人群计数-SaCNN论文翻译
论文翻译
摘要:
人群计数的任务是自动估计人群图像中的行人数目。为了应对人群图像中普遍存在的尺度和视角变化,最先进的方法是采用多列CNN架构来回归人群图像的密度图。对于不同尺度的行人(头),多列具有不同的接受域。相反,我们提出了一个具有固定小接受域的自适应尺度CNN (SaCNN)架构。我们从多层结构中提取特征映射,使其具有相同的输出尺寸;我们把它们结合起来,绘制出最终的密度图。人数是通过对密度图的积分来计算的。由于MCNN在人数较少的时候精确度不高,我们还引入了相关的计数损失和密度图损失来改善网络在行人较少的人群场景上的泛化能力。我们在上海科技、UCF CC 50、WorldExpo 10等数据集上进行了广泛的实验,并针对人群较少的场景收集了一个新的数据集SmartCity,也在上面做了大量的实验。结果表明,相对于最先进的技术,SaCNN有了显著的改进。
1.引言
计算机视觉中的人群计数任务是对图像或视频中的行人进行自动计数。在公共集会和体育等许多场合,为了帮助控制人群和公共安全,需要准确的人群计数。早期的方法是通过检测来估计行人数量,其中每一个行人都是由训练好的检测器检测出来的。如果行人被严重堵塞或密集分布,这将非常困难。目前的方法是对整个图像的行人数进行回归,取得了显著的改善。像HOG这样的手工功能很快就被现代深度方法所替代。
通过回归进行的人群计数在视角和尺度上都发生了巨大的变化,这在人群图像中是普遍存在的(见图1)。为了解决这一问题,最近采用了多列卷积神经网络(CNN),并显示了稳健的性能。不同的列对应不同的滤波器尺寸(小、中、大),最后结合以适应每个透视和尺度的大变化。它们回归得到人群密度图(图1),对密度图积分得到行人数。进一步引入了一个切换分类器,将图像中的人群补丁转发到最好的CNN列中。每个CNN专栏都有自己的样本进行训练。
我们注意到多个列之间的选择是不平衡的。在某些数据集中,使用一列可以保持多列模型70%以上的精度。在此基础上,本文提出了一种尺度自适应CNN架构(SaCNN,图2)用于人群计数。它提供了几个新的元素作为我们的贡献:(1)我们设计仅一列CNN,以单一的卷积核的大小作为我们的主干,很容易从头开始训练。小尺寸的卷积核保留了空间分辨率,允许我们建立一个深度网络。(2)结合多层特征图,使网络适应行人(头部)尺度和视角的变化。不同的层共享相同的低级特征表示,这会导致更少的参数、更少的训练数据和更快的训练。3.我们引入了一个多任务损失,在密度图损失中加入一个相对的人头损失。对于行人较少的人群场景,该算法显著提高了网络泛化效果。(4)收集新的SmartCity数据集,采用高角度镜头进行人群统计。现有的数据集是从户外采集的,没有充分覆盖那些行人稀少的人群场景。新数据集包含室内和室外场景,每张图像的平均行人数量为7.4。(5)我们对上海科技[33]、UCF CC 50[8]、WorldExpo ’ 10[32]三个数据集进行了广泛的实验,结果表明我们的SaCNN明显优于目前最先进的人群计数方法。我们还将SaCNN与其他具有代表性的智慧城市作品进行了比较,展示了我们的泛化能力。我们的代码和数据集是公开的。
2.相关的工作
我们将人群计数方法分为基于检测的方法和基于回归的方法。下面我们将对这两类方法进行描述,并将其与我们的方法进行比较。
2.1 检测方法
基于检测的方法将群体视为一组检测到的单独实体。早期的工作主要集中在视频监控场景中,这样可以利用动作和外观线索。例如,训练一个动态检测器在视频序列的两个连续帧对上捕获运动和外观信息。这些作品不适用于人群静态图像计数。行人经常被拥挤的人群所遮挡,这在静态图像中估计人群时尤其具有挑战性。因此,利用局部检测器对图像中的行人进行计数,利用重复的深度网络检测人群场景中被遮挡的头部。尽管有了改进,基于检测的方法在人群密集、人群高遮挡的情况下总体上受到严重影响。
2.2 回归方法
