redis-cluster集群部署
Redis3.0 集群搭建
一、设计原理
1. 设计要点
1.1 集群架构
redis集群采用无中心节点方式实现,无需proxy代理,客户端直接与redis集群的每个节点连接,根据同样的hash算法计算出key对应的slot,然后直接在slot对应的redis上执行命令。在redis看来,响应时间是最苛刻的条件,增加一层带来的开销是redis不原因接受的。因此,redis实现了客户端对节点的直接访问,为了去中心化,节点之间通过Gossip协议交换互相的状态,以及探测新加入的节点信息。redis集群支持动态加入节点,动态迁移slot,以及自动故障转移。

每个节点都会跟其他节点保持连接,用来交换彼此的信息。节点组成集群的方式使用clustermeet命令,meet命令可以让两个节点相互握手,然后通过gossip协议交换信息。如果一个节点r1在集群中,新节点r4加入的时候与r1节点握手,r1节点会把集群内的其他节点信息通过gossip协议发送给r4,r4会一一与这些节点完成握手,从而加入到集群中。
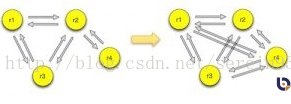
节点在启动的时候会生成一个全局的标识符,并持久化到配置文件,在节点与其他节点握手后,这些信息也都持久化下来。节点与其他节点通信,标识符是它唯一的标识,而不是IP、PORT地址。如果一个节点移动位置导致IP、PORT地址发生变更,集群内的其他节点能把该节点的IP、PORT地址纠正过来。
1.2 数据分布
Redis集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot.

key与slot映射使用的CRC16算法,即:slot =CRC16(key) mod 16384。
集群只有在16384个slot都有对应的节点才能正常工作。slot可以动态的分配、删除和迁移。
每个节点会保存一份数据分布表,节点会将自己的slot信息发送给其他节点,发送的方式使用一个unsigned char的数组,数组长度为16384/8。每个bit标识为0或者1来标识某个slot是否是它负责的。

redis目前还支持slot的迁移,可以把一个slot从一个节点迁移到另一个节点,节点上的数据需要使用者通过cluster getkeysinslot去除迁移slot上的key,然后执行migrate命令一个个迁移到新节点。
其结构特点:
1、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2、节点的fail是通过集群中超过半数的节点检测失效时才生效。
3、客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4、redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。
5、Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
举例:三个主节点分别是:A, B, C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器
区间分配:节点A覆盖0-5460;
节点B覆盖5461-10922;
节点C覆盖10923-16383.
获取数据:
如果存入一个值,按照redis cluster哈希槽的算法: CRC16('key')384 = 6782。 那么就会把这个key 的存储分配到 B 上了。同样,当我连接(A,B,C)任何一个节点想获取'key'这个key时,也会这样的算法,然后内部跳转到B节点上获取数据。
新增主节点:
新增一个节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot到D上,我会在接下来的实践中实验。大致就会变成这样:
节点A覆盖1365-5460
节点B覆盖6827-10922
节点C覆盖12288-16383
节点D覆盖0-1364,5461-6826,10923-12287
同样删除一个节点也是类似,桶移动完成后就可以删除这个节点了。
1.3 集群访问
客户端在初始化的时候只需要知道一个节点的地址即可,客户端会先尝试向这个节点执行命令,比如“getkey”,如果key所在的slot刚好在该节点上,则能够直接执行成功。如果slot不在该节点,则节点会返回MOVED错误,同时把该slot对应的节点告诉客户端。客户端可以去该节点执行命令。目前客户端有两种做法获取数据分布表,一种就是客户端每次根据返回的MOVED信息缓存一个slot对应的节点,但是这种做法在初期会经常造成访问两次集群。还有一种做法是在节点返回MOVED信息后,通过cluster nodes命令获取整个数据分布表,这样就能每次请求到正确的节点,一旦数据分布表发生变化,请求到错误的节点,返回MOVED信息后,重新执行clusternodes命令更新数据分布表。
1.4 主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉。
上面那个例子里, 集群有ABC三个主节点, 如果这3个节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群了。A和C的slot也无法访问。
所以我们在集群建立的时候,一定要为每个主节点都添加了从节点, 比如像这样, 集群包含主节点A、B、C, 以及从节点A1、B1、C1, 那么即使B挂掉系统也可以继续正确工作。
B1节点替代了B节点,所以Redis集群将会选择B1节点作为新的主节点,集群将会继续正确地提供服务。 当B重新开启后,它就会变成B1的从节点。
不过需要注意,如果节点B和B1同时挂了,Redis集群就无法继续正确地提供服务了。
集群间节点建立主从关系不再使用原有的SLAVEOF命令和SLAVEOF配置,而是通过cluster replicate命令,这保证了主从节点需要先完成握手,才能建立主从关系。
