虚拟化特性(一)通用虚拟化特性
文章目录
前言
前面我们说过,云计算是一种模式,而虚拟化是一种技术,我们也说过,云计算1.0时代是以虚拟化为主的,那么虚拟化究竟有什么特性可以使其成为云计算中很重要的部分呢?
回顾
在介绍虚拟化特性之前,我们先回顾一下虚拟化的特点:分区、隔离、封装、独立
基于这些特点,虚拟化具备很多特性,我们从集群和虚拟机两个角度介绍。
虚拟化集群特性介绍
集群
集群是一种把一组计算机组合起来作为一个整体向用户提供资源的方式,在虚拟化集群中可以提供计算资源、存储资源和网络资源,只有包含了这些资源以后,该集群才是完整的。
HA特性
先分享一个李开复耳熟能详的故事。早年,李开复博士曾在苹果电脑公司任职,专门负责新产品的研制和开发。有一次,李开复与公司CEO史考利先生,受到美国当时最红的早间电视节目“早安美国”的邀请。在当时,能上这个收视率非常高的节目,不仅是苹果公司的荣誉,也是李开复展现个人魅力的机会。电视台方面提前和苹果公司沟通,希望他们能在电视直播中,演示苹果公司最新发明的语音识别系统,让更多消费者了解公司的新产品。
但是,该系统成功的概率大概是90%,史考利希望把成功率提高到99%。
李开复并没有修改程序,而是准备两台一样的电脑,如果一台电脑出了问题,立刻切换到另外一台电脑,那么根据概率原则,两台电脑出现故障的为10%*10%=1%,那么成功率就到了99%。
这个就是HA实现的基本原理:使用集群技术,克服单台物理主机的局限性,最终达到业务不中断或者中断时间减少的效果。
在虚拟化中的HA只保证计算层面,具体来说,虚拟化层面的HA是虚拟机系统层面的HA,即当一台计算节点出现故障时,在集群中的另外一台节点中能快速自动的将其启动起来。
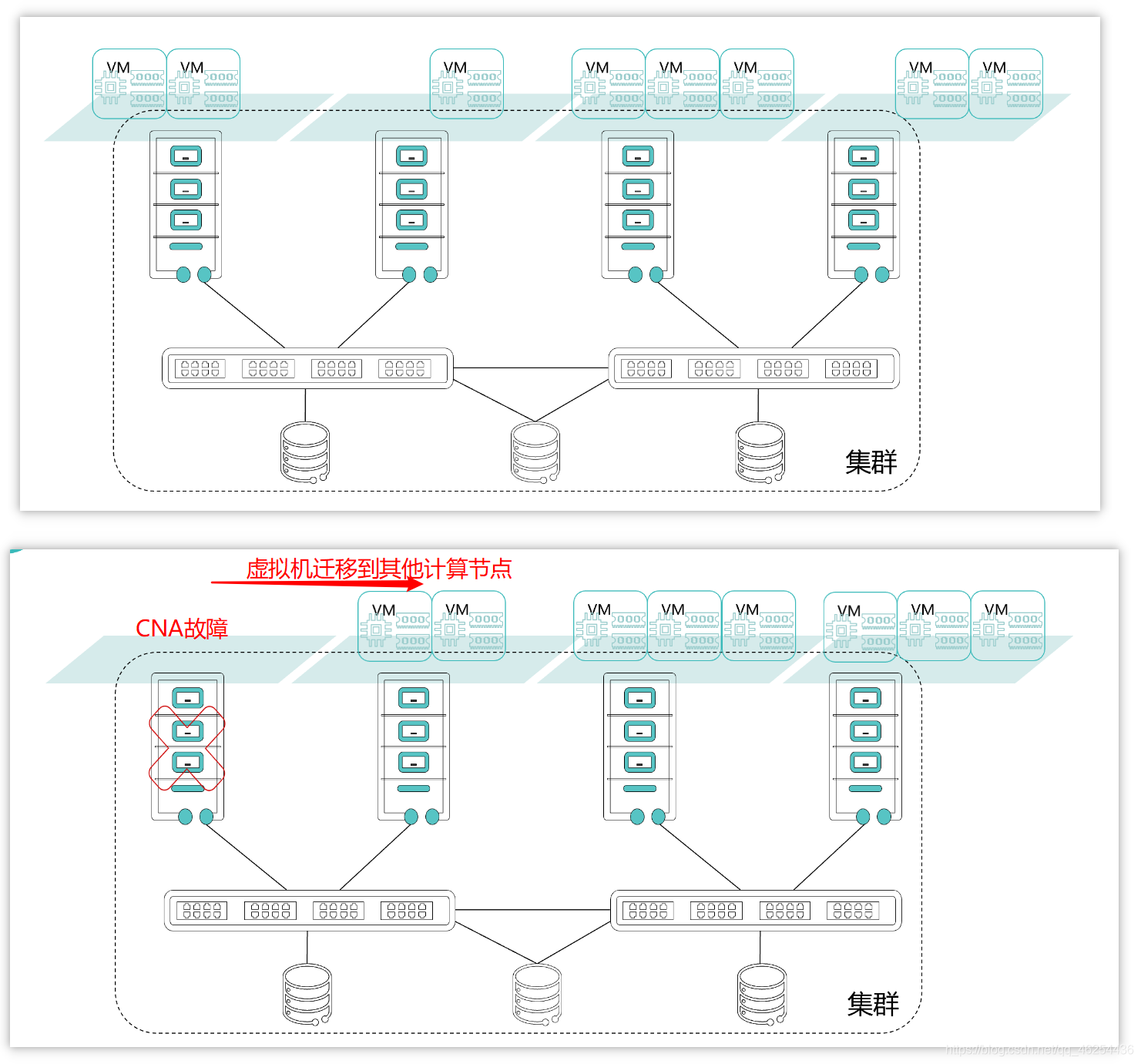
如上图中的场景,当集群中第一台节点出现故障时,该节点上的虚拟机会自动迁移到其它工作正常的主机上。
虚拟化集群一般都会使用共享存储,我们前面讲过,虚拟机由配置文件和数据盘组成,而数据盘是保存在共享存储上的,配置文件则保存在计算节点上。当计算节点出现故障时,虚拟化管理系统(如vCenter、VRM等)会根据记录的虚拟机配置信息在其它节点重建出现故障的虚拟机。
在实现HA的过程中,有两个难点需要解决:
1. 如何发现主机是否发生了故障? 2. 如果虚拟机不能正常启动该怎么办?
首先看第一个问题。如果要检测到计算节点是否故障,管理员需要定期和集群内所有的节点建立通讯,一旦某个节点无法通讯,则证明该节点可能出现了故障。以华为的FusionCompute为例,CNA主机和VRM通过心跳机制来保证VRM有效的感知CNA节点是否发生了异常,具体过程如下:
