Top命令你最少要了解到这个程度
2020-03-18 17:25
447 查看
`top`命令几乎是每个程序员都会用到的Linux命令。这个命令用来查看Linux系统的综合性能,比如CPU使用情况,内存使用情况。这个命令能帮助我快速定位程序的性能问题。
虽然这个命令很重要,但是之前对于这个命令的使用几乎仅限于查看下哪个进程使用的CPU最高,哪个进程占用的内存最高。对于输出的各个参数的含义也是一知半解,更不用说`top`的一些高级用法了。
本篇博客就来具体分析下`top`的详细使用方法。
## `top`输出参数的含义
在Linux终端输入`top`,一般会有如下输出。
```bash
top - 15:34:12 up 127 days, 10:23, 2 users, load average: 0.04, 0.03, 0.00
Tasks: 291 total, 1 running, 290 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 98.3%id, 1.3%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1792312k total, 288300k used, 1504012k free, 10384k buffers
Swap: 6291452k total, 5380k used, 6286072k free, 14128k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
372007 root 20 0 15160 1336 888 R 0.3 0.1 0:00.33 top
1 root 20 0 19356 236 88 S 0.0 0.0 0:16.06 init
... 下面省略...
```
下面就对这些输出信息做下详细的说明
### 系统运行时间和平均负载
`top`输出的第一行表示系统的运行时间和平均负载
```bash
top - 15:34:12 up 127 days, 10:23, 2 users, load average: 0.04, 0.03, 0.00
```
- `15:34:12 `: 表示系统的当前时间是下午15点34分12秒;
- `up 127 days, 10:23`:表示这个Linux系统已经启动127天多;
- `2 users`:表示当前有两个用户登陆系统,可以用`who`命令查看具体是谁登陆了;
- `load average: 0.04, 0.03, 0.00`:最近1、5和15分钟内的平均负载
**1. load average的含义**
这里我们对这个`laod average`指标做下详细说明。
> laod average这个指标的含义:在特定时间间隔内运行队列中(在CPU上运行或者等待运行多少进程)的平均进
> 程数(**状态是Runnable和running的线程个数的和**)。
>
> 上面这个解释可能还是比较难理解。我们拿个实际的列子说明下。比如现在top命令有以下输出:
>
> load average: 20.14, 22.03, 15.00
>
> 20.14 表示从当前时间到过去的一分钟内大概有 20.14个进程(线程)在等待CPU资源
>
> 22.03 表示从当前时间到过去的五分钟内大概有 22.03个进程(线程)在等待CPU资源
>
> 15.00 表示从当前时间到过去的十五分钟内大概有 15.00个进程(线程)在等待CPU资源
为了更好地理解这个负载的含义,下面列了一个交通流量的列子。
**单核CPU可以想象成单车道**
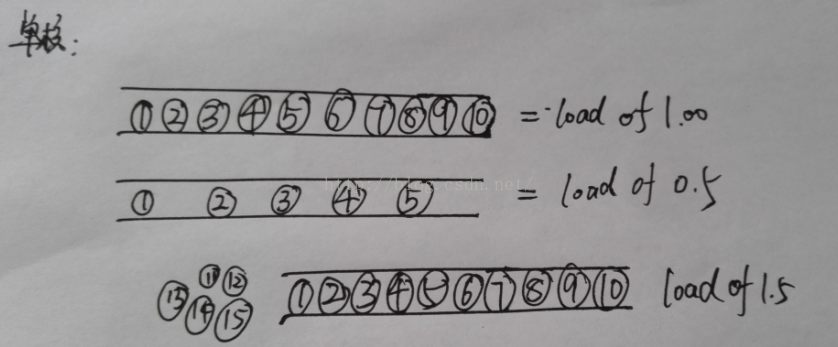
比如每个圆圈都是小汽车,第一种是满负荷但CPU时间片不用排队等待正好够用,第二种是%50空闲,第三个是超负荷50%,后面的就有队列等待了。
**单核CPU,负载数值在0.00-1.00之间正常。**
- 0.00-1.00之间的数字表示此时路况非常良好,没有拥堵,车辆可以毫无阻碍地通过。
- 1.00表示道路还算正常,但有可能会恶化并造成拥堵。此时系统已经没有多余的资源了,管理员需要进行优化。
- 1.00以上表示路况不太好了,如果到达2.00表示有桥上车辆一倍数目的车辆正在等待。这种情况你必须进行检查了。
**多核CPU可以想象成多车道**
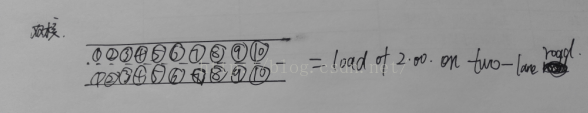