集群是不能组成链式主从关系的,也就是说从节点不能有自己的从节点。不过对于集群外的没开启集群功能的节点,redis并不干预这些节点去复制集群内的节点,但是在集群故障转移时,这些集群外的节点,集群不会处理。
集群内节点想要复制另一个节点,需要保证本节点不再负责任何slot,不然redis也是不允许的。
集群内的从节点在与其他节点通信的时候,传递的消息中数据分布表和epoch是master的值。
1.5 故障转移
集群主节点出现故障,发生故障转移时,其他主节点会把故障主节点的从节点自动提为主节点,原来的主节点恢复后,自动成为新主节点的从节点。
集群把一个master和它的全部slave描述为一个group,故障转移是以group为单位的,集群故障转移的方式跟sentinel的实现很类似。某个master节点一段时间没收到心跳响应,则集群内的master会把该节点标记为pfail,类似sentinel的sdown。集群间的节点会交换相互的认识,超过一半master认为该异常master宕机,则这些master把异常master标记为fail,类似sentinel的odown。fail消息会被master广播出来。group的slave收到fail消息后开始竞选成为master。竞选的方式跟sentinel选主的方式类似,都是使用了raft协议,slave会从其他的master拉取选票,票数最多的slave被选为新的master,新master会马上给集群内的其他节点发送pong消息,告知自己角色的提升。其他slave接着开始复制新master。等旧master上线后,发现新master的epoch高于自己,通过gossip消息交互,把自己变成了slave。
2. 原始设计改进
2.1 EmbeddedString
redis3.0中,如果字符串长度小于39,则会使用ebeded string,将robj和字符串分配在一块连续内存中。由于局部性原理,在读取时,robj和字符串内容都会读到cache中,从而只要一次内存读取即可。
长度限制在39的原因是,redis使用jemalloc,会以64字节为一个内存块进行分配。robj(16字节),sds的头部(16字节)和字符串结尾的’\0'会占用25字节。

redis中所有的key都是字符串类型,所以这个优化会大幅提升redis的cache命中率。在实际使用时,可以尽量将key的大小限制在39字节内,充分利用cache,提升性能。
2.2 AOF Rewrite
父子进程间建立pipe进行通信。在子进程进行rewrite期间,父进程会不断的通过pipe向子进程发送aof diff,子进程会不停的收集到aof rewrite buffer中。当子进程完成rewrite后。会通知父进程停止发送aof diff。然后子进程将收集到的aof rewrite buffer追加到重写后的aof文件的最后。
父进程完成对子进程收割后,会把剩余的rewrite buffer追加到aof文件(这个rewrite buffer相对要小一些)。
改进点:
- 大部分的磁盘操作由子进程完成,父进程只需进行小数据量的磁盘操作
-aof rewrite buffer的输出会被打散到每个命令的处理过程中,降低延迟,不会造成大的抖动
2.3 LRU近似算法改进
填充eviction_pool时,随机选择16个key,并按照插入排序添加到pool中。填充完之后,选择pool的最后一个元素(idle最大)作为踢出对象。
改进点:
- 精度改为毫秒,更精确
- 避免每次lru踢出时,需要多次迭代选择踢出对象
2.4 INCR命令
redis为了节省内存,对于可以整数化的字符串直接以long型存储(只占8个字节)。并且redis有一个整数常量池,对于在[0,10000]内的整数,直接引用常量池中的对象。3.0对大于10000,不命中常量池的场景做了优化,可以避免hash查找,以及对象创建。在没有命中常量池并且引用计数为1的情况,直接修改对象的值,不需要hash查找以及创建新对象。其余情况,还走原来的流程。
之所以只有引用计数为1时才进行优化,是避免与其他逻辑共享对象,造成不一致(比如key,重新编码后,hash查找会失败)。
3. 数据存储
Redis3.0在启动时会自动在启动命令执行的当前目录下生成两个文件,即dump.rdb和nodes.conf
●nodes.conf是记录自身ID,分配的桶区间等标识性信息。主节点文件中会记录集群所有主节点ID以及各主节点当前有几个连接
●dump.db 是数据快照记录文件,默认情况下每隔一段时间redis服务器程序会自动对数据库做一次遍历,把内存快照写在一个叫做“dump.rdb”的文件里,这个持久化机制叫做SNAPSHOT。有了SNAPSHOT后,如果服务器宕机,重新启动redis服务器程序时redis会自动加载dump.rdb,将数据库状态恢复到上一次做SNAPSHOT时的状态。可以redis.conf中配置间隔扫描时间。
●appendonly.aof 如果在redis.conf中开启了appendonly功能,则会系统会生成此文件。
AOF和RDB各有优缺点,这是有它们各自的特点所决定:
● AOF更加安全,可以将数据更加及时的同步到文件中,但是AOF需要较多的磁盘IO开支,AOF文件尺寸较大,文件内容恢复数度相对较慢。
● snapshot,安全性较差,它是“正常时期”数据备份以及master-slave数据同步的最佳手段,文件尺寸较小,恢复数度较快。
可以通过配置文件来指定它们中的一种,或者同时使用它们(不建议同时使用),或者全部禁用,在架构良好的环境中,master通常使用AOF,slave使用snapshot,主要原因是master需要首先确保数据完整性,它作为数据备份的第一选择;slave提供只读服务(目前slave只能提供读取服务),它的主要目的就是快速响应客户端read请求;但是如果你的redis运行在网络稳定性差/物理环境糟糕情况下,建议你master和slave均采取AOF,这个在master和slave角色切换时,可以减少“人工数据备份”/“人工引导数据恢复”的时间成本;如果你的环境一切非常良好,且服务需要接收密集性的write操作,那么建议master采取snapshot,而slave采用AOF。
