初学python爬虫,记录一下学习过程,requests xpath os 提取MM图片并保存本地 03
众所周知,学习python,不,学习爬虫,爬取图片就是练练技术,是通往大师路上的阶梯,什么MM图啊,什么斗图啊,就是练技术的,就算爬取下来咱也不会看的。嗯,对,不会看的。

好,言归正传,第一次爬取的图片就只是把首页的图片爬取下来了,并没有爬取详情页的图片,还是不爽的。看的正舒服,换人就扫兴了。对,我是不看的,所以爬到什么我也不知道。

第一次爬取可参考:
第一次的爬取
首页爬取下来看不到详情页得是多大的遗憾啊,所以改进了代码,复制详情页的地址,提取全部详情页的图片,这就出来了第二次爬取。第二次爬取可参考:
第二次的爬取
但每次都得进入详情页,复制详情页的地址,还得输入到Pycharm,像我这么懒的,就更不想输了,虽说有。。。

还是慢慢输吧!!!
但实在是太多了,这得弄到啥时间了。得想个法子啊。

So,重新改进代码,提取到搜索框的地址,找到规律,发现就只有两个参数再变,这就好办了,构造url就完了,


改变就只有这两个参数,转到第一页的时候page=1了,这不就不是事了。

构造完成
接下来就是请求,解析了。请求解析可以参考第一次和第二次的爬取,本来一切顺利,但到详情页的时候发现第一页的地址和后面的详情页的竟然不一样。

第一页的地址:

第二页的地址:

而且参数还在里面,只能用 if 单独处理了,后面得url只能拆解,拼装了,代码如下。
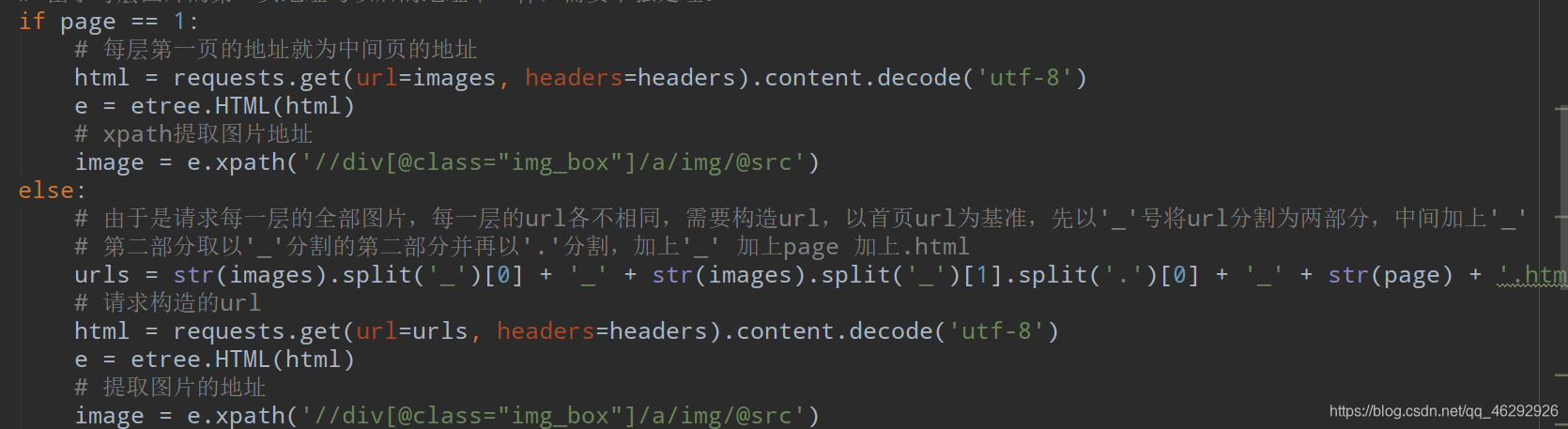
成功拿到搜索人物的在本网站的所有图片的地址。
但又有问题了,还是得进入网站,找到要下载的人物名称,然后在构造搜索的url中输入名称,还是可麻烦啊。所以想到用 input 输入,在pycharm中直接完成,这样就不用在入网站了
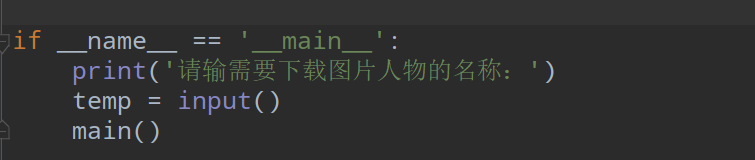
大功告成!!!
先试一下。。。
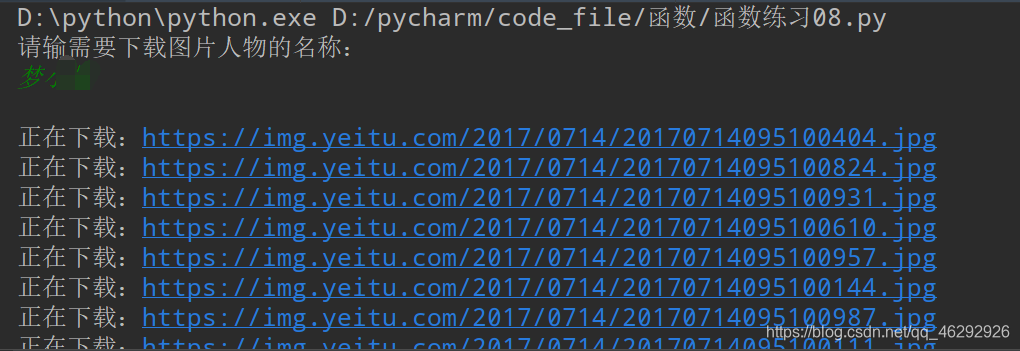
文件也新建并存储成功

