深度学习入门笔记(十九):卷积神经网络(二)
欢迎关注WX公众号:【程序员管小亮】
专栏——深度学习入门笔记
声明
1)该文章整理自网上的大牛和机器学习专家无私奉献的资料,具体引用的资料请看参考文献。
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
3)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
4)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
文章目录
深度学习入门笔记(十九):卷积神经网络(二)
1、一个极其简单的卷积网络示例
在 深度学习入门笔记(十八):卷积神经网络(一) 中我们已经讲过了,怎样为卷积网络构建一个卷积层,那么现在来一起搭建一个简单的卷积网络。
假设有一张图片(图片分类或图片识别)定义为 xxx,然后现在辨别图片中有没有猫(用0或1表示),显然这是一个分类问题,针对它来一起构建一个卷积神经网络。假设用的是一张比较小的图片(39×39×3),这样设定可以使其中一些数字效果更好。所以 nH[0]=nW[0]=39n_{H}^{[0]} = n_{W}^{[0]} = 39nH[0]=nW[0]=39,即高度和宽度都等于39,nc[0]=3n_{c}^{[0]} =3nc[0]=3,即0层的通道数为3。
现在在网络的第一层使用一个3×3的过滤器来提取特征,那么 f[1]=3f^{[1]} = 3f[1]=3,而 s[1]=1s^{[1]} = 1s[1]=1,p[1]=0p^{[1]} =0p[1]=0,所以高度和宽度使用 valid 卷积。如果有10个过滤器,那么神经网络下一层的激活值为37×37×10,其中 nH[1]=nW[1]=37n_{H}^{[1]} = n_{W}^{[1]} = 37nH[1]=nW[1]=37,nc[1]=10n_{c}^{[1]} = 10nc[1]=10,nc[1]n_{c}^{[1]}nc[1]等于第一层中过滤器的个数,之所以是10是因为用了10个过滤器,又因为 vaild 卷积,所以公式 n+2p−fs+1\frac{n + 2p - f}{s} + 1sn+2p−f+1 的计算结果是37,即 39+0−31+1=37\frac{39 + 0 - 3}{1} + 1 = 37139+0−3+1=37,这(37×37×10)是第一层激活值的维度。
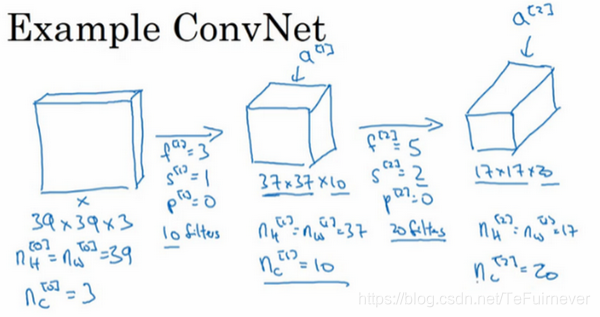
假设还有另外一个卷积层,这次采用的过滤器是5×5的,那么在标记法中,神经网络下一层的 f=5f=5f=5,即 f[2]=5f^{\left\lbrack 2 \right\rbrack} = 5f[2]=5 步幅为2,即 s[2]=2s^{\left\lbrack 2 \right\rbrack} = 2s[2]=2,而 padding 为0,即 p[2]=0p^{\left\lbrack 2 \right\rbrack} = 0p[2]=0,且有20个过滤器。所以其输出结果17×17×20,即 37+0−52+1=17\frac{37 + 0 - 5}{2} + 1 = 17237+0−5+1=17,因此 nH[2]=nW[2]=17n_{H}^{\left\lbrack 2 \right\rbrack} = n_{W}^{\left\lbrack 2 \right\rbrack} = 17nH[2]=nW[2]=17,nc[2]=20n_{c}^{\left\lbrack 2 \right\rbrack} = 20nc[2]=20。