3.1 RDB数据存储
RDB是在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点:使用单独子进程来进行持久化,主进程不会进行任何IO操作,保证了redis的高性能
缺点:RDB是间隔一段时间进行持久化,如果持久化之间redis发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候
这里说的这个执行数据写入到临时文件的时间点是可以通过配置来自己确定的,通过配置redis在n秒内如果超过m个key被修改这执行一次RDB操作。这个操作就类似于在这个时间点来保存一次Redis的所有数据,一次快照数据。所有这个持久化方法也通常叫做snapshots。
RDB默认开启,redis.conf中的具体配置参数如下;
#dbfilename:持久化数据存储在本地的文件
dbfilename dump.rdb
#dir:持久化数据存储在本地的路径,如果是在/redis/redis-3.0.6/src下启动的redis-cli,则数据会存储在当前src目录下
dir ./ 持久化数据存储在本地的路径,如果是在/redis/redis-3.0.6/src下启动的redis-cli,则数据会存储在当前src目录下
##snapshot触发的时机,save <seconds> <changes>
##如下为900秒后,至少有一个变更操作,才会snapshot
##对于此值的设置,需要谨慎,评估系统的变更操作密集程度
##可以通过“save “””来关闭snapshot功能
#save时间,以下分别表示更改了1个key时间隔900s进行持久化存储;更改了10个key300s进行存储;更改10000个key60s进行存储。
save 900 1
save 300 10
save 60 10000
##当snapshot时出现错误无法继续时,是否阻塞客户端“变更操作”,“错误”可能因为磁盘已满/磁盘故障/OS级别异常等
stop-writes-on-bgsave-erroryes
##是否启用rdb文件压缩,默认为“yes”,压缩往往意味着“额外的cpu消耗”,同时也意味这较小的文件尺寸以及较短的网络传输时间
rdbcompressionyes
snapshot触发的时机,是有“间隔时间”和“变更次数”共同决定,同时符合2个条件才会触发snapshot,否则“变更次数”会被继续累加到下一个“间隔时间”上。snapshot过程中并不阻塞客户端请求。snapshot首先将数据写入临时文件,当成功结束后,将临时文件重名为dump.rdb。
使用RDB恢复数据:
自动的持久化数据存储到dump.rdb后。实际只要重启redis服务即可完成(启动redis的server时会从dump.rdb中先同步数据)
客户端使用命令进行持久化save存储:
./redis-cli -hip -p port save
./redis-cli -hip -p port bgsave
一个是在前台进行存储,一个是在后台进行存储。我的client就在server这台服务器上,所以不需要连其他机器,直接./redis-cli bgsave。由于redis是用一个主线程来处理所有client的请求,这种方式会阻塞所有client请求。所以不推荐使用。另一点需要注意的是,每次快照持久化都是将内存数据完整写入到磁盘一次,并不是增量的只同步脏数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘io操作,可能会严重影响性能。
3.2 AOF数据存储
Append-only file,将“操作 + 数据”以格式化指令的方式追加到操作日志文件的尾部,在append操作返回后(已经写入到文件或者即将写入),才进行实际的数据变更,“日志文件”保存了历史所有的操作过程;当server需要数据恢复时,可以直接replay此日志文件,即可还原所有的操作过程。AOF相对可靠,它和mysql中bin.log、apache.log、zookeeper中txn-log简直异曲同工。AOF文件内容是字符串,非常容易阅读和解析。
优点:可以保持更高的数据完整性,如果设置追加file的时间是1s,如果redis发生故障,最多会丢失1s的数据;且如果日志写入不完整支持redis-check-aof来进行日志修复;AOF文件没被rewrite之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的flushall)。
缺点:AOF文件比RDB文件大,且恢复速度慢。
我们可以简单的认为AOF就是日志文件,此文件只会记录“变更操作”(例如:set/del等),如果server中持续的大量变更操作,将会导致AOF文件非常的庞大,意味着server失效后,数据恢复的过程将会很长;事实上,一条数据经过多次变更,将会产生多条AOF记录,其实只要保存当前的状态,历史的操作记录是可以抛弃的;因为AOF持久化模式还伴生了“AOF rewrite”。
AOF的特性决定了它相对比较安全,如果你期望数据更少的丢失,那么可以采用AOF模式。如果AOF文件正在被写入时突然server失效,有可能导致文件的最后一次记录是不完整,你可以通过手工或者程序的方式去检测并修正不完整的记录,以便通过aof文件恢复能够正常;同时需要提醒,如果你的redis持久化手段中有aof,那么在server故障失效后再次启动前,需要检测aof文件的完整性。
AOF默认关闭,开启方法,修改配置文件reds.conf:appendonly yes
##此选项为aof功能的开关,默认为“no”,可以通过“yes”来开启aof功能
##只有在“yes”下,aof重写/文件同步等特性才会生效
