redis演练(9) redis Cluster 集群快速部署&failover情况
2016-09-12 22:29
483 查看
<redis演练(8) redis Cluster 集群环境安装>,简单阐述了如何安装redis集群环境。
集群环境,主要包括2部分。
1.配置每个节点的配置信息(redis.conf),尤其开启cluster
2.创建集群
过程非常简单,但非常繁琐,尤其配置各个集群节点的配置信息,如果有一定数量,工作量也不小。
没关系,redis提供了一款cluster工具,能快速构造集群环境。本章的主要内容是介绍redis提供的集群工具。
1.使用create-cluster工具,快速创建集群
该工具在redis-unstable源码中。具体位置:${redis-unstable_dir}/utils/create-cluster。
<redis演练(8) redis Cluster 集群环境安装> 演示了如何创建3主集群环境。这次使用create-cluster工具,快速构造一个6节点,3主3从集群环境。过程更快更简单。
1.1认识create-cluster
1.2 启动
上面信息,整理成图如下
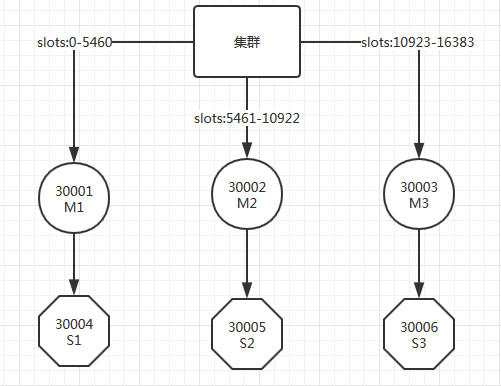
./create-cluster start命令指定的参数
../../src/redis-server
--port $PORT
--cluster-enabled yes
--cluster-config-file nodes-${PORT}.conf
--cluster-node-timeout $TIMEOUT
--appendonly yes
--appendfilename appendonly-${PORT}.aof
--dbfilename dump-${PORT}.rdb
--logfile ${PORT}.log --daemonize yes
1.3 集群创建了之后,watch查看下
[root@hadoop2 create-cluster]# ./create-cluster watch
watch命令,一秒监控一次。
节点信息格式
见http://redis.io/commands/cluster-nodes

通过上面配置,可以清楚了解主备情况。
2.认识若干Cluster管理命令
3.演示节点fail-over情况
127.0.0.1:30001> cluster nodes
6ca5cc8273f06880f63ea8ef9ef0f26ee68677f8 127.0.0.1:30004@40004 slave 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 0 1473688179624 4 connected
c47d9b24c51eea56723ebf40b5dd7bb627a0d92d 127.0.0.1:30005@40005 slave 29cc0b04ce1485f2d73d36c204530b38c69db463 0 1473688179624 5 connected
8c8c363fed795d56b319640ca696e74fbbbd3c77 127.0.0.1:30003@40003 master,fail - 1473688174327 1473688173499 3 disconnected
29cc0b04ce1485f2d73d36c204530b38c69db463 127.0.0.1:30002@40002 master - 0 1473688179624 2 connected 5461-10922
e16c5b58943ed11dda1a90e5cacb10f42f4fcc53 127.0.0.1:30006@40006 master - 0 1473688179624 7 connected 10923-16383
7556689b3dacc00ee31cb82bb4a3a0fcda39db75 127.0.0.1:30001@40001 myself,master - 0 0 1 connected 0-5460
发生了主备切换。
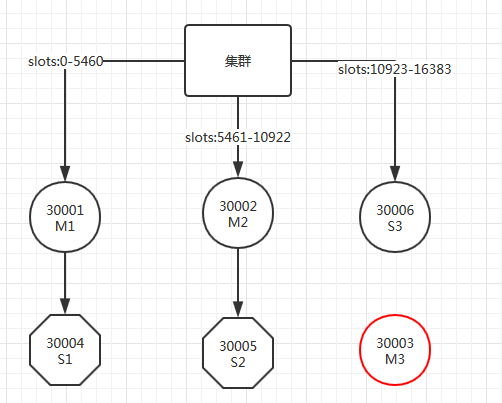
实验证明:集群环境下,如果某个节点宕掉,可以正常发生主备切换,集群正常使用。
演示主备节点都宕掉的情况
模拟30006节点宕掉
现在陆续恢复,30006,30003节点
如果发现 error MOVED,可能是因为客户端没有开启cluster模式。
错误描述如下
127.0.0.1:30001> set title3 "3"
(error) MOVED 9980 127.0.0.1:30002
集群环境,主要包括2部分。
1.配置每个节点的配置信息(redis.conf),尤其开启cluster
2.创建集群
redis-trib
.rb创建集群。
过程非常简单,但非常繁琐,尤其配置各个集群节点的配置信息,如果有一定数量,工作量也不小。
没关系,redis提供了一款cluster工具,能快速构造集群环境。本章的主要内容是介绍redis提供的集群工具。
1.使用create-cluster工具,快速创建集群
该工具在redis-unstable源码中。具体位置:${redis-unstable_dir}/utils/create-cluster。
<redis演练(8) redis Cluster 集群环境安装> 演示了如何创建3主集群环境。这次使用create-cluster工具,快速构造一个6节点,3主3从集群环境。过程更快更简单。
1.1认识create-cluster
[root@hadoop2 create-cluster]# ./create-cluster -help Usage: ./create-cluster [start|create|stop|watch|tail|clean] start -- Launch Redis Cluster instances. create -- Create a cluster using redis-trib create. stop -- Stop Redis Cluster instances. watch -- Show CLUSTER NODES output (first 30 lines) of first node. tail <id> -- Run tail -f of instance at base port + ID. clean -- Remove all instances data, logs, configs.