- CNA主机侧有某个进程或服务承载着心跳机制的任务;
- 主机每间隔3s会向VRM主动上报心跳,如果连续10次,即30s内主机没有向VRM上报心跳,则会置此主机为“故障”状态,此时FC-Portal上会有“主机与VRM心跳异常”的告警出现;
- 主机每次向VRM上报心跳的时候都有超时机制,socket连接、接收、发送超时时间均为10s,如果VRM服务有异常或网络出现异常,都可能导致超时出现,而每次打印超时日志的时机=“超时探测时间间隔3s”+“socket超时时间10s”= 13s 的日志时间戳;
- VRM侧每收到一个主机侧发来的心跳就会将心跳频率heartBeatFreq变量设置为10(默认为10,此值可以通过修改配置文件修改),检测线程每3s会将该值减1,同时对该参数当前值进行判断,如果<=0,则认为此值对应的主机节点异常,在FC-Portal 上报告警,同时会把此主机异常的消息发送给VRM进行虚拟机HA机制判断。
接下来看一下第二个问题。虚拟机在其它主机上启动的时候,有可能会虚拟机上的业务无法自启动,甚至可能操作系统都无法正常启动,所以虚拟机层面的业务不能恢复的风险很大,同时业务恢复的时间也较长,这时候我们需要启用业务层面的HA,一旦主用的虚拟机出现故障或者不能恢复时,业务会借助浮动IP、Keepalived等与高可用相关的技术,将业务在备用的虚拟机上恢复。
因此,虚拟机层面的HA一般会和应用层面的HA配合使用,可以缩短业务恢复的时间,提高业务恢复的几率。
除了以上问题外,如何防止脑裂也是需要考虑的问题。脑裂是由于共享存储有可能会同时被两个虚拟机执行写操作而造成的。在系统进行HA前,管理系统会通过心跳机制检测计算节点是否故障,但是如果只是心跳网络出现了故障,就会造成管理系统误判计算节点故障的情况发生,这时候就可能造成脑裂现象。所以,系统在进行启动虚拟机以前会检测对应的存储是否有写操作,如果有的话,则证明主机有可能没有出现故障,这时候,系统就不会在继续执行虚拟机的启动操作了,而是直接在管理系统的页面显示HA成功。
负载均衡
负载均衡在许多的地方都有出现这个名词,在网络中有链路做负载均衡、网卡做负载均衡。在云计算中,负载均衡和网络中的概念其实一样,只是对象换成了虚拟机。
负载均衡可以简单理解为:一个公司内部,有三个员工:小明、小红、小刚,工资相同,做的工作也一样。小明做了比较鸡贼,平时爱偷懒,做了正常工作量的80%;小红是老板的亲戚,平时工作有恃无恐,做了正常工作的60%;小刚比较老实,勤劳能干,做了平常工作的160%,所以小刚经常加班。过了几个月,良心的老板发现了这个问题,指出了小明和小红的不足,要求他们要分担小刚的工作。之后三个人都做到了正常工作的100%。