是不是很惊讶,因为这次的大小从37×37减小到17×17,减小了一半还多,因为步幅是2,维度缩小得很快,而过滤器是20个,所以通道数也是20,17×17×20即激活值 a[2]a^{\left\lbrack 2 \right\rbrack}a[2] 的维度。

你以为这就完事了?当然不可能!!!不过这是最后一个卷积层了,假设过滤器还是5×5,步幅为2,即 f[2]=5f^{\left\lbrack 2 \right\rbrack} = 5f[2]=5,s[3]=2s^{\left\lbrack 3 \right\rbrack} = 2s[3]=2,计算过程略了,相信你一定会了,不会的话,去看前面的例子!假设使用了40个过滤器,padding 为0,所以最后结果为7×7×40。
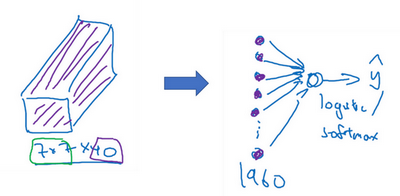
到此,这张39×39×3的输入图像就处理完毕了,并且为图片提取了7×7×40个特征,计算出来就是1960个特征。现在需要对该卷积进行处理,可以将其平滑或展开成1960个单元,是不是想起了什么,没错就是 深度学习入门笔记(二):神经网络基础、深度学习入门笔记(十四):Softmax!!!即 logistic 回归单元或是 softmax 回归单元,至于如何选取完全取决于我们是想识图片上有没有猫,还是想识别 KKK 种不同对象中的一种,不过无论是哪一种,有一定需要明确的是,最后这一步是处理所有数字(1960个数字),并把它们展开成一个很长的向量。
这就是卷积神经网络的一个典型范例,其实在设计卷积神经网络时,确定这些超参数比较费工夫:即决定滤器的大小、步幅、padding 以及使用多少个过滤器。随着神经网络计算深度不断加深,通常开始时的图像也要更大一些,初始值为39×39,高度和宽度会在一段时间内保持一致,然后随着网络深度的加深而逐渐减小,从39到37,再到17,最后到7,而通道数量在逐渐增加,从3到10,再到20,最后到40。这是卷积神经网络中的一种趋势,但是这些参数应该如何设置才会让输出结果更好?
之前写过一个调参经验,有兴趣的童鞋可以看一看,深度学习100问之提高深度学习模型训练效果(调参经验),后面有机会的话会再说一说。
到这里,卷积层就基本说完了,一个典型的卷积神经网络CNN(大话卷积神经网络CNN(干货满满))通常有三种层类型:
- 一个是卷积层,常常用 Conv 来标注,即上面讲的;
- 一个是池化层,常常用 POOL 来标注;
- 最后一个是全连接层,常常用 FC 来标注。
虽然仅用卷积层也有可能构建出很好的神经网络,但大部分神经网络架构师依然会添加池化层和全连接层,不过幸运的是,池化层和全连接层比卷积层更容易设计。
2、池化层
池化层是干什么的呢?