多核CPU的话,负载数值/CPU核数 在0.00-1.00之间表示正常。
现实生产中,不会让负载数值/CPU核数任意接近1的。一般当这个值达到0.8或者0.9时就需要分析分析原因了。当然这个也没有具体的定论,都是一家之言。
**2. load average和CPU利用率的区别(这两个概念很重要,希望大家仔细看看)**
先直接引用下[这篇文章](https://blog.csdn.net/zhangchenglikecc/article/details/52103737)中的截图



**上面的列子对CPU使用个CPU做了比较好的解释,我自己也想了个列子,可能更加形象贴切。**
其实,可以将CPU比喻成公司的厕所。比如说你所在的楼层有一个卫生间。每个卫生间有4个坑位(4核CPU)。一般早上的时候资源会比较紧张,在某个时间点,你做了一个统计,你发现在过去的1分钟,5分钟和15分钟内分别有6个人,8个人,8个人正在”使用“厕所(这里的人数包括等待上厕所和正在上厕所的人数),那儿此时公司厕所的负载就是6.00,8.00和8.00。通过上面的介绍我们发现此时公司厕所是过载的。(这个就是CPU负载的概念)
那么CPU使用又是什么意思呢?
还是以刚刚的厕所为列子。以现在的时间点到过去的15分钟内,你发现有3个同事用了其中一个坑位。时候你采访了下这个三个同事:在他们使用厕所的过程中多长时间是真的在上厕所?采访结果是:第一个同事2分钟上测试+3分钟玩手机,第二个同事1分钟上厕所+3分钟胡思乱想,第三个同事3分钟上厕所+3分钟玩手机。
那么这段时间内这个坑位的利用率就是(2+1+3)/15 = 40%
**3. CPU负载和CPU使用率对我们的知道意义**
- 高CPU负载 低CPU使用率:可能系统中较多的文件IO和网络IO操作。
- 高CPU负载 高CPU使用率:CPU资源不足
- 低CPU负载 低CPU使用率:系统CPU资源良好,道路非常顺畅;
- 低CPU负载 高CPU使用率:这种情况一般都是程序的问题,比如程序中代码进入死循环,有很多自旋操作等。CPU使用率一直过高对CPU伤害比较大。
上面只是列了一些比较常见的情况,具体问题还得具体分析。
### 任务信息
```
Tasks: 291 total, 1 running, 290 sleeping, 0 stopped, 0 zombie
```
Tasks — 任务(进程),系统现在共有 291 个进程,其中处于运行中的有1个,290个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
> 按 t 可以关闭显示这个任务信息,再按下 t 可以开启这个任务信息
### CPU状态
```
Cpu(s): 0.0%us, 0.3%sy, 0.0%ni, 98.3%id, 1.3%wa, 0.0%hi, 0.0%si, 0.0%st
```
- us 列显示了用户模式下所花费 CPU 时间的百分比。**us的值比较高时,说明用户进程消耗的 CPU 时间多,但是如果长期大于50%,需要考虑优化用户的程序。**
- sy 列显示了内核进程所花费的 CPU 时间的百分比。**这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。**
- ni 列显示了用户进程空间内改变过优先级的进程占用CPU百分比。
- id 列显示了 CPU 处在空闲状态的时间百分比。
- wa 列显示了IO等待所占用的CPU时间的百分比。**这里 wa 的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。** 这个wa和vmstat中的wa是相同含义。
- hi 硬件中断占用CPU
- si 软件中断占用CPU
- st 丢失时间占用CPU
**在后台开发中需要关注us,sy,id,wa等常用指标**。
> 按数字 1,可以查看CPU的核数和每个CPU的使用情况。
### 内存使用情况
```
Mem: 1792312k total, 288300k used, 1504012k free, 10384k buffers
Swap: 6291452k total, 5380k used, 6286072k free, 14128k cached
```
关于这些值表示的具体含义,我在我的博客[Linux 内存分析工具——free命令](https://www.cnblogs.com/54chensongxia/p/12330592.html)中详细分析过,大家可以参考。