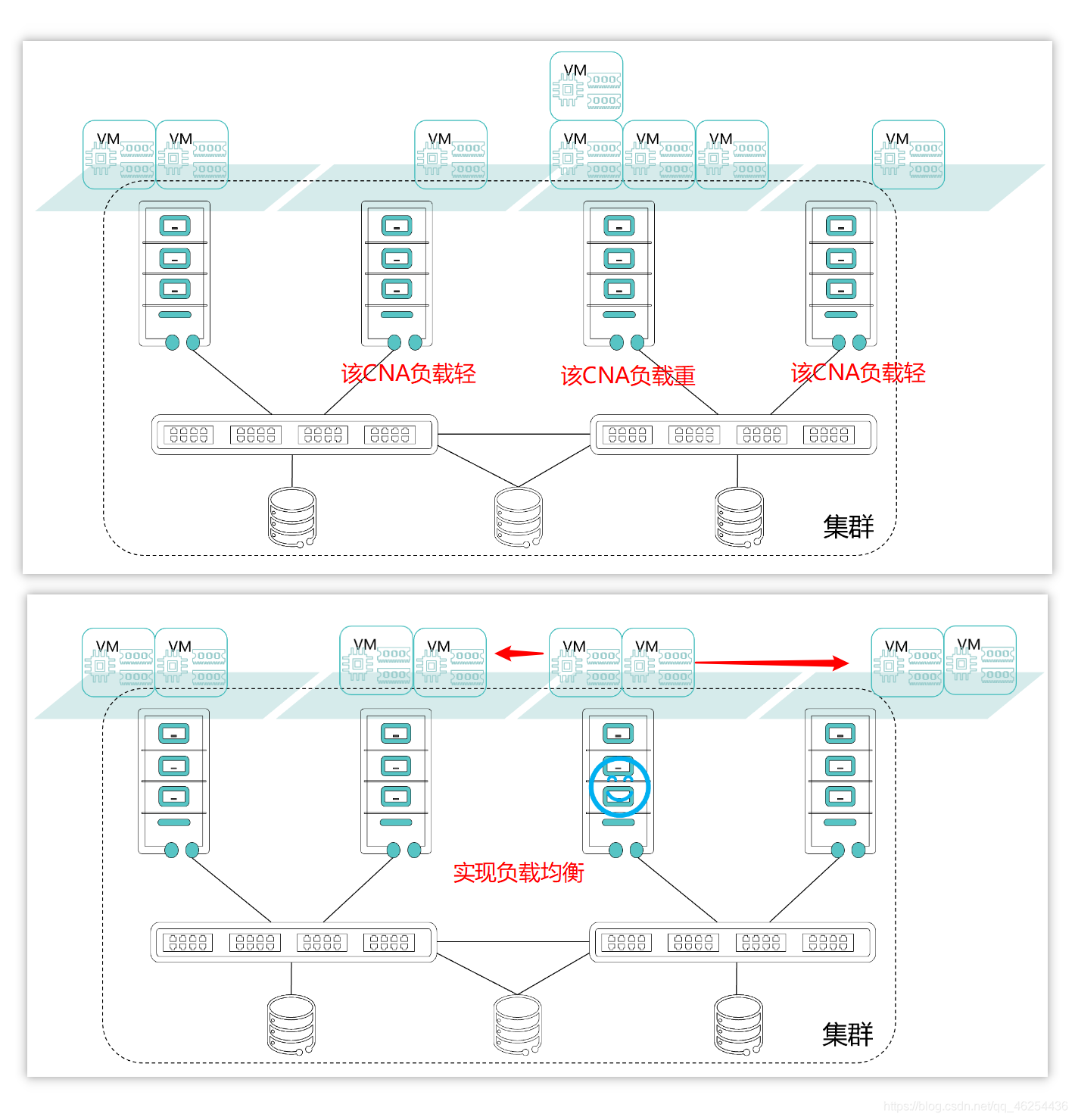
如上图在集群中发现有一台主机上运行虚拟机较多(大家都是一模一样的服务器,你凭什么这么优秀呢?)但是他自己心里也挺苦的,负担这么重,又不加工资,运行一段时间后,这时候集群的虚拟化软件和自动发现该主机负载较大(两种选择:要么加工资,要么不要这么多的活)会把该主机上的虚拟机迁移到其他主机上,使主机达到相对于负载均衡的状态。(公平的状态)
解决了一台服务器卖力干活,其他服务器看戏的问题。提升服务器寿命。
详细解释
负载均衡是一种集群技术,它将特定的业务(网络服务、网络流量等)分担给多台网络设备(包括服务器、防火墙等)或多条链路,从而提高了业务处理能力,保证了业务的高可靠性。
优势
- 高性能:负载均衡技术将业务较均衡地分配到多台设备上,提高了整个系统的性能。
- 可扩展性:负载均衡技术可以方便地增加集群中设备或链路的数量,在不降低业务质量的前提下满足不断增长的业务需求。
- 高可靠性:单个甚至多个设备或链路发生故障也不会导致业务中断,提高了整个系统的可靠性。
- 可管理性:大量的管理工作都集中在应用负载均衡技术的设备上,设备群或链路群只需要常规的配置和维护即可。
- 透明性:对用户而言,集群等同于一个可靠性高、性能好的设备或链路,用户感知不到也不必关心具体的网络结构。增加和减少设备或链路均不会影响正常的业务。
判断依据:
在虚拟化环境中,负载均衡的对象一般是计算节点,判断依据为计算节点的CPU和内存的利用率。管理系统会在虚拟机创建和运行的过程中,感知整个集群所有物理资源的使用情况,并使用智能调度算法,确定适合虚拟机运行的最佳主机,并通过热迁移等手段将虚拟机迁移过去,从而提升全局业务体验。
负载的阈值可以由系统管理员指定,也可以使用系统自定义。比如,在华为FusionCompute中,系统自定义如果某台主机的CPU和内存的使用率超过60%时,VRM就会将此CNA主机上的虚拟机迁移到其它节点上,在迁移前,管理员可以将迁移任务设置为自动,也可以向管理员发通知,等管理员确认后,再进行迁移。
易扩容
在传统非虚拟化的环境中,所有的业务都部署在物理机上,有可能在系统建设的初期,业务量不是很大,所以为物理机配置的硬件资源是比较低的,随着业务量的增加,原先的硬件无法满足需求,只能不停的升级硬件,比如将原先的一路CPU升级为两路,将256G的内存升级为512G,这种扩容方式称为纵向扩容(Scale-up)。然而,物理机的所能承担的硬件是有上限的,如果业务量持续增加,最后只能更换服务器,停机割接是必然的。