最后:
本篇只是单线程爬取,不适合爬取页数比较多的,不然会运行很长时间的。
再让你们看看爬取的数量



还有很多,就不一一贴出来了。还有,保重圣体。。。
完整代码奉上:
'''
requests库请求目标网址
xpath提取网页的图片地址
os模块建立文件夹存储图片
面向函数编程
'''
# 导入第三方库
import requests
from lxml import etree
import time
import os
# useragent库
from fake_useragent import UserAgent
# 定义随机的UserAgent
ua = UserAgent()
headers = {'User-Agent':ua.random}
# 定义得到搜索页的html的函数
def get_html(url):
time.sleep(1)
# 如果用.text()则出现乱码的情况,所以采用utf-8方式解码
html = requests.get(url,headers = headers).content.decode('utf-8')
return html
# 定义解析中间页函数
def mid_paser_html(html):
data01 = []
e = etree.HTML(html)
# 提取详情页的url地址
details_list = e.xpath('//div[@class="list_box_info"]/h5/a/@href')
for details_page in details_list:
data01.append(details_page)
return data01
# 定义解析最终图片的函数
def f_paser_html(data01):
details = {}
detail = []
for images in data01:
html01 = requests.get(url=images,headers = headers).content.decode('utf-8')
e = etree.HTML(html01)
# 提取每一层图片的总页数
nums = e.xpath('//div[@class="imageset"]/span[@class="imageset-sum"]/text()')
for page in range(1, int(nums[0].split(' ')[1])):
# 由于每层图片的第一页地址与以后的地址不一样,需要单独处理。
if page == 1:
# 每层第一页的地址就为中间页的地址
html = requests.get(url=images, headers=headers).content.decode('utf-8')
e = etree.HTML(html)
# xpath提取图片地址
image = e.xpath('//div[@class="img_box"]/a/img/@src')
else:
# 由于是请求每一层的全部图片,每一层的url各不相同,需要构造url,以首页url为基准,先以'_'号将url分割为两部分,中间加上'_'
# 第二部分取以'_'分割的第二部分并再以'.'分割,加上'_' 加上page 加上.html
urls = str(images).split('_')[0] + '_' + str(images).split('_')[1].split('.')[0] + '_' + str(page) + '.html'
# 请求构造的url
html = requests.get(url=urls, headers=headers).content.decode('utf-8')
e = etree.HTML(html)
# 提取图片的地址
image = e.xpath('//div[@class="img_box"]/a/img/@src')
# 加入字典
details['image'] = image
# 遍历循环字典,添加到列表中
for det in details['image']:
detail.append(det)
return detail
def save_images(detail):
# 创建文件夹
if not os.path.exists(temp):
os.mkdir(temp)
for image in detail:
# 请求每一张图片的url
r = requests.get(url=image, headers=headers)
# 定义每一张图片的名字
file_name = image.split('/')[-1]
print('正在下载:'+ image )
# 写入图片文件
with open(temp + '/' + file_name, 'wb') as f:
f.write(r.content)
def main():
# 翻页
for page in range(1,2):
url = 'https://www.yeitu.com/index.php?m=search&c=index&a=init&typeid=&siteid=1&q={}&page=%d'.format(temp) %page
html = get_html(url)
data01 = mid_paser_html(html)
detail = f_paser_html(data01)
save_images(detail)
if __name__ == '__main__':
print('请输需要下载图片人物的名称:')
temp = input()
main()
- 点赞
- 收藏
- 分享
- 文章举报
 warm...
发布了18 篇原创文章 · 获赞 14 · 访问量 1483
私信
关注
warm...
发布了18 篇原创文章 · 获赞 14 · 访问量 1483
私信
关注

- python爬虫实战-爬取美女图片并保存至本地文件夹(xpath)
- Python 爬虫抓取美女图片保存到本地
- 萌新的Python学习日记 - 爬虫无影 - 使用BeautifulSoup + urlretrieve 抓取并保存图片:weheartit
- python爬虫实战-爬取笑话大全并保存至本地(xpath)
- Python爬虫:多进程爬取网上图片并下载到本地,并将相关信息保存到mongodb数据库中
- Python之BeautifulSoup学习之三 读取本地html文件,并将其中图片保存下来
- 不务正业--用python爬虫抓取Konachan的图片并保存到本地文件
- 《零基础入门学习Python》学习过程笔记【54用python保存一张网站上的图片】
- Python爬虫获取图片并下载保存至本地的实例
- 【Python3.6爬虫学习记录】(四)爬取百度贴吧某帖子内容及图片
- python学习过程中的知识点,记录一下
- python爬虫实战-爬取城市每条公交详细信息并保存至本地(方法、xpath)
- Python爬虫基础之requests+BeautifulSoup+Image 爬取图片并存到本地(五)
- python入门012~使用requests爬取网络图片并保存到本地
- Python爬虫获取图片并下载保存至本地
- 【Python3.6爬虫学习记录】(三)简单的爬虫实践-豆瓣《河神》演员图片及姓名
- 【极客学院】-python学习笔记-3-单线程爬虫 (request安装遇到问题及解决,应用requests提取信息)
- [Python]使用Scrapy爬虫框架简单爬取图片并保存本地
- Python 爬虫多线程爬取美女图片保存到本地