基于回归的方法对从人群图像中提取的各种特征进行标量值(行人数)[3,4,15,8]或密度图[5,10,11]的回归。他们基本上有两个步骤:首先,
从人群图像中提取有效特征;其次,利用各种回归函数估计人群数量。早期的作品利用手工制作的特征,如边缘特征[3,5,24,22]和纹理特征[5,8,16]。回归方法包括线性[22,19]、岭[5]和高斯[3]函数。由于使用了强大的CNN特征,最近关于人群计数的工作通过回归图像的密度图显示了显著的进展[32,33,25,1,18]。密度图比标量值提供更多的信息,并且CNNs被证明特别擅长于“局部”解决问题,而不是“全局”。人群计数是一种估计连续密度函数的方法,该函数对任意图像区域的积分给出该区域内行人的数量。设计了一个多任务网络来回归密度图和人群计数。他们使用全连接的层来回归绝对的人群数量。
2.3 与SaCNN的比较
利用多列网络[6]处理一幅图像中头部尺度的变化。不同的列对应不同的卷积核大小。大尺寸的卷积核使得整个网络很难训练。首先对每一列进行网络预训练,最后一起精调;然而,我们的SaCNN使用了具有单个卷积核大小的单一列,可以从头开始训练。[25]引入了一个交换机分类器,使用VGG net[26]将人群补丁从图像中继到最好的CNN列。这种转换代价很高,而且常常不正确。而我们的SaCNN则对多尺度的特征映射进行自适应,并将其串联起来,将每个行人转发到网络中最优尺度。
与[32]类似,我们在SaCNN中执行多任务优化,以回归密度图和人头计数。不同的是,我们的是一个多尺度的全卷积网络,我们提出了一个相对的计数损失。尺度自适应体系结构在精神上类似于[23,13],通过组合多层特征映射;但是我们使用反卷积层[17]来适应网络输出,而不是向上采样和元素求和。我们的网络设计是在人群计数领域中一个新的设计,它具有单滤波器大小和多尺度输出的主干。另外,我们在第1节中声明了总共5个新元素。
3.SaCNN
在本节中,我们首先生成训练数据的ground truth密度图,然后给出SaCNN的体系结构。
3.1 ground truth 密度图
假设我们有一个行人头部在像素Zj位置,我们用δ(z−z j)函数去表示它。ground truth密度图D (z)是δ函数用高斯卷积核Gσ归一化求和得到:
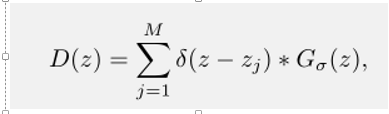
其中M是总人头数。密度图的和等于图像中行人的总数。参数设置如下[33,25,1]。
3.2 网络结构
许多最先进的作品[33,25,1]都采用了不同滤波器尺寸的多列架构来处理人群图像的尺度和透视变化。我们提出了一个scaleadaptivecnn (SaCNN),其中我们使用单一骨干网和单一的滤波器尺寸(见图2)。密度图的估计
在一个级联层进行的,该层合并了来自网络多个尺度的特征图;因此,它可以很容易地适应行人尺度和视角的变化。
我们在网络中都使用3∗3卷积核。3∗3卷积核所需要的计算远远低于大尺寸卷积核[1]。小尺寸的卷积核保留输入的空间分辨率,这样我们就可以建立一个深的网络。“deep”与“wide”(多列体系结构)在网络中的效果类似:例如,一个大的卷积核可以由一个来自更深层的小卷积核来模拟。主干设计(图2中的conv4 3之前)遵循VGG架构[26],在每个池化层之后使用3*3卷积核和3个卷积层。
SaCNN由低级到高级是通过逐步添加不同级别的层来构建的。对于串联,我们需要仔细调整它们的输出,使其具有相同的大小。我们首先提出一个single-scale模型见图3(a):它将conv4_2层得到的输出特征图通过1x1的卷积核在 p-conv里生成一个密度图。图6的结果表明,我们的单尺度模型收敛速度快,性能接近目前的水平。
