ElasticSearch相关性打分机制学习
ElasticSearch 2.3版本全文搜索默认采用的是相关性打分TFIDF,在实际的运用中,我们采用Multi-Match给各个字段设置权重、使用should给特定文档权重或使用更高级的Function_Score来自定义打分,借助于Elasticsearch的explain功能,我们可以深入地学习一下其中的机制。
创建一个索引
PUT /gino_test
{
"mappings": {
"tweet": {
"properties": {
"text": {
"type": "string",
"term_vector": "with_positions_offsets_payloads",
"store" : true,
"analyzer" : "fulltext_analyzer"
},
"fullname": {
"type": "string",
"term_vector": "with_positions_offsets_payloads",
"analyzer" : "fulltext_analyzer"
}
}
}
},
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0
},
"analysis": {
"analyzer": {
"fulltext_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"type_as_payload"
]
}
}
}
}
}
插入测试数据:
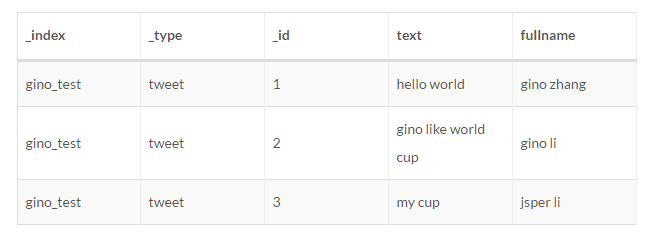
简单情况:单字段匹配打分
POST gino_test/_search
{
"explain": true,
"query": {
"match": {
"text": "my cup"
}
}
}
查询结果: score_simple.json
打分分析:
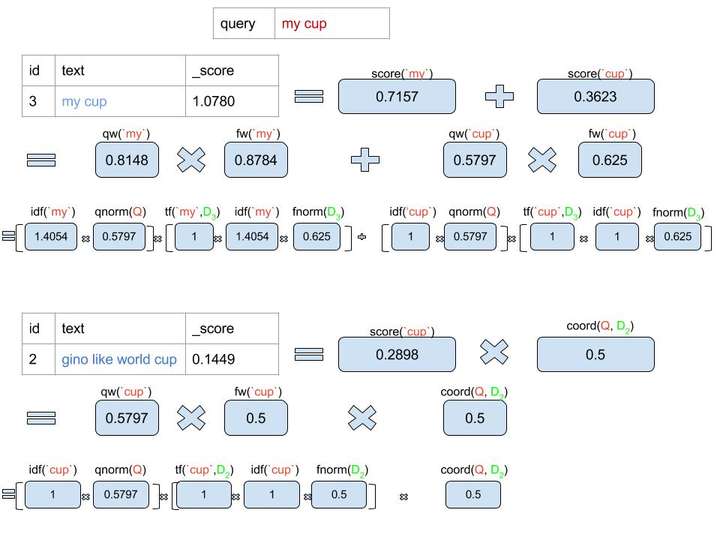
ElasticSearch目前采用的默认相关性打分采用的是Lucene的TF-IDF技术。

我们来深入地分析一下这个公式:
score(q,d) = queryNorm(q) · coord(q,d) · ∑ (tf(t,d) · idf(t)² · t.getBoost() · norm(t,d))
- score(q,d) 是指查询输入Q和当前文档D的相关性得分;
- queryNorm(q) 是查询输入归一化因子,其作用是使最终的得分不至于太大,从而具有一定的可比性;
- coord(q,d) 是协调因子,表示输入的Token被文档匹配到的比例;
- tf(t,d) 表示输入的一个Token在文档中出现的频率,频率越高,得分越高;
- idf(t) 表示输入的一个Token的频率级别,它具体的计算与当前文档无关,而是与索引中出现的频率相关,出现频率越低,说明这个词是个稀缺词,得分会越高;
- t.getBoost() 是查询时指定的权重.
