深度学习入门笔记(十四):Softmax
欢迎关注WX公众号:【程序员管小亮】
专栏——深度学习入门笔记
声明
1)该文章整理自网上的大牛和机器学习专家无私奉献的资料,具体引用的资料请看参考文献。
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
3)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
4)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
文章目录
深度学习入门笔记(十四):Softmax
1、Softmax 回归
- 如果是二分分类的话,只有两种可能的标记——0或1,如果是猫咪识别例子,答案就是:这是一只猫或者不是一只猫;
- 如果有多种可能的类型的话呢?有一种 logistic 回归的一般形式,叫做 Softmax 回归,能在试图识别某一分类时做出预测,或者说是多种分类中的一个,不只是识别两个分类,一起看一下。
假设不单单需要识别猫,而是想识别猫,狗和小鸡,其中把猫称为类1,狗为类2,小鸡是类3,如果不属于以上任何一类,就分到“其它”或者说“以上均不符合”这一类,把它称为类0。

这里显示的图片及其对应的分类就是一个例子,这幅图片上是一只小鸡,所以是类3,猫是类1,狗是类2,如果猜测是一只考拉,那就是类0,下一个小鸡,类3,以此类推。假设用符号大写的 CCC 来表示输入会被分的类别总个数,那么在这个例子中,共有4种可能的类别,包括猫、狗、小鸡,还有“其它”或“以上均不符合”这一类。当有这4个分类时,指示类别的数字就是从0到 C−1C-1C−1,换句话说就是0、1、2、3。
如果在这个例子中想要建立一个神经网络,那么其输出层需要有4个,或者说 CCC 个输出单元,如图:
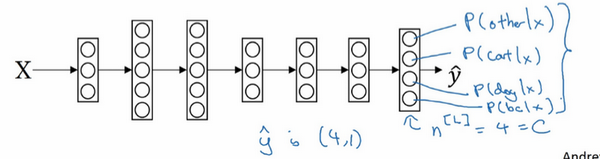
我们想要输出层单元通过数字的方式,告诉我们这4种类型中判别为每个类别的概率有多大,所以这里的:
- 第一个节点输出的应该是或者说希望它输出“其它”类的概率;
- 第二个节点输出的应该是或者说希望它输出猫的概率;
- 第三个节点输出的应该是或者说希望它输出狗的概率;
- 第四个节点输出的应该是或者说希望它输出小鸡的概率;
因此这里的输出 y^\hat yy^ 将是一个 4×14×14×1 维向量,它必须输出四个数字,代表四种概率,并且输出中的四个数字加起来应该等于1才对。如果想让网络做到这一点,那么需要用到的标准模型是 Softmax 层,以及输出层来生成输出。
在神经网络的最后一层,z[l]z^{[l]}z[l] 是最后一层的 zzz 变量,计算方法是:
z[l]=W[l]a[L−1]+b[l]z^{[l]} = W^{[l]}a^{[L-1]} + b^{[l]}z[l]=W[l]a[L−1]+b[l]
算出了 zzz 之后就需要应用 Softmax 激活函数了,这个激活函数对于 Softmax 层而言是有些不同,它的作用是这样的:
- 首先,计算一个临时变量 t=ez[l]t=e^{z^{[l]}}t=ez[l],这适用于每个元素,而这里的 z[l]z^{[l]}z[l],在我们的例子中,z[l]z^{[l]}z[l] 是4×1的,四维向量 t=ez[l]t=e^{z^{[l]}}t=ez[l],这是对所有元素求幂;
- 然后计算输出的 a[l]a^{[l]}a[l],基本上就是向量 ttt,但是要做归一化,使和为1,计算公式 a[l]=ti∑j=14ti=ez[l]∑j=14tia^{[l]} = \frac{t_{i}}{\sum_{j =1}^{4}t_{i}} = \frac{e^{z^{[l]}}}{\sum_{j =1}^{4}t_{i}}a[l]=∑j=14titi=∑j=14tiez[l]。
你可能不是很懂这个意思,别担心,来看一个例子,详细解释一下上面的公式。
假设算出了z[l]z^{[l]}z[l],z[l]=[52−13]z^{[l]} = \begin{bmatrix} 5 \\ 2 \\ - 1 \\ 3 \\ \end{bmatrix}z[l]=⎣⎢⎢⎡52−13⎦⎥⎥⎤,我们要做的就是用上面的方法来计算 ttt,所以 t=[e5e2e−1e3]t =\begin{bmatrix} e^{5} \\ e^{2} \\ e^{- 1} \\ e^{3} \\ \end{bmatrix}t=⎣⎢⎢⎡e5e2e−1e3⎦⎥⎥⎤,当然如果按一下计算器的话,就会得到以下值 t=[148.47.40.420.1]t = \begin{bmatrix} 148.4 \\ 7.4 \\ 0.4 \\ 20.1 \\ \end{bmatrix}t=⎣⎢⎢⎡148.47.40.420.1⎦⎥⎥⎤。对向量 ttt 归一化就能得到向量 a[l]a^{[l]}a[l],方法是把 ttt 的元素都加起来,得到176.3,计算公式是 a[l]=t176.3a^{[l]} = \frac{t} {176.3}a[l]=176.3t,即可得:
- 第一个节点,输出 e5176.3=0.842\frac{e^{5}}{176.3} =0.842176.3e5=0.842,这意味着,这张图片是类0的概率就是84.2%。
- 第二个节点,输出 e2176.3=0.042\frac{e^{2}}{176.3} =0.042176.3e2=0.042,这意味着,这张图片是类1的概率就是4.2%。
- 第三个节点,输出 e−1176.3=0.002\frac{e^{- 1}}{176.3} =0.002176.3e−1=0.002,这意味着,这张图片是类2的概率就是0.2%。
- 最后一个节点,输出 e3176.3=0.114\frac{e^{3}}{176.3} =0.114176.3e3=0.114,也就是这张图片是类3的概率就是11.4%,也就是小鸡组,对吧?
这就是它属于类0,类1,类2,类3的可能性。
神经网络的输出 a[l]a^{[l]}a[l],也就是 y^\hat yy^,是一个4×1维向量,就是算出来的这四个数字([0.8420.0420.0020.114]\begin{bmatrix} 0.842 \\ 0.042 \\ 0.002 \\ 0.114 \\ \end{bmatrix}⎣⎢⎢⎡0.8420.0420.0020.114⎦⎥⎥⎤),所以这种算法通过向量z[l]z^{[l]}z[l]计算出总和为1的四个概率。
Softmax 分类器还可以代表其它的什么东西么?
举几个例子,假设有两个输入 x1x_{1}x1,x2x_{2}x2,它们直接输入到 Softmax 层,有三四个或者更多的输出节点,输出 y^\hat yy^。如果是一个没有隐藏层的神经网络,就是计算 z[1]=W[1]x+b[1]z^{[1]} = W^{[1]}x + b^{[1]}z[1]=W[1]x+b[1],而输出的 a[l]a^{[l]}a[l],或者说 y^\hat yy^,a[l]=y=g(z[1])a^{[l]} = y = g(z^{[1]})a[l]=y=g(z[1]),就是 z[1]z^{[1]}z[1] 的 Softmax 激活函数。
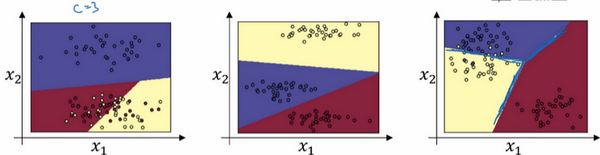
这个例子中(左边图),原始输入只有 x1x_{1}x1 和 x2x_{2}x2,一个 C=3C=3C=3 个输出分类的 Softmax 层能够代表这种类型的决策边界,请注意这是几条线性决策边界,但这使得它能够将数据分到3个类别中。在这张图表中,我们所做的是选择这张图中显示的训练集,用数据的3种输出标签来训练 Softmax 分类器,图中的颜色显示了 Softmax 分类器的输出阈值,输入的着色是基于三种输出中概率最高的那种。因此可以看到这是 logistic 回归的一般形式,有类似线性的决策边界,但有超过两个分类,分类不只有0和1,而是可以是0,1或2。中间图是另一个 Softmax 分类器可以代表的决策边界的例子,用有三个分类的数据集来训练,还有右边图也是。
但是直觉告诉我们,任何两个分类之间的决策边界都是线性的,这就是为什么可以看到,比如黄色和红色分类之间的决策边界是线性边界,紫色和红色之间的也是线性边界,紫色和黄色之间的也是线性决策边界,但它能用这些不同的线性函数来把空间分成三类。
我们来看一下更多分类的例子:
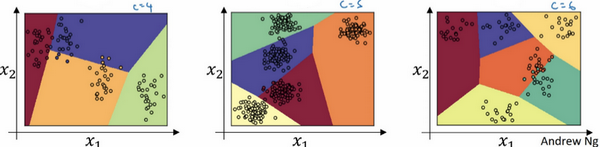
这个例子中(左边图)C=4C=4C=4,因此这个绿色分类和 Softmax 仍旧可以代表多种分类之间的这些类型的线性决策边界。另一个例子(中间图)是 C=5C=5C=5 类,最后一个例子(右边图)是 C=6C=6C=6,这显示了 Softmax 分类器在没有隐藏层的情况下能够做到的事情,当然更深的神经网络会有 xxx,然后是一些隐藏单元,以及更多隐藏单元等等,因此可以学习更复杂的非线性决策边界,来区分多种不同分类。
2、训练一个 Softmax 分类器
如何学习训练一个使用了 Softmax 层的模型?