就像MCNN一样,我们希望我们的模型向不同大小的行人(头部)开火。我们决定再深入一些。我们有三个max-pooling层和几个卷积层,直到conv4 3。在网络的conv4 3之后,我们添加了pool4和3个卷积层(conv5 1到conv5 3)(见图3 (b))。通过提取conv4_3和conv5_3的特征图,提出了一种两尺度模型;我们将pool4的stride设置为1,使两个feature map的尺寸相同;我们将它们串联起来,生成最终的密度图(参见图3 (b))。图6的结果表明,我们的双尺度模型比单尺度模型有了明显的改进。
在两尺度网络的基础上,我们构建了图2所示的尺度自适应模型。然后在网络中添加pool5和conv6 1。为了合并conv5 3和conv6 1,我们将pool4的stride设为2,pool5的stride设为1。我们使用DeConv层将连接的输出向上采样到输入的1/8分辨率,以进一步将其与conv4_3连接起来。因此,最终的密度图的空间分辨率是输入的1/8倍,因此,我们将groundtruth密度图按因子8向下采样。
我们还尝试在较低的分辨率下回归密度图:例如1/16乘以输入分辨率。与1/8分辨率的拼接相比,性能略有下降。我们认为这是因为深层的接受域太大了。
3.3 网络损失函数
我们的网络训练首先采用欧式损失来测量估计的密度图与ground truth之间的距离[33,25,1]:
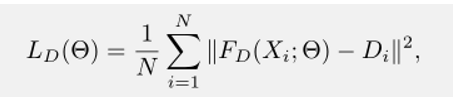
在提出的网络中,Θ是一个可
参数。N为训练图像的个数。X i为输入图像,D i为对应的ground truth密度图。F D(Xi;Θ)表示输入图像Xi的密度估计图。欧几里得距离以像素计算并求和。
除了密度图回归,我们引入了另一个关于人头计数的损失函数(如图2所示)。我们注意到在行人很少的人群场景下就算是目前最好的方法也很难去准确的计数,这个问题不能通过(2)来解决,因为相对于密集人群,稀疏人群的绝对行人数量通常不是很大。为了解决这个问题,我们提出一个相对的人头计数损失:
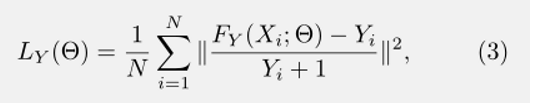
Fy (Xi;Θ)和Yi分别是估计的人数和ground truth人数。分母Yi加1以防止被零除。(3)对预测误差较大的样本进行学习。在那些稀疏人群场景上的测试结果(第4节:表6)表明通过在网络中使用相对的人头损失有了显著的改进。
我们通过随机初始化网络参数直接从头开始训练我们的SaCNN。由于人头计数回归是一个简单的任务,我们首先在密度图(2)上回归模型;一旦它收敛,我们就在目标损失中加入(3)项,共同多次训练一个多任务网络。我们将密度图的损失权重设为1,相对计数损失权重设为0.1。
我们注意到,如果我们先训练一个两尺度模型,然后在它基础上精调SaCNN,那么模型收敛速度会快1.5倍;这两种训练方式的表现差异是微不足道的。
4.实验
首先我们将简要介绍三个标准数据集和一个新创建的用于人群计数的数据集。然后,我们在这些数据集上评估我们的方法。
4.1 数据集
上海科技数据集[33]由1198张无标注图片组成,共330165人,头部中心标注。该数据集分为两部分:PartA和PartB。数据集的统计数据如表1所示:PartB的人群图像相对于PartA比较稀疏。然后,我们在PartA使用300张图片进行训练,182张图片进行测试;400张图片用于训练,316张图片用于测试。
WorldExpo 10数据集[32]包括3980图像,来自上海2010年WorldExpo。以3380帧为训练帧,其余帧为测试帧。测试集包括五个不同的场景,每个场景包含120帧。在每个场景中提供感兴趣区域(ROI),因此在每个帧中只在ROI中进行人群计数。这个数据集的一些统计数据可以在表1中找到。
UCF CC 50数据集[8]共有50幅图像,共63974个head 注释。每个图像的人头数量范围为94到4543。数据集在人数统计的规模差异使其成为一个非常有挑战的数据集。[8]之后,我们执行5次交叉验证来报告平均测试性能。数据集的一些统计数据见表1。