显然你很好奇,卷积网络经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。

先举一个池化层的例子,假如输入是一个4×4矩阵,用到的池化类型是最大池化(max pooling),执行最大池化的树池其实也是一个2×2矩阵只需要拆分成不同的区域即可,这里用四个颜色来表示,即紫色、蓝色、绿色、红色。
现在最大池化要做什么事呢,就是输出每个颜色区域中的最大元素值。
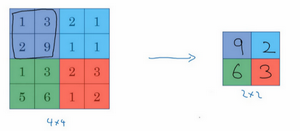
这很容易,左上区域的最大值是9,右上区域的最大元素值是2,左下区域的最大值是6,右下区域的最大值是3,看起来像是应用了一个规模为2的过滤器,步幅是2,这些就是最大池化的超参数。
卷积的方式是对最大池化功能的最直观理解了,把4×4输入看作是某些特征的集合,也就是神经网络中某一层的非激活值集合,数字大意味着可能探测到了某些特定的特征,可能是一个垂直边缘,一只眼睛,或是大家害怕遇到的 CAP 特征。最大化操作的功能就是在任何一个象限内提取到某个最大化的输出特征,你肯定在想为啥得是最大池化,别的不行吗,必须承认,人们使用最大池化的主要原因是此方法在很多实验中效果都很好。。。尽管刚刚描述的直观理解经常被引用,但是还是要尽量理解最大池化效率很高的真正原因。
其中一个有意思的原因就是,最大池化虽然有一组超参数,但并没有参数需要学习(前面提到了),所以在实际学习过程中,梯度下降没有什么可学的,速度自然就快,所以在这里你应该很容易能联想到,卷积也可以实现池化,不过区别是卷积是带有参数的,而池化不是。
池化只是求值计算,不存在梯度下降;卷积是矩阵运算,存在梯度下降。
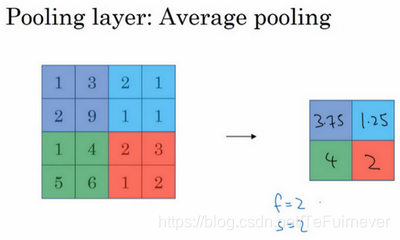
另外还有一种类型的池化,平均池化,因为它不太常用,所以这里就简单地介绍一下,顾名思义,平均池化求得不是每个过滤器的最大值,而是平均值。
下面例子中,紫色区域的平均值是3.75,后面依次是1.25、4和2,所以这个平均池化的超级参数 f=2f=2f=2,s=2s=2s=2,当然也可以选择其它超级参数,不过公认如此。
小结:
目前来说,最大池化在很多方面比平均池化更常用,但也有例外,就是深度很深的神经网络。。。一会看个例子。
池化的超级参数包括过滤器大小 fff 和步幅 sss,常用的参数值为 f=2f=2f=2,s=2s=2s=2,应用频率非常高,其效果相当于高度和宽度缩减一半,至于其它超级参数就要看用的是最大池化还是平均池化了。
输入通道与输出通道个数相同,因为对每个通道都做了池化,不过需要注意的一点是,池化过程中没有需要学习的参数,因此执行反向传播时,反向传播没有参数适用于池化,速度较快。
3、卷积神经网络
到目前为止(深度学习入门笔记),构建全卷积神经网络的构造模块,都已经掌握得差不多了,下面来看个网络。
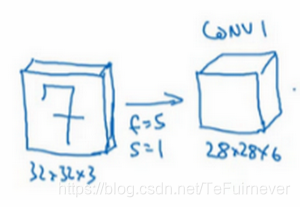
假设有一张大小为32×32×3的输入图片,这是一张 RGB 模式的图片,所以是3通道,现在想做的是手写体数字识别,因为图片中含有某个数字,比如7,你想识别它是从0-9这10个数字中的哪一个,那么如何构建一个神经网络来实现这个功能?
有灵气的小伙伴应该猜到了,其实这就是一个手写数字识别。
我用的这个网络模型和经典网络 LeNet-5 非常相似,LeNet-5 是多年前(史前时代)由 Yann LeCun 大佬创建的,这里使用的模型并不是 LeNet-5,但是许多参数选择都与 LeNet-5 相似,以后会将 LeNet-5的。
输入是32×32×3的矩阵,假设第一层使用过滤器大小为5×5,步幅是1,padding 是0,过滤器个数为6,那么输出是多少?(别说你不会,不会的去面壁吧)
输出为28×28×6,将这层标记为 CONV1,对该层增加了偏差,应用了非线性函数,可能是 ReLU 非线性函数(效果较佳),最后输出 CONV1 的结果。
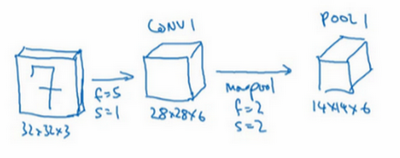
然后构建一个池化层(最大池化),参数 f=2f=2f=2,s=2s=2s=2,步幅为2,表示层的高度和宽度会减少一半,因此28×28变成了14×14,通道数量保持不变,所以最终输出为14×14×6,将该输出标记为 POOL1。
要学会给自己的网络层起名字,不然有你的好果子吃。
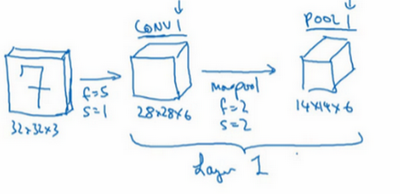
人们发现在卷积神经网络文献中,卷积有两种分类,这与所谓层的划分存在一致性:
- 一类卷积是一个卷积层和一个池化层一起作为一层,即神经网络的 Layer1。
- 另一类卷积是把卷积层作为一层,而池化层单独作为一层。
这有什么关系呢?