拿个人电脑升级举例:想要升级内存、硬盘,要考虑是否有多余的接口,支持的最大容量等问题。
在虚拟化中,将所有的资源进行池化,承载业务虚拟机的资源全部来自于这个资源池,当上面业务量持续增加的事情发生时,我们不需要升级单台服务器的硬件资源,只需要增加资源池中资源即可,具体在实施的时候,只需要增加服务器的数量即可,这种扩容方式称为水平扩容(Scale-out)。
集群支持水平扩容,所以相对传统的非虚拟化IT,扩容更容易。
内存复用
内存复用是指在服务器物理内存一定的情况下,通过一定技术手段,使得虚拟机内存总和大于服务器物理内存总和,提高服务器中虚拟机密度。
内存复用的技术主要包括:内存气泡、内存置换、内存共享。一般情况下,这三种技术需要综合应用,同时生效。
内存共享
Hypervisor作用:虚拟化技术的核心。最主要的作用:分配内存、CPU资源等等
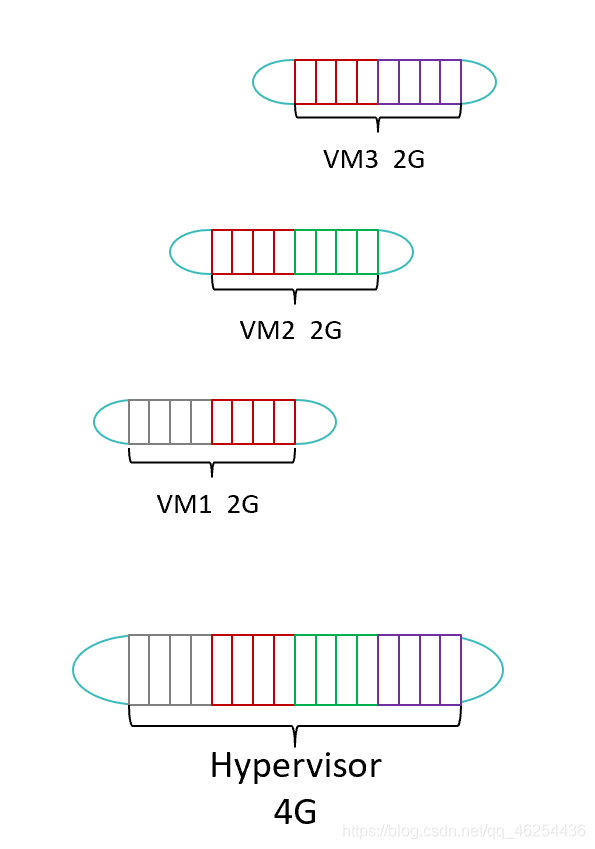
在图中,物理主机为hypervisor提供了4G的物理内存,分别分配给三台虚拟机,这三台虚拟机恰好会读取同一段物理内存中的数据,根据我们前面讲的内存虚拟化的实现方式,Hypervisor在做内存映射时,会同时将这一段内存映射给不同的虚拟机,**为了保证这一段内存里的数据不会被任意虚拟机修改,所有的虚拟机对该内存只有读操作权限,**如果虚拟机需要对内存进行写操作,需要Hypervisor新开辟一段内存进行映射。通过内存共享技术,只有4G的物理内存可以分配出6G的虚拟内存给虚拟机。
总结:不同的虚拟机会共享同一段内存,但是有一个前提:虚拟机都会读取这段内存中的数据。(可以简单的理解:两个虚拟机都开了相同的应用)
内存气泡
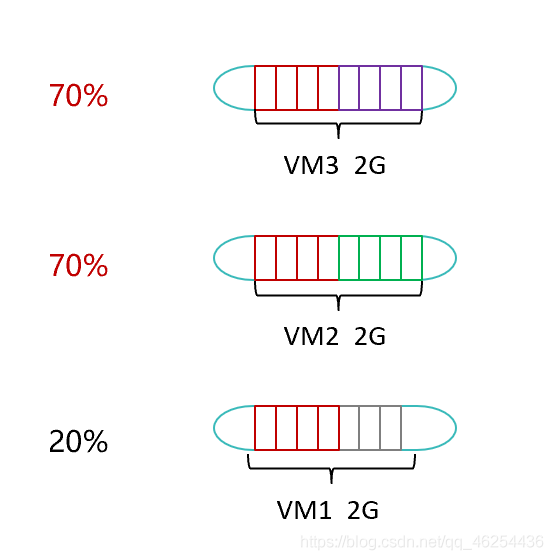
同样是三台虚拟机,每台虚拟机有2G的虚拟内存,然而VM1的内存利用率仅为20%,而VM2和VM3的内存利用率都到了70%(有的虚拟机业务没那么多,有的虚拟机负载比较大),此时,系统会自动将分配给VM1的物理内存在后台映射给VM2和VM3以达到缓解内存压力的效果。(将没有用的内存像气泡一样挤出来)
总结:系统主动回收虚拟机暂时不用的物理内存,分配给需要复用内存的虚拟机。内存的回收和分配均为系统动态执行,虚拟机上的应用无感知。整个物理服务器上的所有虚拟机使用的分配内存总量不能超过该服务器的物理内存总量。
内存置换
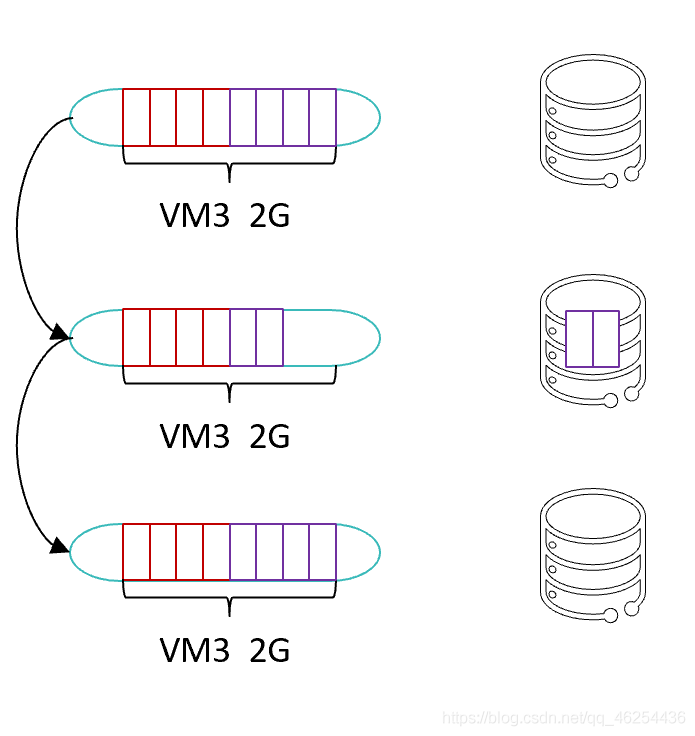