回忆之前举的的例子,输出层计算出的 z[l]z^{[l]}z[l] 如下,z[l]=[52−13]z^{[l]} = \begin{bmatrix} 5 \\ 2 \\ - 1 \\ 3 \\ \end{bmatrix}z[l]=⎣⎢⎢⎡52−13⎦⎥⎥⎤,输出层的激活函数 g[L]()g^{[L]}()g[L]() 是 Softmax 激活函数,那么输出就会是这样的:
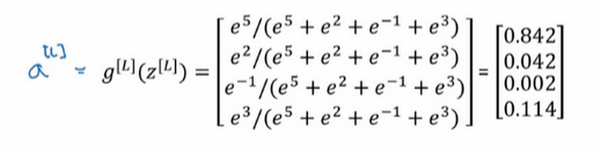
简单来说就是归一化,使总和为1,注意到向量 zzz 中,最大的元素是5,而最大的概率也就是第一种概率,为啥会这样?

这要从头讲起,Softmax 这个名称的来源是与所谓 hardmax 对比,hardmax 会把向量 zzz 变成这个向量 [1000]\begin{bmatrix} 1 \\ 0 \\ 0 \\ 0 \\ \end{bmatrix}⎣⎢⎢⎡1000⎦⎥⎥⎤,hardmax 函数会观察 zzz 的元素,然后在 zzz 中最大元素的位置放上1,其它位置放上0。
与之相反,Softmax 所做的从 zzz 到这些概率的映射更为温和,不知道这是不是一个好名字,但至少这就是 softmax 这一名称背后所包含的想法,与 hardmax 正好相反。
有一点没有细讲,但之前已经提到过的,就是 Softmax 回归或 Softmax 激活函数将 logistic 激活函数推广到 CCC 类,而不仅仅是两类,如果 C=2C=2C=2,那么 Softmax 变回了 logistic 回归。
接下来看怎样训练带有 Softmax 输出层的神经网络,具体而言,先定义训练神经网络使会用到的损失函数。举个例子,看看训练集中某个样本的目标输出,真实标签是 [0100]\begin{bmatrix} 0 \\ 1 \\ 0 \\ 0 \\ \end{bmatrix}⎣⎢⎢⎡0100⎦⎥⎥⎤,这表示这是一张猫的图片,因为它属于类1,现在假设神经网络输出的是 y^\hat yy^,y^\hat yy^ 是一个包括总和为1的概率的向量,y=[0.30.20.10.4]y = \begin{bmatrix} 0.3 \\ 0.2 \\ 0.1 \\ 0.4 \\ \end{bmatrix}y=⎣⎢⎢⎡0.30.20.10.4⎦⎥⎥⎤,总和为1,这就是 a[l]a^{[l]}a[l],a[l]=y=[0.30.20.10.4]a^{[l]} = y = \begin{bmatrix} 0.3 \\ 0.2 \\ 0.1 \\ 0.4 \\ \end{bmatrix}a[l]=y=⎣⎢⎢⎡0.30.20.10.4⎦⎥⎥⎤。所以你可以明显看到对这个样本来说神经网络的表现不佳,这实际上是一只猫,但是猫的概率却只有20%。
那么用什么损失函数来训练这个神经网络?
