python爬虫实战(1)
python爬虫实战(1)———访问网页及更改编码格式
疫情期间在家闲着没事,找到本科时的课本,随手翻了翻还是挺有意思的。在此将自己重新学习的新感受记录下来,方便以后查阅,如能帮助到广大的初学者朋友,将是莫大的荣幸。
1.网络爬虫
网络爬虫,又称为网页蜘蛛(WebSpider),如果我们把整个互联网想象成类似于蜘蛛网一样的构造,那么这只爬虫,就是要在互联网这张大网上爬来爬去,以便捕获我们需要的资源。
我们之所以能够通过百度或者谷歌等搜索引擎检索到我们要浏览的网页,靠的就是他们大量的爬虫每天在互联网上爬来爬去,对网页中的每个关键词进行索引,建立索引数据库。经过复杂的算法进行排序后,将这些结果按照与搜索关键词的相关度高低,依此排列。
使用Python编写爬虫代码,要解决的第一个问题是:如何用python访问互联网?要解决这个问题,就要用到一个模块——urllib模块。
2.urllib模块
urllib,是URL和lib两个单词共同构成的:URL,Uniform Resource Locator,统一资源定位符,也就是我们通常所说的网页地址;lib,是library(库)的缩写,里面有很多我们需要用到的工具或是代码块。通过lib我们可以方便的调用这些工具或代码块而简化我们的代码。
URL的一般格式为(在方括号[ ]内的为可选项):protocol://hostname[port]/path/[;parameters][?query]#fragment。
URL由三部分组成:
(1)protocol(协议):常见的有http(HyperText Transfer Protocol,超文本传输协议)、https(Hyper Text Transfer Protocol over SecureSocket Layer,超文本传输安全协议)、ftp(File Transfer Protocol,文件传输协议)、file(访问本地文件夹)、ed2k(电驴的专用链接)等等。
(2)hostname:存放资源的服务器的域名系统(DNS)主机名或IP地址(有时候要包含端口号,各种传输协议都有默认的端口号,如http的默认端口为80).
(3)path:主机资源的具体地址,如目录和文件名等。
第一部分和第二部分用“://”符号隔开,
第二部分和第三部分用“/”符号隔开。
第一部分和第二部分是不可缺少的,第三部分有时可以省略,如百度的地址 : https://www.baidu.com/
Python3对urllib模块做了挺大的改动,将以前的urllib模块还有一个urllib2模块(对urllib模块的补充)合在了一起,统一叫urllib。它是一个包(package)。
打开参考文件看一下:
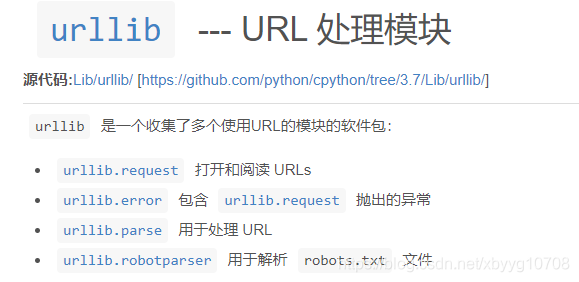
urllib是一个包,里边总共有四个模块。第一个模块urllib.request是最复杂的也是最重要的,因为它包含了对服务器请求的发出、跳转、代理和安全等各个方面。
先来体验一下,通过urllib.request.urlopen()函数就可以访问网页了,以编辑时的网页地址为例:
import urllib.request#导入urllib.request模块
response = urllib.request.urlopen("https://editor.csdn.net/md?articleId=104576075")#用于实现对目标url的访问
html = response.read()
print(html)
运行一下,得到如下结果:

细心的朋友们可能发现了,这跟我们在浏览器上使用“审查元素”或者按F12所看到的内容不太一样。
其实python爬取的内容是以utf-8编码的bytes对象,要还原为带中文的html代码,需要对其进行解码,将它变成Unicode编码:
html = html.decode("utf-8")
print(html)
转码之后的内容

以上就是python爬虫实战(1)———访问网页及更改编码格式的全部内容啦,第一次写博客,还很生疏,希望各位看官老爷们提出批评指正,感激不尽
- 点赞
- 收藏
- 分享
- 文章举报
 xbyyg10708
发布了2 篇原创文章 · 获赞 0 · 访问量 54
私信
关注
xbyyg10708
发布了2 篇原创文章 · 获赞 0 · 访问量 54
私信
关注

- 最新Python案例带你全面掌握商业爬虫项目实战(完整)
- python爬虫实战——图片自动下载器
- python3[爬虫实战] 使用selenium,xpath爬取京东手机(下)
- 分享python3爬虫及数据分析实战视频教程
- Python爬虫实战(1):爬取糗事百科段子
- python爬虫学习实战
- python爬虫实战-爬取岗位招聘信息并保存至本地(方法、bs4)
- python爬虫实战——5分钟做个图片自动下载器
- python爬虫实战-爬取岗位招聘信息并保存至本地(方法、jsonpath)
- Python爬虫实战之豆瓣音乐、微打赏、阳光电影(附代码)
- Python3网络爬虫实战-44、点触点选验证码的识别
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
- python爬虫实战 | 爬取豆瓣TOP250排名信息
- 2019最新《七月在线python爬虫项目班项目实战》
- Python爬虫实战之爬取糗事百科段子
- Python爬虫实战(一):爬取豆瓣电影top250排名
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第5章 scrapy爬取知名问答网站(1)
- python爬虫实战(一)----------爬取京东商品信息
- python爬虫实战--爬取猫眼专业版-实时票房
- python实战网络刷博器爬虫源码奉献