智慧城市数据集是我们自己收集的。从办公入口、人行道、中庭、商场等10个城市场景共采集50幅图像。一些例子如图4所示。它们都是视频监控中高角度拍摄。现有的人群统计数据集包括数百甚至数千名行人的图像,几乎所有的图像都是在户外拍摄的。因此,我们特别创建的数据集在图像中几乎没有行人,包括室外和室内场景。该数据集的一些统计数据如表1所示:每张图像的平均行人数量只有7.4,最小为1,最大为14。我们使用这个数据集来测试提出的框架在稀疏人群场景中的泛化能力。
4.2 细节实现与评估
标准基准中每个head中心的Ground truth注释都是公开可用的。给定一个训练集,我们通过从每个图像中随机裁剪9个patch来增强它。每个patch的大小是原始图像的1/4。所有的patch都用来训练我们的模型SaCNN。我们使用随机梯度下降优化器对模型进行了训练。学习速率从1e-6开始,经过多步长策略后衰减为1e-8。动量为0.9,batchsize大小为1,共训练250个epoch。

图4:智慧城市数据集的示例。它们包括室内和室外的场景,几乎没有行人。
我们采用以往工作中常用的平均绝对误差(MAE)和均方误差(MSE)来评价性能[32,33,25,1,18,29]

Fy和Yi的符号可以参考(3)。较小的MAE和MSE表现良好。
4.3 上海科技上的结果
Ablation study。我们报告了一项消融研究来证明我们的SaCNN在多尺度和多任务设置中的合理性。参照第3节,SaCNN是由低到高,逐步添加不同尺度的层来构建的。网络训练首先集中在密度图的损失上,在它收敛后,加入相对计数损失继续训练。
Multi-scale ablation test。我们针对第3节中的单尺度、双尺度和三尺度(自适应尺度)神经网络分别训练了三个模型。图6显示了它们的性能。可以看出,MAE和MSE从单尺度模型明显下降到双尺度模型;最终,比例自适应模型在PartA和PartB上均达到最低的MAE和MSE。平均而言,PartA的行人数目是PartB的四倍,因此行人的头相当小;而深层特征图则倾向fire大头部(3.2节)。因此,将多尺度的输出组合在一起,并不会导致PartA中MAE和MSE有明显减少。但是,这些结果仍然验证了我们的论点,即互补的特定尺度的特征图产生了强大的尺度自适应人群计数器。在光学实验中,我们采用了三尺度模型。注意在这个测试中,我们只在训练过程中使用密度图loss。
Multi-task ablation test。在上述尺度自适应模型中引入了相对人数损失 (rcl)来提高了在行人较少的人群场景下的网络泛化能力。我们用SaCNN(w/o cl)表示没有计数损失自适应模型和带相对计数损失的SaCNN(rcl)。由表2可知,与SaCNN(w/o cl)相比,SaCNN(rcl)降低了PartA和PartB的MAE和MSE。
为了证明相对计数损失大于绝对计数损失(acl)的合理性,我们[32]之后训练了另一个模型SaCNN(acl),在这个模型中,通过在密度图损失和绝对计数损失的训练之间进行交替,来训练一个多任务网络。表2中的结果显示,增加绝对损失会降低性能。这是因为在不同的人群图像中,绝对计数损失差异很大。在接下来的实验中,我们使用SaCNN来表示我们的最佳模型SaCNN(rcl)。我们还将展示在SmartCity数据集上添加rcl的显著改进(第4.6节)。
Comparison to state-of-the-art。我们将我们的模型SaCNN与PartA和PartB上最先进的模型进行了比较(表3)。我们的方法在PartA和PartB上达到了最好的MAE: 86.8和16.2。与[25]相比,SaCNN对PartA的MAE下降3.6点,对PartB下降5.4点;PartB的MSE下降了7.6个点,PartA的MSE与之相当。与[25]相比,SaCNN需要更少的计算,他们将测试图像分割成补丁,并使用分类和回归网络来测试每个补丁。在测试时,SaCNN比[25]快2倍(293ms vs. 580ms per image)。