这与人们在计算神经网络有多少层有关,不过通常只统计具有权重和参数的层,因为池化层没有权重和参数,只有一些超参数,所以很多时候不把它作为一个层数,即把 CONV1 和 POOL1 共同作为一个卷积,并标记为 Layer1。
下面再为它构建一个卷积层,过滤器大小为5×5,步幅为1,不过这次用16个过滤器,最后输出一个10×10×16的矩阵,标记为 CONV2。
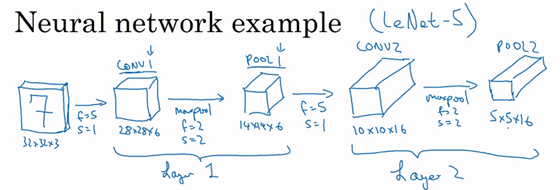
然后继续执行做最大池化计算,参数 f=2f=2f=2,s=2s=2s=2,你现在应该能猜到结果了才对么?
参数 f=2f=2f=2,s=2s=2s=2,高度和宽度减半,通道数和之前一样,结果为5×5×16,标记为 POOL2,这就是 Layer2(一个权重集和一个卷积层)。
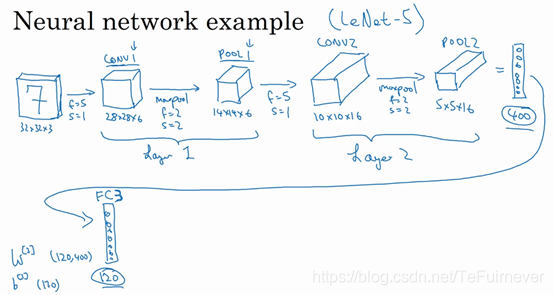
然后做一个平整,5×5×16矩阵包含400个元素,POOL2 的输出结果被平整化为一个大小为400的一维向量,可以想象这是一个神经元集合,然后利用这400个单元去构建下一层网络,假设下一层含有120个单元,这就是我们的第一个全连接层,标记为 FC3,为什么叫全连接层,是因为这400个单元与120个单元紧密相连,每一项都连接在一起,它的权重矩阵为 W[3]W^{\left\lbrack 3 \right\rbrack}W[3],维度为120×400,这就是所谓的全连接。
然后对这个120个单元再添加一个全连接层,这层更小,假设它含有84个单元,标记为 FC4。
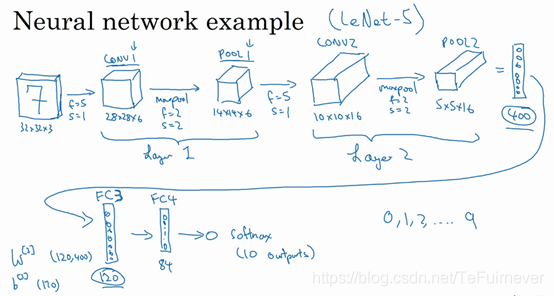
最后,用这84个单元填充一个 softmax 单元,你应该记得的,如果网络的目的是想识别手写0-9这10个数字,这个 softmax 就会有10个输出,分别对应识别为十个数字的概率。
这个例子中的卷积神经网络很典型,但是我们的版本和原始版本还是有些区别,不要着急,这个会在后面提到!