将外部存储虚拟成内存给虚拟机使用,将虚拟机上暂时不用的数据存放到外部存储上。系统需要使用这些数据时,再与预留在内存上的数据进行交换。(内存中有一部分数据不用,将数据先存到硬盘,(本来内存只有1G,现在可以使用2G)用的时候再又放回到内存上。)
内存置换类似于windows的虚拟内存和linux的swap分区的作用,都是使用存储模拟内存的功能,将一部分已被调用到内存但是使用频率很低的数据先放到磁盘中,当这些数据到用到的时候,这些数据会再被调回到内存中。
总结
在部分虚拟化产品中,比如FusionCompute中,内存复用是基于集群设置的,打开内存复用功能后,由内存复用策略接管物理内存的分配,在内存不紧张时虚拟机可以使用全部物理内存。当出现竞争时,由内存复用策略为虚拟机实时调度内存资源,综合运用内存复用技术释放虚拟机的空闲内存,为其它虚拟机的内存需求提供条件。
使用了内存复用后,可在一定程度上降低客户的成本。
- 当计算节点的内存数量固定时,可以提高计算节点的虚拟机密度。
- 当计算节点的虚拟机密度固定时,可以节省计算节点的内存数量。
但是有些地方是不建议开启内存复用的。开启了内存复用了之后,虚拟机分配的内存可能是小于实际分配到的内存的。这时候就造成虚拟机性能下降。
虚拟机特性介绍
虚拟机快速部署
我们前面的文章说了,虚拟化的本质就是将物理的服务器逻辑化成一个文件或者文件夹。每一个文件或者文件夹都会对应一个虚拟机。我们可以通过复制、移动文件夹来复制、移动虚拟机。复制就是形成了一个新的虚拟机
但是有一个问题:
复制的时候,原本虚拟机的资料、IP地址、用户名、MAC地址等都复制过去了。这些设备信息如果是一样的那么虚拟机就会造成地址冲突等一系列的问题,导致虚拟机不可以使用。
解决方法:
1. 重新创建新的虚拟机,但是很慢,浪费时间 2. 虚拟机的快速部署
虚拟机的快速部署分两种方式:按模板部署和虚拟机克隆。
模板部署
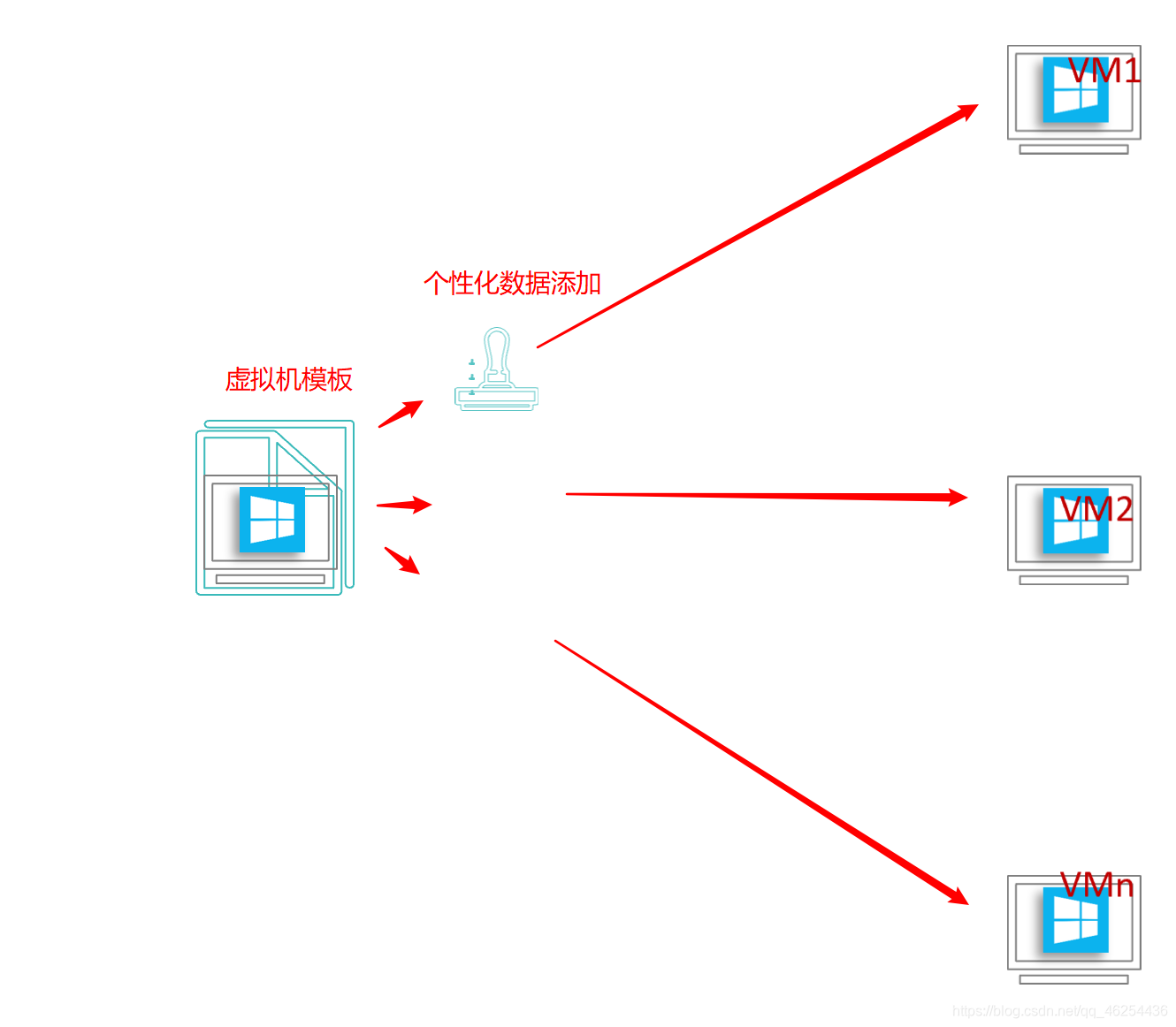
将一台虚拟机,转化成模板。模板不允许开机、启动(为了保证模板不被编辑、改变,同时永远不占用资源),模板的本质也是一台虚拟机,可以理解为虚拟机的副本,它同样包含了虚拟机磁盘和虚拟机的配置文件。但是不开机,不启动。所以不占用计算资源。
要建新的虚拟机的时候,就直接用模板部署
部署的时候,我们人为的给每一台虚拟机的加上个性化的信息(IP地址、用户、主机名等等信息)
优点
- 大幅度节省配置新虚拟机和安装操作系统的时间(普通创建大概要30~60分钟。模板部署只要几分钟)
- 可以一次性大量部署虚拟机
- 可以保持虚拟机的一致性,同时还可以自动将所需要更改的参数进行修改。