appendonly yes
##指定aof文件名称
appendfilename appendonly.aof
##指定aof操作中文件同步策略,有三个合法值:always everysec no,默认为everysec
appendfsync everysec
##在aof-rewrite期间,appendfsync是否暂缓文件同步,"no"表示“不暂缓”,“yes”表示“暂缓”,默认为“no”
no-appendfsync-on-rewrite no
##aof文件rewrite触发的最小文件尺寸(mb,gb),只有大于此aof文件大于此尺寸是才会触发rewrite,默认“64mb”,建议“512mb”
auto-aof-rewrite-min-size 512mb
##相对于“上一次”rewrite,本次rewrite触发时aof文件应该增长的百分比。
##每一次rewrite之后,redis都会记录下此时“新aof”文件的大小(例如A),那么当aof文件增长到A*(1 + p)之后
##触发下一次rewrite,每一次aof记录的添加,都会检测当前aof文件的尺寸。
auto-aof-rewrite-percentage 100
AOF是文件操作,对于变更操作比较密集的server,那么必将造成磁盘IO的负荷加重;此外linux对文件操作采取了“延迟写入”手段,即并非每次write操作都会触发实际磁盘操作,而是进入了buffer中,当buffer数据达到阀值时触发实际写入(也有其他时机),这是linux对文件系统的优化,但是这却有可能带来隐患,如果buffer没有刷新到磁盘,此时物理机器失效(比如断电),那么有可能导致最后一条或者多条aof记录的丢失。通过上述配置文件,可以得知redis提供了3中aof记录同步选项:
always:每一条aof记录都立即同步到文件,这是最安全的方式,也以为更多的磁盘操作和阻塞延迟,是IO开支较大。
everysec:每秒同步一次,性能和安全都比较中庸的方式,也是redis推荐的方式。如果遇到物理服务器故障,有可能导致最近一秒内aof记录丢失(可能为部分丢失)。
no:redis并不直接调用文件同步,而是交给操作系统来处理,操作系统可以根据buffer填充情况/通道空闲时间等择机触发同步;这是一种普通的文件操作方式。性能较好,在物理服务器故障时,数据丢失量会因OS配置有关。
其实,我们可以选择的太少,everysec是最佳的选择。如果你非常在意每个数据都极其可靠,建议你选择一款“关系性数据库”吧。
AOF文件会不断增大,它的大小直接影响“故障恢复”的时间,而且AOF文件中历史操作是可以丢弃的。AOF rewrite操作就是“压缩”AOF文件的过程,当然redis并没有采用“基于原aof文件”来重写的方式,而是采取了类似snapshot的方式:基于copy-on-write,全量遍历内存中数据,然后逐个序列到aof文件中。因此AOF rewrite能够正确反应当前内存数据的状态,这正是我们所需要的;*rewrite过程中,对于新的变更操作将仍然被写入到原AOF文件中,同时这些新的变更操作也会被redis收集起来(buffer,copy-on-write方式下,最极端的可能是所有的key都在此期间被修改,将会耗费2倍内存),当内存数据被全部写入到新的aof文件之后,收集的新的变更操作也将会一并追加到新的aof文件中,此后将会重命名新的aof文件为appendonly.aof,此后所有的操作都将被写入新的aof文件。如果在rewrite过程中,出现故障,将不会影响原AOF文件的正常工作,只有当rewrite完成之后才会切换文件,因为rewrite过程是比较可靠的。
触发rewrite的时机可以通过配置文件来声明,同时redis中可以通过bgrewriteaof指令人工干预。
redis-cli -h ip -p port bgrewriteaof
因为rewrite操作/aof记录同步/snapshot都消耗磁盘IO,redis采取了“schedule”策略:无论是“人工干预”还是系统触发,snapshot和rewrite需要逐个被执行。
AOF rewrite过程并不阻塞客户端请求。系统会开启一个子进程来完成。
二、搭建步骤
注:必须要3个以上的主节点,否则在创建集群时会失败(集群中至少应该有奇数个节点,所以至少有三个节点,每个节点至少有一个备份节点,所以下面使用6节点(主节点、备份节点由redis-cluster集群确定))
1. 安装依懒包
yum–y install gcc gcc-c++ make automake autoconf zlib-devel openssl-devel
注: gcc等包为编译软件需要
zlib-devel和openssl-devel为ruby编译需要,因为当使用ruby安装的gem工具安装redis-3.3.2.gem时,系统会自动寻找一些动态库文件
2. 安装redis(以3.0.7版为例)
Redis集群环境 192.168.110.171redis1
192.168.110.172 redis2
192.168.110.173redis3
192.168.110.174 redis4
192.168.110.175 redis5
192.168.110.176 redis6
下载redis-3.0.7.tar.gz
tarxf redis-3.0.7.tar.gz /opt
cd /opt/redis-3.0.7
make
makeinstall PREFIX=/usr/local/redis-cluster 通过PREFIX参数指定redis安装目录
cp /opt/redis-3.0.7/src/redis-trib.rb/usr/local/redis-cluster/ 此处redis-trib.rb为redis集群主管理工具,集群节点的启动,检测,添加,删除,重分配等都需要使用它来完成