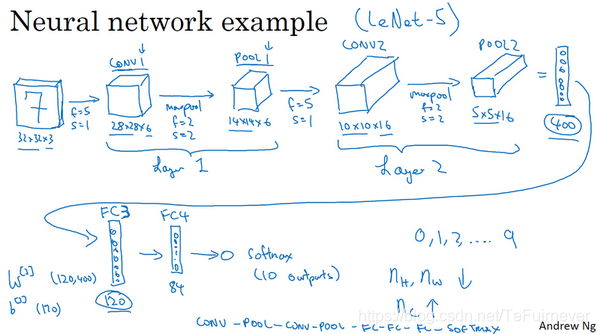
接下来我们讲讲神经网络的激活值形状,激活值大小和参数数量。
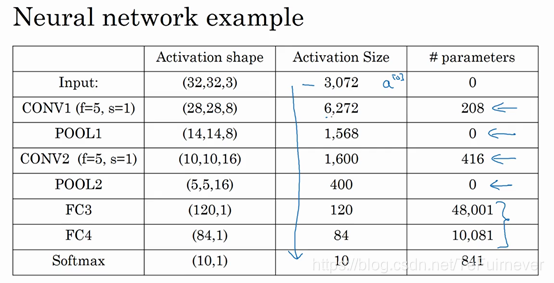
输入为32×32×3,这些数做乘法,结果为3072,所以激活值 a[0]a^{[0]}a[0] 有3072维,激活值矩阵为32×32×3,输入层没有参数。计算其他层的时候,试着自己计算出激活值,这些都是网络中不同层的激活值形状和激活值大小。
以第一个卷积层为例,参数大小计算如下:
5×5×8+5×5×1=2085×5×8+5×5×1 = 2085×5×8+5×5×1=208
其中5是滤波器大小,8是滤波器通道数,1是偏差。
有几点要注意,
- 第一,池化层和最大池化层没有参数;
- 第二,卷积层的参数相对较少。
- 第三,许多参数都存在于神经网络的全连接层。
通过观察可发现,随着神经网络的加深,激活值尺寸会逐渐变小,但是如果激活值尺寸下降太快,也会影响神经网络性能,所以需要逐渐减小,在示例中,激活值尺寸在第一层为6000,然后减少到1600,慢慢减少到84,最后输出 softmax 结果。
那么如何把这些基本模块(卷积层、池化层、全连接层)整合起来,构建高效的神经网络?目前阶段很多说法是经验主义,这一点确实不可否认,因为整合这些基本模块确实需要深入的理解,比如根据我的经验,找到整合基本构造模块最好方法就是大量阅读别人的案例,但是模型是否真的不可解释,当然不是,欢迎关注后续。
4、为什么使用卷积?
最后,我们来分析一下卷积在神经网络中如此受用的原因,和只用全连接层相比,卷积层的两个主要优势在于参数共享和稀疏连接,举例说明一下。

假设有一张32×32×3维度的图片,用了6个大小为5×5的过滤器去卷积,输出维度为28×28×6,32×32×3=3072,28×28×6=4704。即我们构建的神经网络,其中一层含有3072个单元,而它的下一层含有4074个单元,两层中的每个神经元彼此相连,然后计算权重矩阵,那么就是4074×3072≈1400万,哇!

所以要训练的参数很多很多,虽然以现在的技术计算也不是不可以,但是用1400多万个参数来训练网络,肯定是不可行的,
- 一方面是因为这张32×32×3的图片非常小,如果这是一张1000×1000的图片,权重矩阵会变得非常大;
- 另一方面是网络深度较大,如果这是一个100层的深度神经网络,最终需要学习的参数会变得非常大。
而现在每个过滤器都是5×5,一个过滤器有25个参数,再加上偏差参数,那么每个过滤器就有26个参数,一共有6个过滤器,所以参数共计156个,参数数量还是很少。
为什么?