1.2 启动
[root@hadoop2 create-cluster]# ps -ef |grep redis root 3912 2444 0 10:40 pts/0 00:00:00 grep redis #先执行start,启动6个节点 [root@hadoop2 create-cluster]# ./create-cluster start Starting 30001 Starting 30002 Starting 30003 Starting 30004 Starting 30005 Starting 30006 #确认下 [root@hadoop2 create-cluster]# ps -ef |grep redis root 5189 1 0 13:58 ? 00:00:00 ../../src/redis-server *:30001 [cluster] root 5191 1 0 13:58 ? 00:00:00 ../../src/redis-server *:30002 [cluster] root 5193 1 0 13:58 ? 00:00:00 ../../src/redis-server *:30003 [cluster] root 5201 1 0 13:58 ? 00:00:00 ../../src/redis-server *:30004 [cluster] root 5206 1 0 13:58 ? 00:00:00 ../../src/redis-server *:30005 [cluster] root 5208 1 0 13:58 ? 00:00:00 ../../src/redis-server *:30006 [cluster] root 5235 2444 0 13:59 pts/0 00:00:00 grep redis #6节点纳入集群管理 [root@hadoop2 create-cluster]# ./create-cluster create >>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 127.0.0.1:30001 127.0.0.1:30002 127.0.0.1:30003 Adding replica 127.0.0.1:30004 to 127.0.0.1:30001 Adding replica 127.0.0.1:30005 to 127.0.0.1:30002 Adding replica 127.0.0.1:30006 to 127.0.0.1:30003 M: 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 127.0.0.1:30001 slots:0-5460 (5461 slots) master M: 29cc0b04ce1485f2d73d36c204530b38c69db463 127.0.0.1:30002 slots:5461-10922 (5462 slots) master M: 8c8c363fed795d56b319640ca696e74fbbbd3c77 127.0.0.1:30003 slots:10923-16383 (5461 slots) master S: 6ca5cc8273f06880f63ea8ef9ef0f26ee68677f8 127.0.0.1:30004 replicates 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 S: c47d9b24c51eea56723ebf40b5dd7bb627a0d92d 127.0.0.1:30005 replicates 29cc0b04ce1485f2d73d36c204530b38c69db463 S: e16c5b58943ed11dda1a90e5cacb10f42f4fcc53 127.0.0.1:30006 replicates 8c8c363fed795d56b319640ca696e74fbbbd3c77 Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join.. >>> Performing Cluster Check (using node 127.0.0.1:30001) M: 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 127.0.0.1:30001 slots:0-5460 (5461 slots) master 1 additional replica(s) S: 6ca5cc8273f06880f63ea8ef9ef0f26ee68677f8 127.0.0.1:30004 slots: (0 slots) slave replicates 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 S: c47d9b24c51eea56723ebf40b5dd7bb627a0d92d 127.0.0.1:30005 slots: (0 slots) slave replicates 29cc0b04ce1485f2d73d36c204530b38c69db463 M: 8c8c363fed795d56b319640ca696e74fbbbd3c77 127.0.0.1:30003 slots:10923-16383 (5461 slots) master 1 additional replica(s) M: 29cc0b04ce1485f2d73d36c204530b38c69db463 127.0.0.1:30002 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: e16c5b58943ed11dda1a90e5cacb10f42f4fcc53 127.0.0.1:30006 slots: (0 slots) slave replicates 8c8c363fed795d56b319640ca696e74fbbbd3c77 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.看到了" All 16384 slots covered.",说明创建成功了。
上面信息,整理成图如下
./create-cluster start命令指定的参数
../../src/redis-server
--port $PORT
--cluster-enabled yes
--cluster-config-file nodes-${PORT}.conf