cp/opt/redis-3.0.7/redis.conf /usr/local/redis-cluster/ 此处redis.conf为redis主配置文件,其中参数需要手动修改
注:同机多端口此处在redis-cluster目录自建对应目录,将修改后的redis.conf分别拷贝到各个目录
修改redis.conf参数:
daemonizeyes #后台启动
port6379 此为redis服务端口,同机多端口需修改此处,如7001到7006等根据实际需求选一
cluster-enabledyes 去掉原注释符,此为开启集群模式
cluster-config-filenodes.conf 此为redis运行过程中的配置文件,在redis启动时自动生成在当前目录中。此文件不用人为修改,redis运行过程中会根据实际变化自动修改,redis的ID,主从标识,所管理桶大小等都存在此文件中。如同机多端口时,此注意redis启动命令的执行位置,否则会产生文件冲突,最好将配置文件名中加入对应端口标识。
cluster-node-timeout15000 秒级时间内没有收到对方的回复,则单方面认为对端节点宕机
appendonlyyes 开启AOF模式,即开启持久化
cluster-require-full-coverageyes 修改为no,默认情况下Redis集群各节点在检测到至少一个hash槽位遗漏的情况下会停止处理查询请求(不可达节点会处理这个遗漏的槽位)在这种情况下如果集群部分节点宕机(例如部分hash槽位没有被分配)会造成整个集群不可用。集群直到所有槽位均被分配时才自动回复为可用状态,但是有时我们希望集群的一个子集正常工作,对active的部分keyspace继续接收并执行请求。为达到这种效果, 请将cluster-require-full-coverage设置为no。
no-appendfsync-on-rewrite 如果该参数设置为no(默认),是最安全的方式,不会丢失数据,但是要忍受阻塞的问题。如果设置为yes呢?这就相当于将appendfsync设置为no,这说明并没有执行磁盘操作,只是写入了缓冲区,因此这样并不会造成阻塞(因为没有竞争磁盘),但是如果这个时候redis挂掉,就会丢失数据。丢失多少数据呢?在Linux的操作系统的默认设置下,最多会丢失30s的数据。因此,如果应用系统无法忍受延迟,而可以容忍少量的数据丢失,则设置为yes。如果应用系统无法忍受数据丢失,则设置为no。
cluster-migration-barrier1 一个主节点在拥有多少个好的从节点的时候就要割让一个从节点出来给其他没有从节点或者从节点挂掉的主节点
3. 安装ruby环境
Redis脚本由ruby编写,所以必须安装ruby环境
下载ruby2.3.1.tar.gz
tarxf ruby2.3.1.tar.gz /opt
cdruby-2.3.1
./configure--prefix=/usr/local/ruby/
make
makeinstall
gem install redis-3.2.2.gem 此步骤不要忘记,否则启动时ruby环境和redis无法关联,默认是连网安装,如集群环境处于内网状态,请加-l参数
配置环境变量:REDIS_HOME和RUBY_HOME
exportRUBY_HOME=/usr/local/ruby
exportPATH=${RUBY_HOME}/bin:${PATH}
exportREDIS_HOME=/usr/local/redis-cluster
exportPATH=${REDIS_HOME}/bin:${PATH}
到此,redis安装完成。
启动各redis节点,使用redis-server redis.conf启动。
通过 ps -ef |grep redis 可查看启动是否成功。
客户端连接,使用redis-cli -c -h 192.168.110.171 -p 6349访问
4. 创建集群
创建集群使用主管理工具redis-trib.rb,此为ruby脚本
redis-trib.rbcreate --replicas 1 192.168.110.171:6379 192.168.110.172:6379 192.168.110.173:6379192.168.110.174:6379 192.168.110.175:6379 192.168.110.176:6379
create 为redis-trib.rb参数,创建集群ip:port ipN:portN
--replicas 设置从节点个数,集群会根据此处设置的值和后面设置ip:port对的个数来自动划分主从关系,如此处设置1,则集群会默认划分前三台为主节点,后三台为从节点。此参数为均衡划分主从节点,如不均衡划分,可设置此值为0,稍后使用命令行方式手动设置主从关系。
均衡划分举例:
--replicas 1 每个主节点有一个从节点,即节点个数必须为双数
--replicas 2 每个主节点有两个从节点,即节点个数必须为双数,必须保证总节点个数,划分不每个节点两个从节点够分配,否则系统会提示节点数不足
--replicas 0不划分主从关系
5. 设置集群密码
1) 使用redis-trib.rb构建集群完成前不要配置密码。
2) 集群构建完通过config set 设置密码,再通过config rewrite写入配置文件。
3) 集群密码设置参数为配置文件中的requirepass和masterauth都需要设置。
A.修改客户端脚本,配置自定义的密码
vim /opt/ruby2.3.1/lib/ruby/gems/2.3.0/gems/redis-3.3.3/lib/redis/client.rb
:password => nil, 改为 :password => 'guiducx', guiducx为自定义密码
B.通过客户端连接修改集群密码
redis-cli -c -h192.168.111.246 -p 51103 config set masterauth guiducx
