword1 = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))word1.add("", [*zip(key_words.index.tolist, key_words.values.tolist)], word_size_range=[20, 200], shape='diamond') word1.set_global_opts(title_opts=opts.TitleOpts(title="调剂专业分布"), toolbox_opts=opts.ToolboxOpts) word1.render

结语:
调剂这条路实在是不轻松,千万不要坐着等别人来调剂你。调剂也是一个残酷竞争的过程,你晚去一步,位置就可能被人占了,一定要尽早行动,从速从早。最后祝愿所有的考生都能调剂成功,今年顺顺利利地考上研究生!
更多行业干货持续不断分享给大家,可以一直关注我们哟!
(1)获取更多优质内容,可前往:大数据AI时代,所有职场人都在高薪奔跑,您怎能OUT?

(2)也可微信搜索CDA小程序,手机端随时随地浏览最新资讯和优质课程:


- Python获取最新电影的信息
- [置顶] 使用Python获取每天最新CVE漏洞信息,通过邮件进行预警发送(二)
- python+微博API获取我的粉丝列表和关注列表信息(只能得到最新的30%)
- Python:如何比较均匀的获取知乎用户信息并且存储在本地的Excel中?
- python中系统信息获取psutil使用
- Python学习:使用boost c++嵌入python,获取异常信息输出到字符串
- 【python】获取目录下的最新文件夹/文件
- Python的学习(十九)--获取网页信息(一)
- [Python] 根据IP获取位置信息
- python获取Linux信息
- PYTHON调用WIM对象获取WINDOWS系统的相关信息并打印到EXCEL
- Python——获取电脑信息
- Python语言学习讲解十九: 异常信息的详细获取
- Python语言学习讲解七:使用traceback获取详细的异常信息
- Python获取航线信息并且制作成图的讲解
- python(5) 获取acfun弹幕,评论和视频信息
- 使用 Python 获取 Linux 系统信息的代码
- python获取微信用户基本信息
- Python(2):Python获取网页信息
- 树莓派使用python获取GY-85九轴模块信息