Hive
2020-03-15 21:50
337 查看

- 基于分布式存储用于查询和管理的数据仓库
- 海量存储数据一般都可以使用mapreduce进行计算分析,获取中间结果,又作为初始结果进行输入,最终可以得到计算的结果,缺点是效率低
- 实现MapReduce逻辑比较复杂
- 使用sql语句操作,把大量的MapReduce程序写成一个模版,封装到一个框架中,这个框架就是hive
- hive创建出一个表,关联文件存储路径,放到元数据库中,在根据sql语句的类型编译出相应的MapReduce程序,就可以得到一个可以运行的程序传给执行器,就可以根据hadoop命令提交到集群中,这样就无需自己写MapReduce程序,只需要写SQL语句就可以
- hive比较慢,因为底层使用的是MapReduce框架实现的
- spark替代hive,spark底层是把sql语句翻译成spark
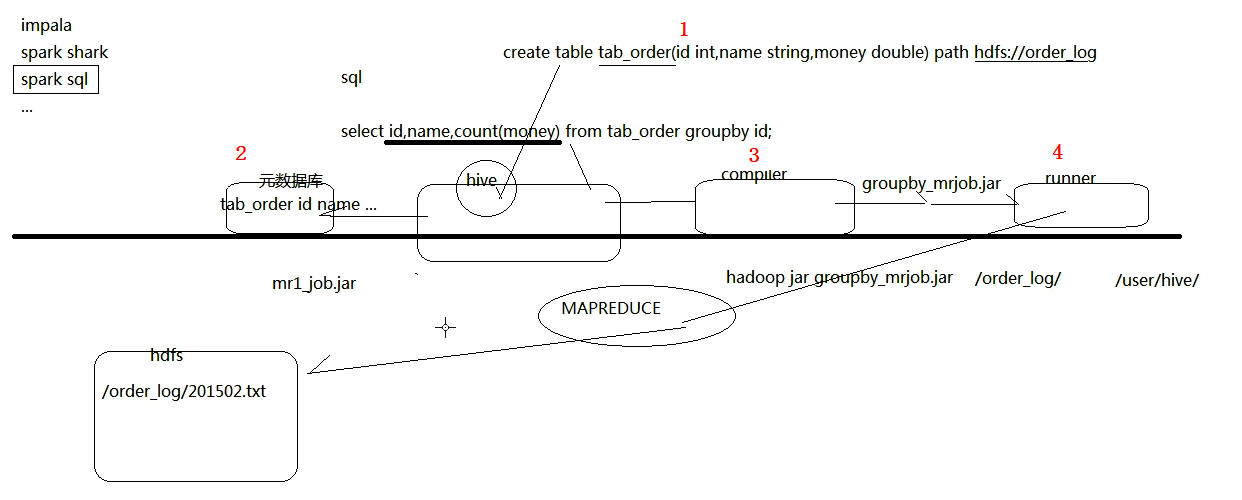
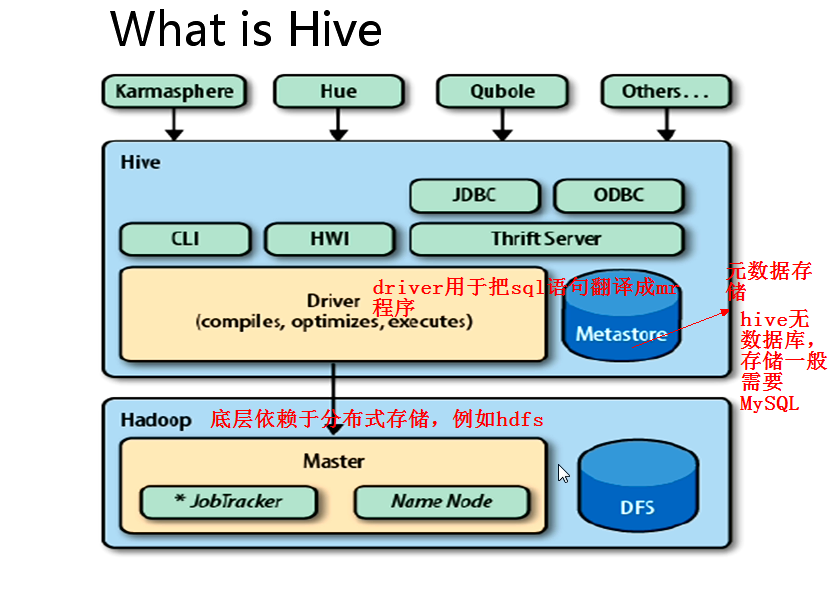
- hive结构
- hive不支持单条操作,因为hdfs不支持

相关文章推荐
- hive常用小常识(持续更新中)
- Hive中的数据分区
- 运用sqoop将数据从oracle导入到hive中的注意的问题
- Spark整合Hive
- Running HQL from Python without using the Hive Standalone Server
- hive 日志存放位置修改
- hive 配置参数说明
- Hive:表1inner join表2结果group by优化
- 通过hadoop上的hive完成WordCount
- Hive总结
- hive使用技巧(一)自动化动态分配表分区及修改hive表字段名称
- Hadoop Hive概念学习系列之hive里的用户定义函数UDF(十七)
- python连接hiveserver2
- 1.Hive读取ElasticSearch中的数据
- Hive安装出现的问题
- 1005-Hive的QL语法
- HIVE 安装设置
- hive2.1.1安装部署
- hivesql错误1:java.lang.Throwable: Child Error, status:255
- hive on tez详细配置和运行测试