两个原因:
- 一是参数共享。观察发现,特征检测,如垂直边缘检测,如果适用于图片的某个区域,那么它也可能适用于图片的其他区域。也就是说,每个特征检测器以及输出都可以在输入图片的不同区域中使用同样的参数,以便提取垂直边缘或其它特征(不仅适用于边缘特征这样的低阶特征,同样适用于高阶特征),例如提取脸上的眼睛,猫或者其他特征对象都是比较相似的。
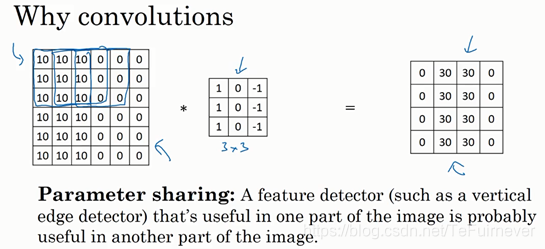
- 二是使用 稀疏连接,简单解释下,这个0是通过3×3的卷积计算得到的,它只依赖于这个3×3的输入的单元格,右边这个输出单元(元素0)仅与36个输入特征中9个相连接,而且其它像素值都不会对输出产生任影响,这就是稀疏连接的概念。
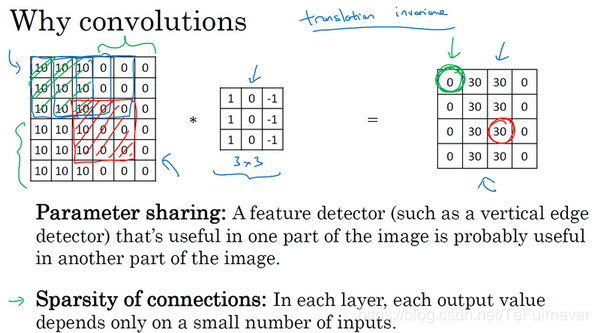
再举一个例子,这个输出(右边矩阵中红色标记的元素30)仅仅依赖于这9个特征(左边矩阵红色方框标记的区域),看上去只有这9个输入特征与输出相连接,其它像素对输出没有任何影响。
神经网络可以通过这两种机制(参数共享、稀疏连接)减少参数,以便用更小的训练集来训练它,从而有效地预防过度拟合(深度学习入门笔记(十):正则化)。
你们可能也听过,卷积神经网络善于捕捉平移不变,通过观察可以发现,向右移动两个像素,图片中的猫依然清晰可见,因为神经网络的卷积结构使得即使移动几个像素,这张图片依然具有非常相似的特征,应该属于同样的输出标记!!!实际上,我们用同一个过滤器生成各层中,图片的所有像素值,希望网络通过自动学习变得更加健壮,以便更好地取得所期望的平移不变属性,这就是卷积或卷积网络在计算机视觉任务中表现良好的原因。
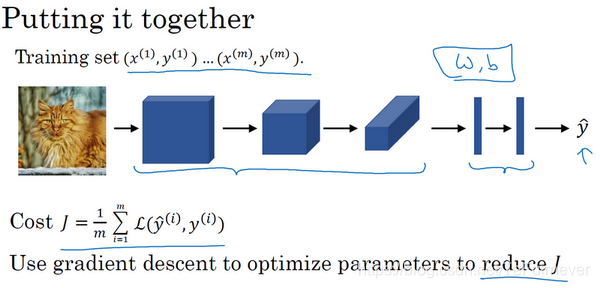
最后,整合起来这些层,看看如何训练这些网络。
比如要构建一个猫咪检测器,那么有一个标记训练集,xxx 表示一张图片,y^\hat{y}y^ 是二进制标记或某个重要标记,选定了一个卷积神经网络,输入图片,增加卷积层和池化层,然后添加全连接层,最后输出一个 softmax,即 y^\hat{y}y^。卷积层和全连接层有不同的参数 www 和偏差 bbb,定义代价函数并随机初始化其参数 www 和 bbb,代价函数 JJJ 等于神经网络对整个训练集的预测的损失总和再除以 mmm(即 Cost J=1m∑i=1mL(y^(i),y(i))\text{Cost}\ J = \frac{1}{m}\sum_{i = 1}^{m}{L(\hat{y}^{(i)},y^{(i)})}Cost J=m1∑i=1mL(y^(i),y(i))),然后使用梯度下降法,或其它算法,例如 Momentum 梯度下降法,含 RMSProp 或其它因子的梯度下降来优化神经网络中所有参数,以减少代价函数 JJJ 的值,通过上述操作,就可以构建一个高效的猫咪检测器或其它检测器。
到这里就把上面提到了基本全部讲完了,欢迎在推荐阅读中寻找相应的部分查看。
推荐阅读
- 深度学习入门笔记(一):深度学习引言
- 深度学习入门笔记(二):神经网络基础
- 深度学习入门笔记(三):求导和计算图
- 深度学习入门笔记(四):向量化