redis-cli -c -h192.168.111.246 -p 51103 config set requirepass guiducx
redis-cli -c -h192.168.111.246 -p 51103 -a 'guiducx' config rewrite
4) 各个节点要逐个设置,而且密码必须一致。
三、重点注意事项
1. openssl-devel和zlib-devel依赖包一定要先安装
2. gem install本地化安装一定要加-l参数,否则默认联网安装
3. redis-cli连接客户端一定要加-c参数,否则不会自动重定向
4. redis默认端口为配置文件中的port设置,但redis还有一个内置的通信端口为默认端口+10000
5. 启动多个实例,配置文件中的port, pid, nodes.conf,logfile,appendfile, dump.rb一定要根据各自端口区分开
四、集群优化
1. redis.conf配置参数优化
daemonizeyes
tcp-backlog511 在高并发的环境下,你需要把这个值调高以避免客户端连接缓慢的问题,Linux 内核会一声不响的把这个值缩小成 /proc/sys/net/core/somaxconn 对应的值,所以要修改这两个值才能达到预期。
timeout60 指定在一个 client 空闲多少秒之后关闭连接(0 就是不管它)
bind本机ip地址
tcp-keepalive60
maxmemory10gb 默认空,根据实际改变
dir/data/redis/6300 默认当前目录,根据实际改变
slave-serve-stale-datayes 当一个 slave 与 master 失去联系,或者复制正在进行的时候,slave 可能会有两种表现:1) 如果为 yes ,slave 仍然会应答客户端请求,但返回的数据可能是过时,或者数据可能是空的在第一次同步的时候2) 如果为 no ,在你执行除了 info he salveof 之外的其他命令时,slave 都将返回一个 "SYNC with master in progress" 的错误。
#slave只读
slave-read-onlyyes
#notuse default
repl-disable-tcp-nodelayyes 默认是no,在slave和master同步后(发送psync/sync),后续的同步是否设置成TCP_NODELAY,假如设置成yes,则redis会合并小的TCP包从而节省带宽,但会增加同步延迟(40ms),造成master与slave数据不一致,假如设置成no,则redis master会立即发送同步数据,没有延迟,前者关注性能,后者关注一致性
appendonlyyes #打开aof持久化
#每秒一次aof写
appendfsynceverysec
#关闭在aof rewrite的时候对新的写操作进行fsync
no-appendfsync-on-rewriteyes 默认no,如果应用系统无法忍受延迟,而可以容忍少量的数据丢失,则设置为yes。如果应用系统无法忍受数据丢失,则设置为no。
auto-aof-rewrite-min-size5gb 默认64mb,太小了,根据实际适当调大,减少aofrewrite频率。
#打开redis集群
cluster-enabledyes
cluster-config-file/data/redis/6300/nodes-6300.conf 根据实际修改路径
#节点互连超时的阀值(单位毫秒)
cluster-node-timeout15000 默认是15秒,可适当调大一点,一般默认即可。
#一个主节点在拥有多少个好的从节点的时候就要割让一个从节点出来给其他没有从节点或者从节点挂掉的主节点
cluster-migration-barrier1
#如果某一些key space没有被集群中任何节点覆盖,最常见的就是一个node挂掉,集群将停止接受写入
cluster-require-full-coverageno
#部署在同一机器的redis实例,把auto-aof-rewrite搓开,防止瞬间fork所有redis进程做rewrite,占用大量内存
auto-aof-rewrite-percentage80-100 同一机器把不同端口配置文件中此值改成不同的值。
2. sysctl内核优化
vm.overcommit_memory= 1 忽略当前内存状态,允许分配所有物理内存
3. linux系统优化
1)设置limit nofile数,根据实际需求
2)关闭hugepagre
echo never >/sys/kernel/mm/redhat_transparent_hugepage/enabled
echo 'echo never >/sys/kernel/mm/redhat_transparent_hugepage/enabled' >> /etc/rc.local
3)sysctl -wnet.ipv4.tcp_timestamps=1 开启对于TCP时间戳的支持,若该项设置为0,则下面一项设置不起作用,同时修改/etc/sysctl.conf
4)sysctl -wnet.ipv4.tcp_tw_recycle=1 表示开启TCP连接中TIME-WAIT sockets的快速回收,同时修改/etc/sysctl.conf
5)sysctl -wvm.overcommit_memory=1 忽略当前内存状态,只认为内存永远充足,同时修改/etc/sysctl.conf
4. redis内存优化
1) 设置配置文件中的maxmemory
2) 调整配置文件中不同数据类型的一组参数
3) 确认持久化的配置方式,可以丢几秒数据,可只开启rdb模式,不能丢数据,开启rdb和aof模式
4) 根据实际key写操作频率设置save时间间隔,写频率高的环境可只保留save 900 1一行
5) 根据实际需求选择maxmemory-policy,默认是不清除key
5. 数据文件容量优化