### 进程的状态监控
```
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
372007 root 20 0 15160 1336 888 R 0.3 0.1 0:00.33 top
1 root 20 0 19356 236 88 S 0.0 0.0 0:16.06 init
```
- PID:进程ID,进程的唯一标识符
- USER:进程所有者的实际用户名。
- PR:进程的调度优先级。这个字段的一些值是'rt'。这意味这这些进程运行在实时态。
- NI:进程的nice值(优先级)。越小的值意味着越高的优先级。负值表示高优先级,正值表示低优先级
- VIRT:进程使用的虚拟内存。进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
- RES:驻留内存大小。驻留内存是任务使用的非交换物理内存大小。进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
- SHR:SHR是进程使用的共享内存。共享内存大小,单位kb
- S:这个是进程的状态。它有以下不同的值:
- D - 不可中断的睡眠态。
- R – 运行态
- S – 睡眠态
- T – 被跟踪或已停止
- Z – 僵尸态
- %CPU:自从上一次更新时到现在任务所使用的CPU时间百分比。
- %MEM:进程使用的可用物理内存百分比。
- TIME+:任务启动后到现在所使用的全部CPU时间,精确到百分之一秒。
- COMMAND:运行进程所使用的命令。进程名称(命令名/命令行)
> 还有许多在默认情况下不会显示的输出,它们可以显示进程的页错误、有效组和组ID和其他更多的信息。
>
> 按下 f 键盘可以调出更多显示选项。按esc键返回top显示页。
## top的一些命令行参数
- -b:批处理模式(batch mode),可输出到管道、文件。默认情况下-b会一直输出,可以用-nN指定输出次数。
- -n N:限制输出次数。
- -d N:刷新时间间隔。
- -p PID:监控指定进程。
- -Hp PID:监控指定进程和进行内线程信息。(**比较常用**)
## top一些交互键的说明
进入top页面后,我们可以进行一些交互操作。下面是一些交互键的说明:
- c 显示完整的命令名。c为Command之意。
- d 修改刷新时间。d为Display之意。
- **u 显示指定用户相关进程。u为User之意**。
- P 按CPU使用排序。P为Processor(处理器)之意。
- M 按内存使用排序。M为Momery之意。
- **F 排序(进入新的界面,并选择排序的目标字段)**。
- R 顺序或逆序。
- H 显示线程
- Z 以多色彩显示top。
## 参考
- [top命令输出解释以及load average 详解及排查思路](https://blog.csdn.net/zhangchenglikecc/article/details/52103737)
- http://wenku.baidu.com/view/6597f58884254b35eefd34f7.html
- [linux top显示的各个符号参数意义详解](https://blog.csdn.net/csdn066/article/details/77170385)

相关文章推荐
- 学习进程之命令top命令(二)
- Linux - top命令
- TOP命令
- Linux Ps与Top命令详解
- linux下top命令详解
- TOP命令详解
- Linux 之top命令
- w命令、vmstat命令、top命令、sar命令、nload命令
- linux 进程监控命令1——top
- 命令top动态监控进程所占系统资源
- 使用w查看系统负载、vmstat 监控系统状态、top命令、监控网卡流量
- linux怎样使用top命令查看系统状态
- top命令
- 【linux】top命令详解
- linux top命令详解
- adb shell中退出类似top的命令
- Linux Top 命令参数解析
- 使用w查看系统负载 、vmstat、top、sar、nload命令
- top命令的Load average 含义及性能参考基值
- Linux 命令 - top