比如,现有一组测试人员需要对公司新开发的软件进行测试,那么管理员可以将安装了该软件的虚拟机制作为模板,然后快速部署出一批配置相同的虚拟机分配给不同的测试人员进行不同场景不同要求的测试,一旦测试过程中出现了任何问题,管理员可以删除故障的虚拟机,然后重新部署一台同样的虚拟机给测试人员。另外,不同的虚拟机模板中可以包含不同的软件,比如财务人员使用的模板可以预先安装好财务系统,销售人员的模板中可以安装ERP系统,使用这些不同的模板可以随时为对应部门的工作人员创建出符合他们需求的虚拟机。
模板的本质也是一台虚拟机,可以理解为虚拟机的一个副本,它同样包含了虚拟机磁盘和虚拟机的配置文件,使用模板创建虚拟机能够大幅节省配置新虚拟机和安装操作系统的时间。虚拟机模板创建后,不允许开机,也不允许启动,这样的设计是为了保证这个模板不会被其它随意的编辑而改变,同时它永远不占用集群的计算资源。使用模板部署出来的虚拟机和模板是相互独立的,如果想要更新或者重新编辑模板,需要先把模板转换为虚拟机才可,编辑完成后,再把虚拟机重新制作为模板。
虚拟机克隆
但是有些时候,我们也会需要包括个性化信息在内的所有信息都要一样的虚拟机。
除了模板部署虚拟机,使用虚拟机本身也可以快速的部署出一台虚拟机,这个功能称为虚拟机克隆。
与使用模板部署不同,虚拟机克隆是在某个时间点对源虚拟机进行完全的复制,每个被克隆出来的虚拟机的所有设置,包括主机名、IP地址等个性化数据,都和源虚拟机一模一样。我们都知道,如果局域网中出现了两个完全一致的IP地址,系统会自动报错,所以,克隆出来的虚拟机最好不要同时开机。

虚拟机资源热添加
此处的热添加指的是在虚拟机开机状态下为虚拟添加计算、存储和网络资源。
在我们的个人电脑,开机的状态下。比如我们正在玩游戏,发现画面怎么这么卡?然后发现问题是内存不够,CPU太老了。但是在开机的状态下我们什么都干不了。
那么为什么虚拟机能干呢?
从管理员的角度,虚拟机的CPU、内存等参数都是配置文件里的一部分,我们可以通过修改配置文件中对应参数,来修改虚拟机的硬件配置。
假设用户在使用虚拟机的过程中,CPU和内存的使用率达到了75%,用户侧的体验可能会非常不好,甚至有可能会影响正常的使用,这时,使用虚拟机资源热添加的功能,可以为该虚拟机在线添加CPU和内存资源,使客户侧的资源利用率快速降到正常水平。
除了CPU和内存,存储资源和网络资源也支持热添加。比如对虚拟机磁盘扩容、为虚拟机增加网卡等。
注意
-
除了需要虚拟机本身支持热添加的功能,虚拟机的操作系统也要支持,才能使热添加上的资源立刻生效,否则,需要重启虚拟机,经过操作系统对硬件资源的识别后才可以使用。
-
