通过源码理解HashMap的并发问题
最近在学习有关于Java的基础知识,在学习到HashMap的相关知识的时候,了解了HashMap的并发中会出现的问题,在此记录,加深理解(这篇文章是基于Java1.7的,主要是为了更加直观,更新版本的代码更加复杂,等理解后会继续总结).
HashMap的内部存在一个数组,每个位置存放一个自定义的Node对象,Node对象中存在下一个对象的引用,类似如下结构
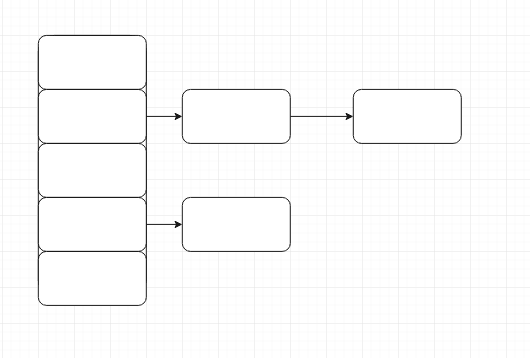
每次添加后size属性都会增加,当size属性超过了阈值(表现为大于threshold属性的值)时,会触发resize(itn size)方法,进行扩容,扩容的方式是创建一个2倍大的新的数组,对老transfer()函数,对数组进行遍历重算新hash,并赋值到新数组中,如果程序是并发执行,就容易出现问题.
核心代码如下:
1 /**
2 * Transfers all entries from current table to newTable.
3 */
4 void transfer(Entry[] newTable) {
5 Entry[] src = table;
6 int newCapacity = newTable.length;
7 for (int j = 0; j < src.length; j++) {
8 Entry<K,V> e = src[j];
9 if (e != null) {
10 src[j] = null;
11 do {
12 Entry<K,V> next = e.next;
13 int i = indexFor(e.hash, newCapacity);
14 e.next = newTable[i];
15 newTable[i] = e;
16 e = next;
17 } while (e != null);
18 }
19 }
20 }
简单来说就是取一个节点,循环找下一个,赋到新的数组中,如果多线程就会出现问题
如果线程a准备扩容,发生线程切换时正好处于这个状态(只是示意图,大小等并不符合真实情况)
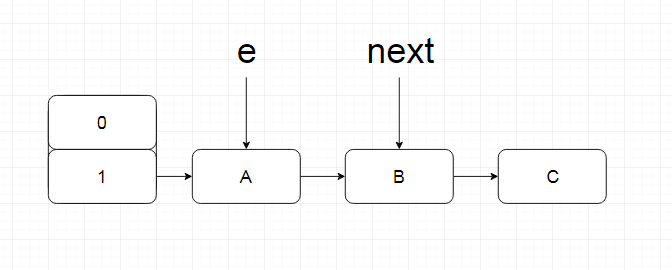
此时线程切换,线程b完成了扩容的过程,再切回线程a,此时扩容完成,但是线程a依旧执行,变量仍然指向那些节点,此时如果出现以下情况
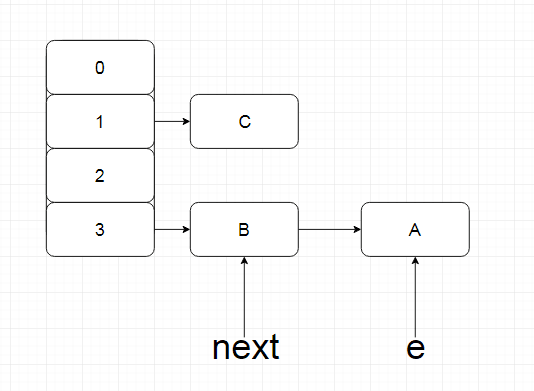
此时继续执行,执行了e.next = newTable[i]; newTable[i] = e; e = next;此时就会出现循环列表
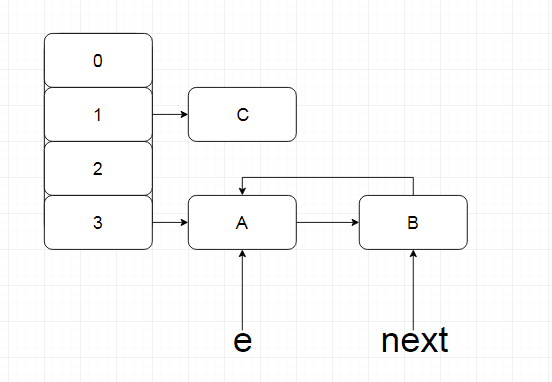
此时循环链表出现,当我们调用get()方法,hash在位置,且寻找元素不存在的时候,就会进入死循环无法跳出.
原理的简单描述就是这样,如果需要在并发条件下使用,可以使用Java并发包中的ConcurrentHashMap.
转载于:https://www.cnblogs.com/meiwangqing/p/9067869.html
- 点赞
- 收藏
- 分享
- 文章举报
 baijiacha3793
发布了0 篇原创文章 · 获赞 0 · 访问量 6
私信
关注
baijiacha3793
发布了0 篇原创文章 · 获赞 0 · 访问量 6
私信
关注

- HashMap源码及多线程并发问题深度分析
- 理解B/S结构中服务端同步与异步机制的区别,通过使用ASP.Net异步处理节约队列时间成本,解决大并发量问题
- Java中的HashMap源码记录以及并发环境的几个问题
- Java 容器源码分析之HashMap多线程并发问题分析
- HashMap实现原理分析--通过面试题深入理解
- HashMap源码理解
- Android源码解析四大组件系列(八)---广播几个问题的深入理解
- [MySQL]对于事务并发处理带来的问题,脏读、不可重复读、幻读的理解
- java.util.concurrent.ConcurrentHashMap并发哈希表源码解析
- HashMap进行put操作时遇到的并发问题
- hashMap 源码解读理解实现原理和hash冲突
- 通过源码深入理解 Spring 事务的实现原理
- HashMap进行put操作时遇到的并发问题
- 6.1 (番外)深入源码理解HashMap、LinkedHashMap,DiskLruCache
- Debian 10 Buster/ 树莓派 通过源码安装ROS出现的问题
- 从源码理解HashMap
- shiro 再次通过源码谈谈登录的流程,之前理解的不是很清楚!
- 【Normalize.css】源码注释翻译&浏览器css兼容问题的理解
- 多服务分布式并发问题的理解
- 通过源码理解UST(用户栈回溯)