1) 设置合理的key生存周期,保证rdb降低rdb文件持续增长速度
2) 定期任务执行bgrewriteaof,降低aof文件容量大小(去重)
附录1:集群服务端相关命令
redis-trib.rb check ip:port
检查集群节点
redis-trib.rb add-node nip:nport sip:sport
新增集群主节点,nip:nport为新节点,sip:sport为原集群中任一节点,只为标识往哪个集群中添加节点
redis-trib.rb add-node --slave nip:nport sip:sport
新增集群从节点,nip:nport为新节点,sip:sport为原集群中任一节点,只为标识往哪个集群中添加节点
(注:此命令集群会自动选择为哪个主节点增加从节点,依据是判断哪个主节点副本少)
redis-trib.rb add-node --slave --master-id xxxxxxxxxxxxxxxnip:nport sip:sport
新增集群从节点,nip:nport为新节点,sip:sport为原集群中任一节点,只为标识往哪个集群中添加节点,xxxxx为主节点ID
redis-trib.rb del-node sip:sport xxxxxxxxxxx
删除集群节点, sip:sport为原集群中任一节点,只为标识往哪个集群中删除节点,xxxx为预删除的节点ID
redis-trib.rb reshard sip:sport
重新分片, sip:sport为原集群中任一节点,执行后系统会询问:
迁移多少桶:16384/4=4096
接受的节点ID: xxxxxxxxxxxx
重新分片的源节点: 某节点ID,或all(即从哪个节点上取4096,如从特定节点上取则指定节点ID,如填写all,则代表所有主节点均分)
附录2:集群客户端相关命令
cluster meetip:port
集群间相互握手,加入彼此所在的集群。(将指定节点加入到集群)
cluster nodes
获取集群间节点信息的列表,如下所示,格式为<node ID> <node IP:PORT><node role> [master node ID|-] <node ping_sent> <nodepong_received> <node epoch> <node status>。
127.0.0.1:6379> cluster nodes
a15705fdb7cac60e07ff699bf4c514e80f245a2c10.180.157.205:6379 slave 2b5603326d0fca28031467727fae4558115a99d8 01450854214289 11 connected
6477541e4594e60e095c8f44088263623654593610.180.157.202:6379 slave 9b35a393fa6623887215023b761d531dde452d3c 01450854211276 12 connected
ecf9ae60e87ea3358d9c5f1f269e0ed9a387ea4010.180.157.201:6379 master - 0 1450854214788 5 connected 10923-16383
2b5603326d0fca28031467727fae4558115a99d810.180.157.200:6379 master - 0 1450854213283 11 connected 5461-10922
f31f6ce49b3a2f3a246b2d97349c8f8614cf3a2c10.180.157.208:6379 slave ecf9ae60e87ea3358d9c5f1f269e0ed9a387ea40 01450854212286 9 connected
9b35a393fa6623887215023b761d531dde452d3c10.180.157.199:6379 myself,master - 0 0 12 connected 0-5460
cluster myid
返回节点的id。
127.0.0.1:6379> cluster myid
"9b35a393fa6623887215023b761d531dde452d3c"
cluster slots
返回集群间节点负责的数据分布表。
127.0.0.1:6379> cluster slots
1) 1) (integer) 10923
2) (integer) 16383
3) 1) "10.180.157.201"
2) (integer) 6379
4) 1) "10.180.157.208"
2) (integer) 6379
2) 1) (integer) 5461
2) (integer) 10922
3) 1) "10.180.157.200"
2) (integer) 6379
4) 1) "10.180.157.205"
2) (integer) 6379
3) 1) (integer) 0
2) (integer) 5460
3) 1) "10.180.157.199"
2) (integer) 6379
4) 1) "10.180.157.202"
2) (integer) 6379
clusterflushslots
清空该节点负责slots,必须在节点负责的这些slot都没有数据的情况下才能执行,该命令需要谨慎使用,由于之前说的bitmapTestBit方法,redis只比较负责的节点,清空的slots信息无法被其他节点同步。
cluster addslots[slot]
在当前节点上增加slot。(将指定的一个或多个slot
指派给当前节点)
cluster delslots[slot]
在节点上取消slot的负责。这也会导致前面说的slot信息无法同步,而且一旦集群有slot不负责,配置cluster-require-full-coverage为yes的话,该节点就无法提供服务了,所以使用也需谨慎。