大部分情况下,**资源只支持热添加,而不支持减少。**比如,管理员要将虚拟机的一个磁盘从10G扩容到20G可以,但是从20G减容到10G则不一定可以执行。
-
对存储资源的添加,除了可以对已有的磁盘进行扩容外,还支持为虚拟机增加不同的磁盘。
虚拟机Console控制
虚拟机不像物理机,可以使用显示器进行操作,一旦网络不通或者其它原因,很有可能就无法进行控制,这时就需要一种新的技术随时对虚拟机进行控制。
有些 朋友可能知道:Telnet、SSH远程控制、远程桌面。但是有个问题:新安装的操作系统没有IP地址,没有远程控制服务。
所以大部分不能通过接显示系统的硬件设备都会单独配置一个管理接口供用户进行管理操作,比如存储设备除了业务接口还有控制口、网络设备都会配置Console口等等,那么虚拟机能不能也使用同样的方式呢?答案是肯定的。
各个虚拟机厂商都为虚拟机配置了Console管理的功能,比如VMware使用的是Remote Console,华为和KVM使用的VNC的方式。使用Console不代表不依赖网络,Console登录虚拟机时,虚拟机可以不配置IP地址,但是虚拟机所在的计算节点需要配置IP地址,并且该计算节点会作为服务端,为用户登录虚拟机提供服务,所以,用户端和服务端之间的网络需要通讯正常。
虚拟机快照
在日常的生活中,我们会使用拍照记录生活中的美好时刻,在虚拟化中,虚拟机的“快照”和我们生活中的拍照非常相似,可以记录某一时刻虚拟机的状态,照片可以留下那一刻的美好,快照也可以将虚拟机完全保留。通过照片我们可以找回曾经的岁月和记忆,通过快照,我们也可以将虚拟机恢复到那一刻的状态。
虚拟机快照一般应用在当对虚拟机进行升级、打补丁、测试等破坏性试验前,一旦虚拟机出现了故障,使用快照可以对虚拟机进行迅速恢复。虚拟机快照功能是通过存储系统来完成的,SNIA(存储网络行业协会)对快照(Snapshot)的定义是:关于指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的映像。快照可以是其所表示的数据的一个副本,也可以是数据的一个复制品。
快照技术有如下特点:
快照可迅速生成,并可用作传统备份和归档的数据源,缩小甚至消除了数据备份的窗口。
快照存储在磁盘上,可以快速直接存取,提高了数据恢复的速度。
基于磁盘的快照使存储设备有灵活和频繁的恢复点,可以快速通过不同时间点的快照简易恢复意外擦除或损坏的数据,对其进行在线数据恢复。
从具体的技术细节来讲,快照建立一个指针列表,指示读取数据的地址,当数据改变时,该指针列表能够在极短时间内提供一个实时数据,并进行复制。