- norm(t,d) 是指当前文档的Term数量的一个权重,它在索引阶段就已经计算好,由于存储的关系,它最终值是0.125的倍数。
注意:在计算过程中,涉及的变量应该考虑的是document所在的分片而不是整个index。
score(q,d) = _score(q,d.f) --------- ① = queryNorm(q) · coord(q,d) · ∑ (tf(t,d) · idf(t)² · t.getBoost() · norm(t,d)) = coord(q,d) · ∑ (tf(t,d) · idf(t)² · t.getBoost() · norm(t,d) · queryNorm(q)) = coord(q,d.f) · ∑ _score(q.ti, d.f) [ti in q] --------- ② = coord(q,d.f) · (_score(q.t1, d.f) + _score(q.t2, d.f))
- ① 相关性打分其实是查询与某个文档的某个字段之间的相关性打分,而不是与文档的相关性;
- ② 根据公式转换,就变成了查询的所有Term与文档中字段的相关性求和,如果某个Term不相关,则需要处理coord系数;
multi-match多字段匹配打分(best_fields模式)
POST /gino_test/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "gino cup",
"fields": [
"text^8",
"fullname^5"
]
}
}
}
打分分析:
score(q,d) = max(_score(q, d.fi)) = max(_score(q, d.f1), _score(q, d.f2)) = max(coord(q,d.f1) · (_score(q.t1, d.f1) + _score(q.t2, d.f1)), coord(q,d.f2) · (_score(q.t1, d.f2) + _score(q.t2, d.f2)))
- 对于multi-field的best_fields模式来说,相当于是对每个字段对查询分别进行打分,然后执行max运算获取打分最高的。
- 在计算query weight的过程需要乘上字段的权重,在计算fieldNorm的时候也需要乘上字段的权重。
- 默认operator为or,如果使用and,打分机制也是一样的,但是搜索结果会不一样。
multi-match多字段匹配打分(cross_fields模式)
POST /gino_test/_search
{
"explain": true,
"query": {
"multi_match": {
"query": "gino cup",
"type": "cross_fields",
"fields": [
"text^8",
"fullname^5"
]
}
}
}
打分分析:
score(q, d) = ∑ (_score(q.ti, d.f)) = ∑ (_score(q.t1, d.f), _score(q.t1, d.f)) = ∑ (max(coord(q.t1,d.f) · _score(q.t1, d.f1), coord(q.t1,d.f) · _score(q.t1, d.f2)), max(coord(q.t2,d.f) · _score(q.t2, d.f1), coord(q.t2,d.f) · _score(q.t2, d.f2)))
- coord(q.t1,d.f)函数表示搜索的Term(如gino)在multi-field中有多少比率的字段匹配到;best_fields模式中coord(q,d.f1)表示搜索的所以Term(如gino和cup)有多少比率存在与特定的field字段(如text字段)里;
- 对于multi-field的cross_fields模式来说,相当于是对每个查询的Term进行打分(每个Term执行best_fields打分,即看下哪个field匹配更高),然后执行sum运算。
- 默认operator为or,如果使用and,打分机制也是一样的,但是搜索结果会不一样。这是一个使用operator为or的报文:score_crossfields_or.json
should增加权重打分
为了增加filter的测试,给gino_test/tweet增加一个tags的字段。
PUT /gino_test/_mapping/tweet
{
"properties": {
"tags": {
"type": "string",
"analyzer": "fulltext_analyzer"
}
}
}
增加tags的标签
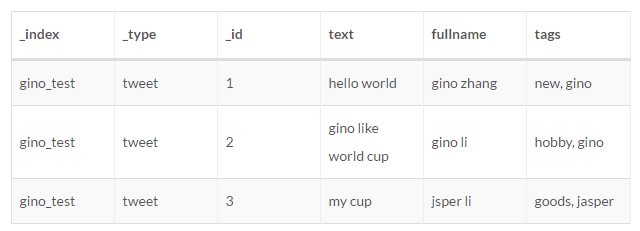
POST /gino_test/_search
{
"explain": true,
"query": {
"bool": {
"must": {
"bool": {
"must": {
"multi_match": {
"query": "gino cup",
"fields": [
"text^8",
"fullname^5"
],
"type": "best_fields",
"operator": "or"
}
},
"should": [
{
"term": {
"tags": {
"value": "goods",
"boost": 6
}
}
},
{
"term": {
"tags": {
"value": "hobby",
"boost": 3
}
}
}
]
}
}
}
}
}
查询结果:score_should.json
打分分析:
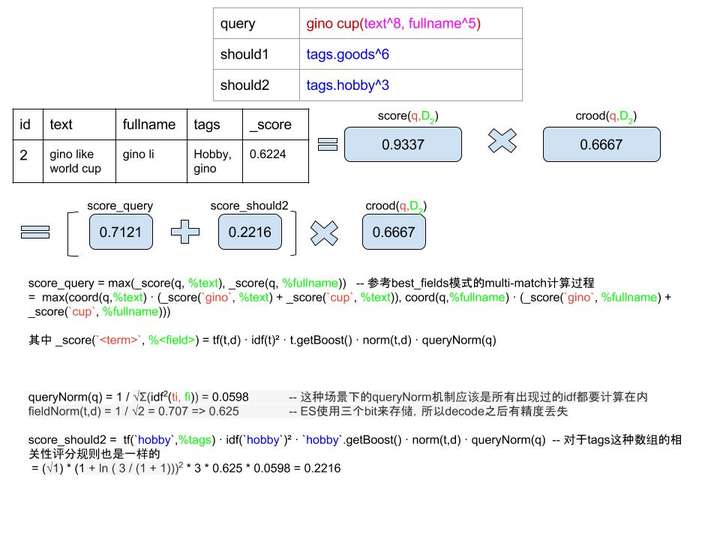
增加了should的权重之后,相当于多了一个打分参考项,打分的过程见上面的计算过程。
function_score高级打分机制
DSL格式:
{
"function_score": {
"query": {},
"boost": "boost for the whole query",
"functions": [
{