- 深度学习入门笔记(五):神经网络的编程基础
- 深度学习入门笔记(六):浅层神经网络
- 深度学习入门笔记(七):深层神经网络
- 深度学习入门笔记(八):深层网络的原理
- 深度学习入门笔记(九):深度学习数据处理
- 深度学习入门笔记(十):正则化
- 深度学习入门笔记(十一):权重初始化
- 深度学习入门笔记(十二):深度学习数据读取
- 深度学习入门笔记(十三):批归一化(Batch Normalization)
- 深度学习入门笔记(十四):Softmax
- 深度学习入门笔记(十五):深度学习框架(TensorFlow和Pytorch之争)
- 深度学习入门笔记(十六):计算机视觉之边缘检测
- 深度学习入门笔记(十七):深度学习的极限在哪?
- 深度学习入门笔记(十八):卷积神经网络(一)
- 深度学习入门笔记(十九):卷积神经网络(二)
- 深度学习入门笔记(二十):经典神经网络(LeNet-5、AlexNet和VGGNet)
参考文章
- 吴恩达——《神经网络和深度学习》视频课程
- 点赞 2
- 收藏
- 分享
- 文章举报
 我是管小亮
博客专家
发布了216 篇原创文章 · 获赞 4537 · 访问量 66万+
他的留言板
关注
我是管小亮
博客专家
发布了216 篇原创文章 · 获赞 4537 · 访问量 66万+
他的留言板
关注

- TensorFlow 深度学习笔记 卷积神经网络
- 零基础入门深度学习(4) - 卷积神经网络---https://www.zybuluo.com/hanbingtao/note/485480
- 深度学习笔记1(卷积神经网络)
- (转载有修改)Deep Learning(深度学习)学习笔记整理系列----深度学习入门科普
- 吴恩达深度学习笔记四:卷积神经网络 基础和目标检测部分
- 卷积神经网络(CNN)学习笔记1:基础入门
- 零基础入门深度学习(4) - 卷积神经网络
- Tensorflow深度学习笔记(九)--卷积神经网络(CNN)
- 深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-01-CNN基础知识点
- 卷积神经网络(CNN)学习笔记1:基础入门
- 深度学习入门笔记:Fast Image Search with Deep Convolutional Neural Networks and Efficient Hashing Codes
- 深度学习入门--最优化笔记
- 深度学习入门课程笔记 神经网络
- [机器学习入门] 李宏毅机器学习笔记-37 (Deep Reinforcement Learning;深度增强学习入门)
- 深度学习(十九)基于空间金字塔池化的卷积神经网络物体检测-ECCV 2014
- 深度学习入门---Keras报错集合笔记
- 深度学习Caffe实战笔记(7)Caffe平台下,如何调整卷积神经网络结构
- Caffe深度学习入门——配置caffe-SSD详细步骤以及填坑笔记
- 卷积神经网络(CNN)学习笔记1:基础入门
- 吴恩达深度学习入门学习笔记之神经网络和深度学习(第一周)