在 Softmax 分类中,一般用到的损失函数是 L(y^,y)=−∑j=14yjlogy^jL(\hat y,y ) = - \sum_{j = 1}^{4}{y_{j}log\hat y_{j}}L(y^,y)=−∑j=14yjlogy^j,现在用上面的样本来验证一下,方便更好地理解整个过程。注意在这个样本中 y1=y3=y4=0y_{1} =y_{3} = y_{4} = 0y1=y3=y4=0,因为这些都是0,只有 y2=1y_{2} =1y2=1,所以如果看这个求和,所有含有值为0的 yjy_{j}yj 的项都等于0,最后只剩下 −y2tlogy^2-y_{2}t{log}\hat y_{2}−y2tlogy^2,因为当按照下标 jjj 全部加起来,所有的项都为0,除了 j=2j=2j=2 时,又因为 y2=1y_{2}=1y2=1,所以它就等于 − logy^2- \ log\hat y_{2}− logy^2。即:
L(y^,y)=−∑j=14yjlogy^j=−y2 logy^2=− logy^2L\left( \hat y,y \right) = - \sum_{j = 1}^{4}{y_{j}\log \hat y_{j}} = - y_{2}{\ log} \hat y_{2} = - {\ log} \hat y_{2}L(y^,y)=−j=1∑4yjlogy^j=−y2 logy^2=− logy^2
这就意味着,如果学习算法试图将损失函数变小,就是使 −logy^2-{\log}\hat y_{2}−logy^2 变小,要想做到这一点,就需要使 y^2\hat y_{2}y^2 尽可能大,logloglog 函数虽然是递增的,但是 −log-log−log 函数是递减的,这就讲得通了。又因为在这个例子中 xxx 是猫的图片,就需要猫这项输出的概率尽可能地大(y=[0.30.20.10.4]y= \begin{bmatrix} 0.3 \\ 0.2 \\ 0.1 \\ 0.4 \\ \end{bmatrix}y=⎣⎢⎢⎡0.30.20.10.4⎦⎥⎥⎤ 中第二个元素)。
概括一下,损失函数所做的就是找到训练集中的真实类别,然后试图使该类别相应的概率尽可能地高,如果你熟悉统计学中最大似然估计,这其实就是最大似然估计的一种形式。但如果你不知道那是什么意思,也不用担心,用刚讲过的算法思维也足够理解了。
上面所讲的,是单个训练样本的损失,那么整个训练集的损失 JJJ 又如何呢?也就是设定参数的代价之类的,还有各种形式偏差的代价,还是和之前讲过的一样,你大致也能猜到,就是整个训练集损失的总和,把训练算法对所有训练样本的预测都加起来:
J(w[1],b[1],……)=1m∑i=1mL(y^(i),y(i))J( w^{[1]},b^{[1]},\ldots\ldots) = \frac{1}{m}\sum_{i = 1}^{m}{L( \hat y^{(i)},y^{(i)})}J(w[1],b[1],……)=m1i=1∑mL(y^(i),y(i))
因此用梯度下降法,使损失最小化。
最后还有一个实现细节,注意!因为 C=4C=4C=4,yyy 是一个4×1向量,如果向量化,矩阵大写 YYY 就是 [y(1)y(2)…… y(m)]\lbrack y^{(1)}\text{}y^{(2)}\ldots\ldots\ y^{\left( m \right)}\rbrack[y(1)y(2)…… y(m)],举个例子,如果上面的样本是第一个训练样本,那么矩阵 Y=[001…100…010…000…]Y =\begin{bmatrix} 0 & 0 & 1 & \ldots \\ 1 & 0 & 0 & \ldots \\ 0 & 1 & 0 & \ldots \\ 0 & 0 & 0 & \ldots \\ \end{bmatrix}Y=⎣⎢⎢⎡010000101000…………⎦⎥⎥⎤,那么这个矩阵 YYY 最终就是一个 4×m4×m4×m 维矩阵。
类似的,Y^=[y^(1)y^(2)…… y^(m)]\hat{Y} = \lbrack{\hat{y}}^{(1)}{\hat{y}}^{(2)} \ldots \ldots\ {\hat{y}}^{(m)}\rbrackY^=[y^(1)y^(2)…… y^(m)],其实就是 y^(1){\hat{y}}^{(1)}y^(1)(a[l](1)=y(1)=[0.30.20.10.4]a^{[l](1)} = y^{(1)} = \begin{bmatrix} 0.3 \\ 0.2 \\ 0.1 \\ 0.4 \\ \end{bmatrix}a[l](1)=y(1)=⎣⎢⎢⎡0.30.20.10.4⎦⎥⎥⎤),那么 Y^=[0.3…0.2…0.1…0.4…]\hat{Y} = \begin{bmatrix} 0.3 & \ldots \\ 0.2 & \ldots \\ 0.1 & \ldots \\ 0.4 & \ldots \\ \end{bmatrix}Y^=⎣⎢⎢⎡0.30.20.10.4…………⎦⎥⎥⎤,Y^\hat{Y}Y^ 本身也是一个 4×m4×m4×m 维矩阵。