--cluster-node-timeout $TIMEOUT
--appendonly yes
--appendfilename appendonly-${PORT}.aof
--dbfilename dump-${PORT}.rdb
--logfile ${PORT}.log --daemonize yes
1.3 集群创建了之后,watch查看下
[root@hadoop2 create-cluster]# ./create-cluster watch
watch命令,一秒监控一次。
节点信息格式
见http://redis.io/commands/cluster-nodes
通过上面配置,可以清楚了解主备情况。
2.认识若干Cluster管理命令
| cluster addslots slot [slot ...] | 这个命令是用于修改某个节点上的集群配置 | 例如以下命令分配 1 2 3 slot到接收命令的节点:> CLUSTER ADDSLOTS 1 2 3 OK |
| cluster countkeysinslot slot | 返回连接节点负责的指定hash slot的key的数量 | > CLUSTER COUNTKEYSINSLOT 7000 (integer) 50341 |
| cluster slots | slot分布情况 | 127.0.0.1:7001> cluster slots |
| cluster info | INFO | 127.0.0.1:30001> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:1 cluster_stats_messages_sent:40250 cluster_stats_messages_received:40250 |
| cluster keyslot | key对应的哈希槽 | 127.0.0.1:30002> cluster keyslot title (integer) 2217 |
| cluster meet | 不知道什么用, 输入任意IP和端口,都返回true | |
| cluster nodes | 节点信息 | ./create-cluster watch命令,就是调用该命令 |
| cluster replicate node-id | 配置一个节点为slave | |
| cluster reset [hard|soft] | ||
| cluster saveconfig | 强制保存信息到nodes.conf | |
| cluster setslot slot importing|migrating|stable|node [node-id] | ||
| CLUSTER SLAVES node-id | 节点的备节点信息 | |
| READONLY | ||
| READWRITE | ||
| CLUSTER FORGET node-id |
[root@hadoop2 create-cluster]# ps -ef |grep redis root 2424 1 0 21:41 ? 00:00:00 ../../src/redis-server *:30001 [cluster] root 2426 1 0 21:41 ? 00:00:00 ../../src/redis-server *:30002 [cluster] root 2428 1 0 21:41 ? 00:00:00 ../../src/redis-server *:30003 [cluster] root 2430 1 0 21:41 ? 00:00:00 ../../src/redis-server *:30004 [cluster] root 2441 1 0 21:41 ? 00:00:00 ../../src/redis-server *:30005 [cluster] root 2446 1 0 21:41 ? 00:00:00 ../../src/redis-server *:30006 [cluster] 模拟关闭 30003 Master节点 [root@hadoop2 create-cluster]# kill -9 2428监控nodes信息
127.0.0.1:30001> cluster nodes
6ca5cc8273f06880f63ea8ef9ef0f26ee68677f8 127.0.0.1:30004@40004 slave 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 0 1473688179624 4 connected
c47d9b24c51eea56723ebf40b5dd7bb627a0d92d 127.0.0.1:30005@40005 slave 29cc0b04ce1485f2d73d36c204530b38c69db463 0 1473688179624 5 connected
8c8c363fed795d56b319640ca696e74fbbbd3c77 127.0.0.1:30003@40003 master,fail - 1473688174327 1473688173499 3 disconnected
29cc0b04ce1485f2d73d36c204530b38c69db463 127.0.0.1:30002@40002 master - 0 1473688179624 2 connected 5461-10922
e16c5b58943ed11dda1a90e5cacb10f42f4fcc53 127.0.0.1:30006@40006 master - 0 1473688179624 7 connected 10923-16383
7556689b3dacc00ee31cb82bb4a3a0fcda39db75 127.0.0.1:30001@40001 myself,master - 0 0 1 connected 0-5460
发生了主备切换。
实验证明:集群环境下,如果某个节点宕掉,可以正常发生主备切换,集群正常使用。
演示主备节点都宕掉的情况
模拟30006节点宕掉
[root@hadoop2 create-cluster]# kill -9 2446 [root@hadoop2 create-cluster]# /usr/local/redis/bin/redis-cli -c -p 30002 127.0.0.1:30002> get title (error) CLUSTERDOWN The cluster is down集群环境不可用。
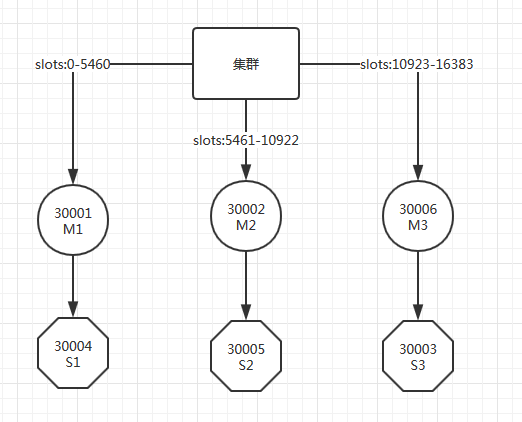
现在陆续恢复,30006,30003节点