图5展示了PartA和PartB的一些例子。估计的密度图是真实图像中人群分布的直观模拟。我们分别给出了密度图和真实图像下的预测值和真实行人数。估计的行人数量接近真实数字。
4.4 WorldExpo10的结果
参照[32],训练和测试都是在每个场景提供的ROI范围内进行的。为每个测试场景报告MAE,并对其进行平均,以评估总体性能。在表4中,我们将我们的SaCNN与其他最先进的技术进行了比较。符号即(GT w / o perspective)和(GT perspective)表示在(1)中σ的选择。在某些像素计算σ作为透视值的比例。但是,[25]在不使用透视值的情况下报告了更好的结果。我们提供有无透视的结果。可以看出,除了在S4上,在其余所有场景中,SaCNN(带透视的GT)都不如SaCNN(不带透视的GT)。SaCNN(GT w/o perspective)在S1、S2和S5上产生的最大MAE分别为2.6、13.5和3.3。场景间SaCNN的平均MAE比[25]好了0.9个点,达到最好的8.5。
4.5 UCF CC 50的结果
我们将我们的方法与表5中UCF CC 50[32, 33, 25, 11, 8, 1, 18]上现有的7种方法进行了比较。[11]提出了一个密度回归模型来回归人群统计中的密度图而不是行人数量。[8]使用多源特征估计人群数量,[1]使用多列CNN,其中一列由VGG net[26]初始化。[18]采用自定义CNN网络,网络是每个尺度单独训练;全连接层用于融合在特定比例下训练的每个CNN的特征图。
我们的方法达到了与最先进的相比最好的成绩,MAE 314.9、MSE 424.8。最小的MSE表示在整个数据集中我们的预测的最小方差。
4.6 SmartCity的结果
对于智慧城市来说,行人太少,无法训练模型。我们采用在上海科技PartB上训练好的模型,在智慧城市上进行测试。上海科技 PartB的人群场景都是户外和相对稀疏而SmartCity他们都是室内和室外的场景几乎没有行人(平均7.4,见表1和图4)。参考4.3节在上海科技上的多任务ablation test,我们在表6中测试SaCNN cl(w / o)和SaCNN,去显示SaCNN比SaCNN cl(w / o)的效果改善。通过在网络中加入相对计数损失,MAE和MSE明显地分别下降了9.2和11.8个点。图7给出了一些测试示例。SaCNN生成的密度图较SaCNNw/o cl)更稀疏;它效果也更好。而SaCNN(w/o cl)的结果反映了与行人无关图片更多精细的细节。
在表6中,我们还测试了[33,25]:两者都在PartB上训练,在SmartCity上表现不佳;MAE分别为40.0和23.4。我们最好的MAE是8.6,接近行人的平均数字7.4。在稀疏的人群场景中加入相对计数损失可以显著提高网络的泛化效果。
总的来说,我们的结果并不完美,我们认为这使得数据集对于未来的工作是一个具有挑战性的任务。
4.7 回归VS检测
在本节中,我们将基于回归的方法SaCNN与基于检测的方法YOLO9000[21]进行比较。
没有用于人群计数数据集的边界框注释,并且在密集的人群中用边界框注释每一个行人头部一般是不可行的(见图8)。因此,我们在可可数据集上训练一个行人检测器[14]。我们还在COCO中注释了行人头部边界框,并训练了头部检测器。我们在上海科技PartA和PartB,以及智慧城市上测试这两款产品。这些数据集中的人群场景从非常稀疏到非常密集(见表1)。由于人群图像是从高角度拍摄的,因此COCO训练的检测器在人群图像上可能效果不好。因此,我们总是报告在人群图像上效果更好的那个。结果如表7所示。在检测背景中,利用被检测的边界框与ground truth边界框之间的IoU来衡量检测的好坏;置信度评分(cs)的阈值设置为高,如cs > 0.5。在人群计数的背景下,通过估计计数与ground truth计数的差值来衡量一个好的预测;具有较低的阈值,如cs > 0.05,预测结果更大。