最后还是来看一下,在有 Softmax 输出层时,如何实现梯度下降法,这个输出层会计算 z[l]z^{[l]}z[l],它是 C×1C×1C×1 维的,在上面的例子中是4×1,然后用 Softmax 激活函数来得到 a[l]a^{[l]}a[l] 或者说 yyy,然后又能由此计算出损失。具体操作还是和之前见过的反向传播一样,不懂或者忘记的同学可以去查阅一下前面的笔记。
关于具体如何实现这个函数,下次课会开始使用一种深度学习编程框架,对于这些编程框架,通常只需要专注于把前向传播做对即可,编程框架它自己会弄明白怎样反向传播,这也是为什么很多人被称为调包侠的原因,因为编程框架会帮你搞定导数计算。
给一个
Python实现
softmax的小例子,理解理解公式:
# softmax函数,将线性回归值转化为概率的激活函数。 # 输入s要是行向量 def softmax(s): return np.exp(s) / np.sum(np.exp(s), axis=1)
推荐阅读
- 深度学习入门笔记(一):深度学习引言
- 深度学习入门笔记(二):神经网络基础
- 深度学习入门笔记(三):求导和计算图
- 深度学习入门笔记(四):向量化
- 深度学习入门笔记(五):神经网络的编程基础
- 深度学习入门笔记(六):浅层神经网络
- 深度学习入门笔记(七):深层神经网络
- 深度学习入门笔记(八):深层网络的原理
- 深度学习入门笔记(九):深度学习数据处理
- 深度学习入门笔记(十):正则化
- 深度学习入门笔记(十一):权重初始化
- 深度学习入门笔记(十二):深度学习数据读取
- 深度学习入门笔记(十三):批归一化(Batch Normalization)
- 深度学习入门笔记(十四):Softmax
- 深度学习入门笔记(十五):深度学习框架(TensorFlow和Pytorch之争)
- 深度学习入门笔记(十六):计算机视觉之边缘检测
- 深度学习入门笔记(十七):深度学习的极限在哪?
- 深度学习入门笔记(十八):卷积神经网络(一)
- 深度学习入门笔记(十九):卷积神经网络(二)
- 深度学习入门笔记(二十):经典神经网络(LeNet-5、AlexNet和VGGNet)
参考文章
- 吴恩达——《神经网络和深度学习》视频课程
- 点赞 2
- 收藏
- 分享
- 文章举报
 我是管小亮
博客专家
发布了216 篇原创文章 · 获赞 4537 · 访问量 66万+
他的留言板
关注
我是管小亮
博客专家
发布了216 篇原创文章 · 获赞 4537 · 访问量 66万+
他的留言板
关注

- UFLDL深度学习笔记 (二)SoftMax 回归(矩阵化推导)
- 深度学习笔记三:Softmax Regression
- 深度学习与计算机视觉[CS231N] 学习笔记(3.2):Softmax Classifier(Loss Function)
- 深度学习 Deep Learning UFLDL 最新Tutorial 学习笔记 5:Softmax Regression
- 深度学习 Deep Learning UFLDL 最新Tutorial 学习笔记 5:Softmax Regression
- ufldl学习笔记和编程作业:Softmax Regression(softmax回报)
- java 从零开始,学习笔记之基础入门<内部类>(十四)
- Caffe深度学习入门——配置caffe-SSD详细步骤以及填坑笔记
- 深度增强学习入门笔记(一)
- 深度学习入门笔记(十六):计算机视觉之边缘检测
- 学习笔记TF024:TensorFlow实现Softmax Regression(回归)识别手写数字
- CS231n 学习笔记(2)——神经网络 part2 :Softmax classifier
- UFLDL学习笔记3——Softmax Regression
- 深度学习入门笔记(十五):深度学习框架(TensorFlow和Pytorch之争)
- 深度学习入门笔记--图像线性分类
- 深度学习入门课程学习笔记05 最优化
- [机器学习入门] 李弘毅机器学习笔记-7 (Brief Introduction of Deep Learning;深度学习简介)
- [深度学习论文笔记][Image Classification] Maxout Networks
- UnityShader入门精要学习笔记(二十一):深度和法线纹理
- 深度增强学习入门笔记(二)