#恢复启动30006节点 [root@hadoop2 create-cluster]# ../../src/redis-server --port 30006 --cluster-enabled yes --cluster-config-file nodes-30006.conf --cluster-node-timeout 5000 --appendonly yes --appendfilename appendonly-30006.aof --dbfilename dump-30006.rdb --logfile 30006.log --daemonize yes #集群恢复正常工作。 127.0.0.1:30002> get title -> Redirected to slot [2217] located at 127.0.0.1:30001 "1" 127.0.0.1:30001> cluster nodes 6ca5cc8273f06880f63ea8ef9ef0f26ee68677f8 127.0.0.1:30004@40004 slave 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 0 1473689972166 4 connected c47d9b24c51eea56723ebf40b5dd7bb627a0d92d 127.0.0.1:30005@40005 slave 29cc0b04ce1485f2d73d36c204530b38c69db463 0 1473689972166 5 connected 8c8c363fed795d56b319640ca696e74fbbbd3c77 127.0.0.1:30003@40003 master,fail - 1473688174327 1473688173499 3 disconnected 29cc0b04ce1485f2d73d36c204530b38c69db463 127.0.0.1:30002@40002 master - 0 1473689972166 2 connected 5461-10922 e16c5b58943ed11dda1a90e5cacb10f42f4fcc53 127.0.0.1:30006@40006 master - 0 1473689972166 7 connected 10923-16383 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 127.0.0.1:30001@40001 myself,master - 0 0 1 connected 0-5460 # 恢复启动30003节点 [root@hadoop2 create-cluster]# ../../src/redis-server --port 30003 --cluster-enabled yes --cluster-config-file nodes-30003.conf --cluster-node-timeout 5000 --appendonly yes --appendfilename appendonly-30003.aof --dbfilename dump-30003.rdb --logfile 30003.log --daemonize yes # 30003不再被恢复成主节点 127.0.0.1:30001> cluster nodes 6ca5cc8273f06880f63ea8ef9ef0f26ee68677f8 127.0.0.1:30004@40004 slave 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 0 1473690034497 4 connected c47d9b24c51eea56723ebf40b5dd7bb627a0d92d 127.0.0.1:30005@40005 slave 29cc0b04ce1485f2d73d36c204530b38c69db463 0 1473690034497 5 connected 8c8c363fed795d56b319640ca696e74fbbbd3c77 127.0.0.1:30003@40003 slave e16c5b58943ed11dda1a90e5cacb10f42f4fcc53 0 1473690034497 7 connected 29cc0b04ce1485f2d73d36c204530b38c69db463 127.0.0.1:30002@40002 master - 0 1473690034497 2 connected 5461-10922 e16c5b58943ed11dda1a90e5cacb10f42f4fcc53 127.0.0.1:30006@40006 master - 0 1473690034497 7 connected 10923-16383 7556689b3dacc00ee31cb82bb4a3a0fcda39db75 127.0.0.1:30001@40001 myself,master - 0 0 1 connected 0-5460具体集群概括如图
如果发现 error MOVED,可能是因为客户端没有开启cluster模式。
错误描述如下
127.0.0.1:30001> set title3 "3"
(error) MOVED 9980 127.0.0.1:30002

相关文章推荐
- Pedis: NoSQL data store using the SEASTAR framework, compatible with Redis
- redis安装问题小结
- Rabbitmq集群搭建笔记
- RH436 Day1 课后总结
- RH436 Day2 课后总结
- 使用 Redis 和 Python 构建一个共享单车的应用程序
- Redis偶发连接失败案例实战记录
- Redis中实现查找某个值的范围
- win 7 安装redis服务【笔记】
- redis的hGetAll函数的性能问题(记Redis那坑人的HGETALL)
- Redis和Memcached的区别详解
- Redis02 使用Redis数据库(String类型)全面解析
- 分割超大Redis数据库例子
- Redis总结笔记(一):安装和常用命令
- Redis sort 排序命令详解
- 用Redis实现微博关注关系
- Redis实现信息已读未读状态提示
- redis中修改配置文件中的端口号 密码方法
- 在Ruby on Rails上使用Redis Store的方法
- MySQL Cluster如何创建磁盘表方法解读