常见的快照模式分为两种:写前拷贝(COW,Copy-On-Write)快照和写时重定向(ROW,Redirect-On-Write)快照。COW和ROW都属于存储领域的知识,大部分厂商在创建虚拟机快照时使用的是ROW技术,无论是COW还是ROW都不会发生真正的物理拷贝的动作,只是做映射上的修改。
NUMA
NUMA,全称为非统一内存访问(Non Uniform Memory Access Architecture),它是一种可以提高数据读写速度的技术。
简单的来说,NUMA就是给CPU和内存做绑定。内存和CPU做了绑定,CPU从绑定的内存(Local Access)中读取数据的响应时间较短,而如果跨CPU访问内存(Remote Access)读取数据的响应时间较长,既然Local Access速度快,那么就让程序在运行时全部使用一个CPU和与其相绑定的内存,这样就可以提高工作效率,这就是NUMA。
使用了NUMA后,它会把CPU和与其绑定的内存当做一个NUMA Node,每个node都有自己内部CPU、总线和内存,如果跨Node进行访问,需通过CPU之间的Interconnect。
对应到虚拟化中,使用NUMA技术可以让虚拟机使用同一NUMA Node上的硬件资源,以提高虚拟机的响应速度。
- 点赞 2
- 收藏
- 分享
- 文章举报
 TKE_Skye
发布了15 篇原创文章 · 获赞 22 · 访问量 2994
私信
关注
TKE_Skye
发布了15 篇原创文章 · 获赞 22 · 访问量 2994
私信
关注

- 宏汇编有专门的介绍书本,这里介绍宏的通用特性,(宏的高级特性总结)
- RHEL 7特性说明(五):虚拟化
- RHEL 7特性说明(五):虚拟化
- 【UWP通用应用开发】开发准备、部分新特性
- 虚拟化架构中小型机构通用虚拟化架构
- Redis学习(四)Redis的特性和Keys的通用操作
- vsphere虚拟化的优点、组成、特性
- redis两个功能特性--通用活动系统
- MySQL 8.0 新特性之通用表表达式
- OpenGL高级特性之利用Image内存模型&计算着色器&原子操作实现(直方图模型)通用计算
- RHEL 6.5 中的KVM虚拟化新特性
- 新锐OA特性专题 - 通用文件在线编辑
- 细说浏览器特性检测(2)-通用事件检测
- RHEL 6.5 中的KVM虚拟化新特性
- 【转载】云计算环境下的 JVM 虚拟化特性初探
- RHEL 6.6 虚拟化新特性
- 细说浏览器特性检测(2)-通用事件检测
- 虚拟化学习笔记-目前流行的虚拟机软件的迁移特性
- RHEL 6.6 虚拟化新特性
- vSphere 6.7 新特性 — 基于虚拟化的安全 (VBS)