cluster setslot<slot> MIGRATING <nodeid>
把本节点负责的某个slot设置为迁移到目的节点。(即将本节点的slot指派给或叫迁移到指定的节点)
cluster setslot<slot> IMPORTING <nodeid>
设置某个slot为从迁移源节点迁移标志。(即将指定节点的slot指派给或叫迁移到本节点)
cluster setslot<slot> STABLE
设置某个slot为从迁移状态恢复为正常状态。(取消slot的导入(importing)或迁移(migrating))
cluster setslot<slot> NODE <nodeid>
设置某个slot为某节点负责。该命令使用也需要注意,cluster setslot的四个命令需要配置迁移工具使用,单独使用容易引起集群混乱。该命令在集群出现异常时,需要指定某个slot为某个节点负责时,最好在每个节点上都执行一遍,至少要在迁移的节点和最高epoch的节点上执行成功。(将指定的slot指派给指定的节点,如果该slot已经指派给另一个节点,则要另一个节点先删除该slot)
cluster info
集群的一些info信息。
127.0.0.1:6379> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:12
cluster_my_epoch:12
cluster_stats_messages_sent:1449982
cluster_stats_messages_received:1182698
clustersaveconfig
保存集群的配置文件,集群默认在配置修改的时候会自动保存配置文件,该方法也能手动执行命令保存。
cluster keyslot
可以查询某个key对应的slot地址。
127.0.0.1:6379> cluster keyslot key
(integer) 12539
clustercountkeysinslot
可以查询该节点负责的某个slot内部key的数量。
127.0.0.1:6379> cluster countkeysinslot 13252
(integer) 2
clustergetkeysinslot <slot> <count>
可以查询该节点负责的某个slot内部指定数量的key列表。
127.0.0.1:6379> cluster getkeysinslot 1325210
1) "key0"
2) "key2298"
cluster forget
把某个节点加入黑名单,这样就无法完成握手。黑名单的过期时为60s,60s后两节点又会继续完成握手。
clusterreplicate <nodeid>
负责某个节点,成为它的slave。(将当前节点设置为指定nodeid节点的从节点)
cluster slaves
列出某个节点slave列表。
127.0.0.1:6379> cluster slaves2b5603326d0fca28031467727fae4558115a99d8
1)"a15705fdb7cac60e07ff699bf4c514e80f245a2c 10.180.157.205:6379 slave2b5603326d0fca28031467727fae4558115a99d8 0 1450854932667 11 connected"
clustercount-failure-reports
列出某个节点的故障转移记录的长度。
cluster failover[FORCE|TAKEOVER]
手动执行故障转移。
cluster set-config-epoch
设置节点epoch,只有在节点加入集群前才能设置。
cluster reset [SOFT|HARD]
重置集群信息,soft是清空其他节点的信息,但不修改自己的id。hard还会修改自己的id。不传该参数则使用soft方式。
readonly
在slave上执行,执行该命令后,可以在slave上执行只读命令。
readwrite
在slave上执行,执行该命令后,取消在slave上执行只读命令。
- 点赞
- 收藏
- 分享
- 文章举报
 蓝色雨林
发布了1 篇原创文章 · 获赞 0 · 访问量 176
私信
关注
蓝色雨林
发布了1 篇原创文章 · 获赞 0 · 访问量 176
私信
关注

- 两台Centos 7 部署Redis-cluster集群 超级详细
- redis演练(9) redis Cluster 集群快速部署&failover情况
- redis3.0.7 cluster 集群部署
- redis 3.0.7 cluster 集群部署
- redis集群部署(redis-cluster)
- centos7 64bit redis 单机 与 redis cluster 集群 配置 ,在阿里云ecs部署, 并本地连接
- Windos Docker Redis cluster 集群部署(linux一样)
- 分布式缓存集群方案特性使用场景(Memcache/Redis(Twemproxy/Codis/Redis-cluster))优缺点对比及选型
- Redis集群(2)-部署集群
- redis 集群部署(一)
- redis-cluster一台机器宕机后集群不可用
- redis3.0.0 集群环境部署
- Redis3缓存集群(cluster)搭建
- Centos 7 下 Mysql 5.7 Galera Cluster 集群部署
- Redis-3.2.0集群配置(redis cluster)
- 在windows上搭建redis集群(redis-cluster)
- CentOS搭建redis-cluster集群
- redis-Cluster第四篇集群的伸缩调优
- redis集群部署rvm安装问题
- MariaDB Galera Cluster 部署(mysql 集群部署)