"filter": {},
"FUNCTION": {},
"weight": number
},
{
"FUNCTION": {}
},
{
"filter": {},
"weight": number
}
],
"max_boost": number,
"score_mode": "(multiply|max|...)",
"boost_mode": "(multiply|replace|...)",
"min_score" : number
}
}
支持四种类型发FUNCTION:
- script_score: 自定义的高级打分机制,涉及的字段只能是数值类型的
- weight: 权重打分,一般结合filter一起使用,表示满足某种条件加多少倍的分
- random_score: 生成一个随机分数,比如应该uid随机打乱排序
- field_value_factor: 根据index里的某个字段值影响打分,比如销量(涉及的字段只能是数值类型的)
- decay functions: 衰减函数打分,比如越靠近市中心的打分越高
来做一个实验。先给index增加一个查看数的字段:
PUT /gino_test/_mapping/tweet
{
"properties": {
"views": {
"type": "long",
"doc_values": true,
"fielddata": {
"format": "doc_values"
}
}
}
给三条数据分别加上查看数的值:
POST gino_test/tweet/1/_update
{
"doc" : {
"views" : 56
}
}
最终数据的样子:
执行一个查询:
{
"explain": true,
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "gino cup",
"type": "cross_fields",
"fields": [
"text^8",
"fullname^5"
]
}
},
"boost": 2,
"functions": [
{
"field_value_factor": {
"field": "views",
"factor": 1.2,
"modifier": "sqrt",
"missing": 1
}
},
{
"filter": {
"term": {
"tags": {
"value": "goods"
}
}
},
"weight": 4
}
],
"score_mode": "multiply",
"boost_mode": "multiply"
}
}
}
查询结果:score_function.json
打分分析:
score(q,d) = score_query(q,d) * (score_fvf(`view`) * score_filter(`tags:goods`))
- score_mode表示多个FUNCTION之间打分的运算法则,需要注意不同的FUNCTION的打分的结果级别可能相差很大;
- boost_mode表示function_score和query_score打分的运算法则,也需要注意打分结果的级别;
rescore重打分机制
ES官网介绍: Rescoring | Elasticsearch Reference [2.3] | Elastic
重打分机制并不会应用到所有的数据中。比如需要查询前10条数据,那么所有的分片先按默认规则查询出前10条数据,然后应用rescore规则进行重打分返回给master节点进行综合排序返回给用户。
rescore支持多个规则计算,以及与原先的默认打分进行运算(权重求和等)。
rescore因为计算的打分的document较少,性能应该会更好一点,但是这个涉及到全局排序,实际运用的场景要注意。
参考材料
转载于:https://my.oschina.net/airship/blog/3082928
- 点赞
- 收藏
- 分享
- 文章举报
 chijue3990
发布了0 篇原创文章 · 获赞 0 · 访问量 4449
私信
关注
chijue3990
发布了0 篇原创文章 · 获赞 0 · 访问量 4449
私信
关注

- 大数据学习[15]:elasticsearch之同义词
- .net Elasticsearch 学习入门笔记
- 20_ElasticSearch rescoring机制优化近似匹配搜索的性能
- 大数据学习[07]:elasticsearch5.6.1集群与问题
- spring data elasticsearch学习笔记_01业务实现+整合spring security
- ELK (ElasticSearch + Logstash + Kibaba + Marvel)系统的搭建学习与简单使用
- Elasticsearch Dynamic Mapping(动态映射机制)
- Elasticsearch.The.Definitive.Guide学习笔记 -- 3. Data in, Data in
- spring data elasticsearch学习笔记_03参数校验
- elasticsearch入门学习备忘
- 大数据学习[13]:elasticsearch之简单的python API
- 搜索学习--Elasticsearch全文搜索服务器的基本使用
- ElasticSearch入门学习
- ElasticStack学习(八):ElasticSearch索引模板与聚合分析初探
- ELK (ElasticSearch + Logstash + Kibaba + Marvel)系统的搭建学习与简单使用
- 开源分布式搜索平台ELK(Elasticsearch+Logstash+Kibana)入门学习资源索引
- 最近ELK(elasticsearch+logstash+kibana)学习小结
- 实习日记:ElasticSearch 学习小记
- ELK学习13_logstash启动报错[logstash.outputs.elasticsearch] Unknown setting 'host' for elasticsearch