python的requests.get()方法获取百度搜索结果页面失败的问题
2020-02-01 16:17
681 查看
昨天学到python的requests模块,准备获取一下百度搜索的结果,然后把相关链接打开,在get()结果页的时候一直取不到,
keyword=input(‘输入要搜索的关键字:’)
res=requests.get('https://www.baidu.com/s?wd=’+keyword)
取出来的html文件是这样的
<html>
<head>
<script>
location.replace(location.href.replace("https://","http://"));
</script>
</head>
<body>
<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>
</body>
</html>
查了一下别人的解决方法,都没大看懂,最后问了朋友才解决
原因是一开始请求消息里没带浏览器信息,百度不识别,所以不响应。
加一个headers,把浏览器信息写进去:
headers={‘User-Agent’:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36’}
res = requests.get('https://www.baidu.com/s?wd=’+keyword,headers=headers)
获取headers的方法:
打开浏览器(我用的谷歌,别的应该也差不多),F12,随便发个请求,然后如下图获取User-Agent
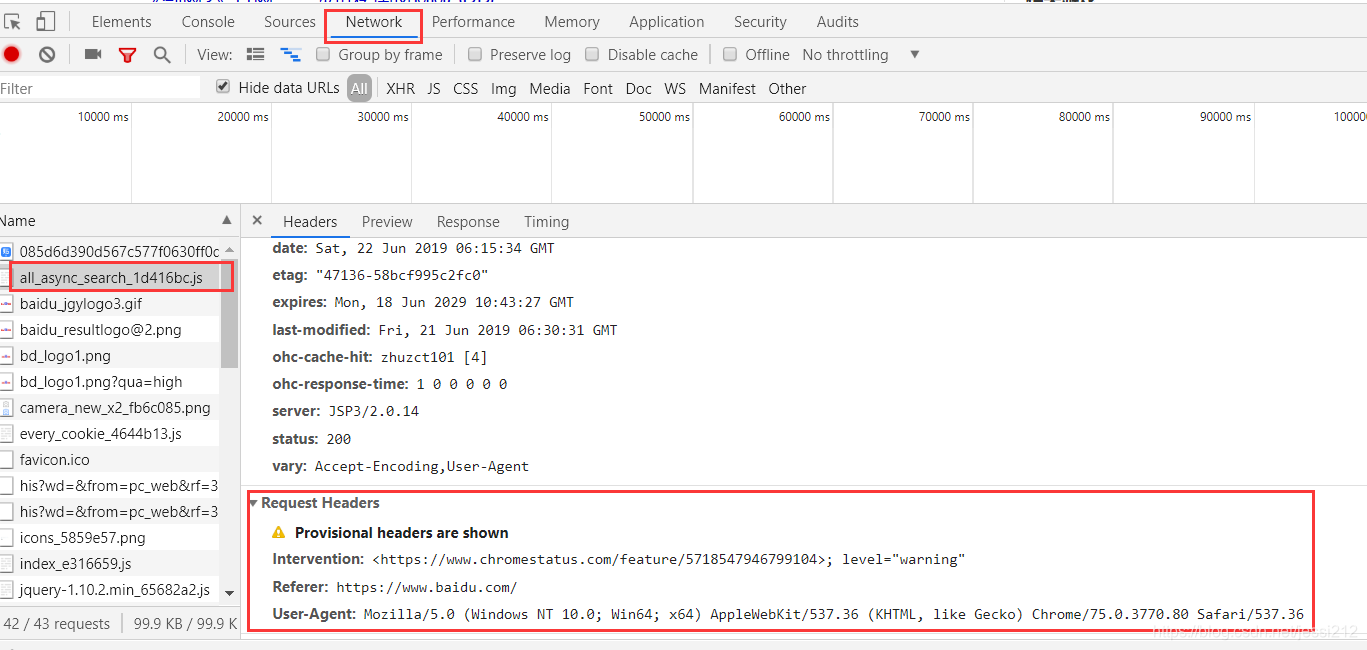
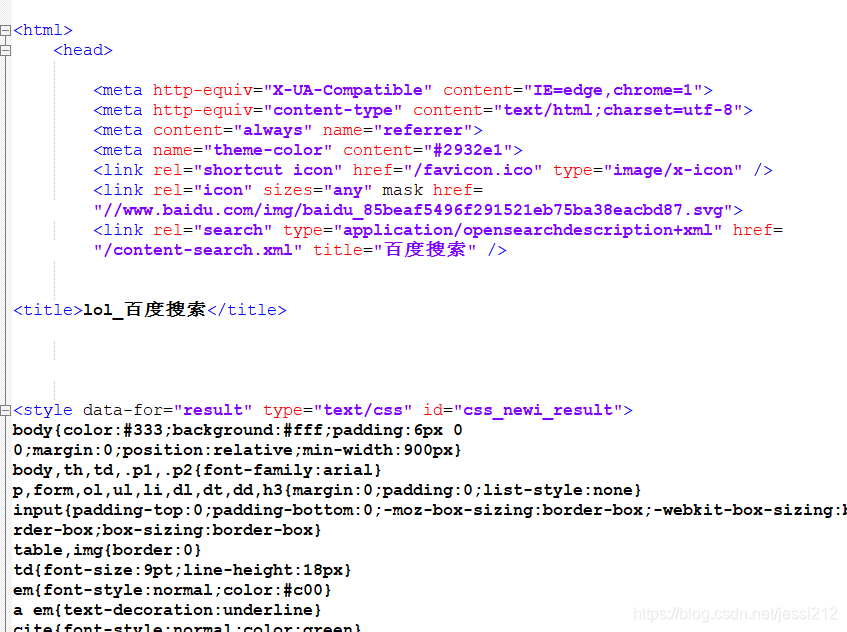
把headers加到参数里去就可以了,再发请求可以成功获取百度搜索结果页的html,截了一部分
如果有不对的地方欢迎大佬指正
- 点赞 1
- 收藏
- 分享
- 文章举报
 拉链小子
发布了1 篇原创文章 · 获赞 1 · 访问量 932
私信
关注
拉链小子
发布了1 篇原创文章 · 获赞 1 · 访问量 932
私信
关注

相关文章推荐
- C++和python如何获取百度搜索结果页面下信息对应的真实链接(百度搜索爬虫,可指定页数)
- cefSharp获取百度搜索结果页面的源码
- selenium-webdriver循环点击百度搜索结果以及获取新页面的handler
- python实现提取百度搜索结果的方法
- 遇到问题---java获取网络文件大小失败getContentLength()为-1 完整解决方法
- python使用get在百度搜索并保存第一页搜索结果
- python使用get在百度搜索并保存第一页搜索结果
- 解析百度搜索结果页面的python脚本(Linux/Win都可以运行)
- python如何获取百度搜索结果的真实URL
- python爬虫(11)身边的搜索专家——获取百度搜索结果
- 浏览器点击百度搜索结果之后,原搜索页面出现重定向乱码不断刷新问题的分析和解决
- 用requests的get方法获取百度一下的请求
- python使用get在百度搜索并保存第一页搜索结果
- 用python和BeautifulSoup抓取百度搜索结果10-20页面中的网站链接
- 百度“搜索设置”之关于在页面定位某元素,而其中又参杂动态页面存在的问题解决方法
- 遇到问题---java获取网络文件大小失败getContentLength()为-1 完整解决方法
- json传递中文乱码解决方法以及解决request.getParameter()获取参数为乱码的问题
- 用python通过apache log 获取百度搜索来源关键词
- 百度搜索结果页面的参数 上次搜索词(bs)
- ThinkPHP采用GET方式获取中文参数查询无结果的解决方法