然而,更大的预测反映出人群中MAE/MSE较低,因为YOLO通常会错过图像中的小物体。表7分别用YOLO9000 cs > 0.05和cs> 0.5说明了这两个结果:我们的SaCNN在上海科技PartA和PartB上显著优于YOLO9000;但在SmartCity上,它比YOLO9000稍差一点。总的来说,我们认为基于回归的SaCNN的优点是提供了一种强大方法,在从稀疏到密集的广泛数据集上执行的性能接近或高于最先进的水平。对于非常稀疏的情况,基于检测的方法可能更好,但在密集的情况下,它的性能不会很好。目前尚不清楚如何将探头法与密度法结合起来,这可能是我们未来的工作。
我们在图8中举例说明。在这三个样本中,行人的数量从非常稀疏到非常密集分布。我们举例说明行人检测器和头部检测器的结果。使用小阈值的置信度可以产生大的预测,但是边界框并不总是准确的(例如第一行:PD - cs > 0.05)。总的来说,YOLO9000擅长在稀疏人群中检测大目标,而在密集人群中检测小目标则不太好。相比之下,SaCNN能很好地从非常稀疏到非常密集的情况进行泛化。
5. 结论
本文提出一种尺度自适应卷积神经网络(SaCNN)来自动估计人群图像的密度图和行人数量。它将不同尺度的多个特征映射串联起来,为每个图像生成一个强尺度自适应人群计数器;该算法引入了包括相对计数损失在内的多任务损失,提高了行人较少的人群场景的网络泛化能力。该方法可以方便地适应不同尺度和角度的行人。在标准人群计数基础上进行的额外实验证明了该方法的有效性。
我们知道行人的大小会随着人群图像透视变化而变化;而SaCNN的多特征地图则对不同大小的行人开火。在以后的工作中,我们希望将透视信息作为一个加权层直接映射到SaCNN中。它将根据透视图的不同,在每个像素上产生不同的特征图输出权值。
测试代码链接c++
- 点赞
- 收藏
- 分享
- 文章举报
 Alvin_zy
发布了24 篇原创文章 · 获赞 0 · 访问量 714
私信
关注
Alvin_zy
发布了24 篇原创文章 · 获赞 0 · 访问量 714
私信
关注

- SaCNN(论文解读)-人群计数
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 论文翻译(转)
- 开始翻译Fielding的博士论文
- 论文翻译:Anytime Stereo Image Depth Estimation on Mobile Devices
- [行为识别]论文翻译-Hidden Two-Stream Convolutional Networks for Action Recognition
- Arcface v3 论文翻译与解读
- 关于2014年相关人脸检测识别的几个论文摘要翻译
- 全球分布式数据库:Google Spanner(论文翻译)
- R-FCN论文翻译——中英文对照
- RCNN学习笔记(7):Faster R-CNN 英文论文翻译笔记
- Classification of Time-Series Images Using Deep Convolutional Neural Networks论文翻译
- CVPR 2017论文集锦(论文分类)—— 附录部分翻译
- 【深度学习:目标检测】RCNN学习笔记(7):Faster R-CNN 英文论文翻译笔记
- Hierarchical Convolutional Features for Visual Tracking(CF2)论文翻译
- CRNN论文翻译——中文版
- 图像识别--翻译论文
- RAFT 论文中文翻译(1)
- 经典论文翻译导读之《Large-scale Incremental Processing Using Distributed Transactions and Notifications》
- 分布式系统领域经典论文翻译集
- MTCNN论文翻译